 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapTrace: Scalable Data Generation for Route Tracing on Maps
Dec 22, 2025While Multimodal Large Language Models have achieved human-like performance on many visual and textual reasoning tasks, their proficiency in fine-grained spatial understanding, such as route tracing on maps remains limited. Unlike humans, who can quickly learn to parse and navigate maps, current models often fail to respect fundamental path constraints, in part due to the prohibitive cost and difficulty of collecting large-scale, pixel-accurate path annotations. To address this, we introduce a scalable synthetic data generation pipeline that leverages synthetic map images and pixel-level parsing to automatically produce precise annotations for this challenging task. Using this pipeline, we construct a fine-tuning dataset of 23k path samples across 4k maps, enabling models to acquire more human-like spatial capabilities. Using this dataset, we fine-tune both open-source and proprietary MLLMs. Results on MapBench show that finetuning substantially improves robustness, raising success rates by up to 6.4 points, while also reducing path-tracing error (NDTW). These gains highlight that fine-grained spatial reasoning, absent in pretrained models, can be explicitly taught with synthetic supervision.
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
Apr 01, 2022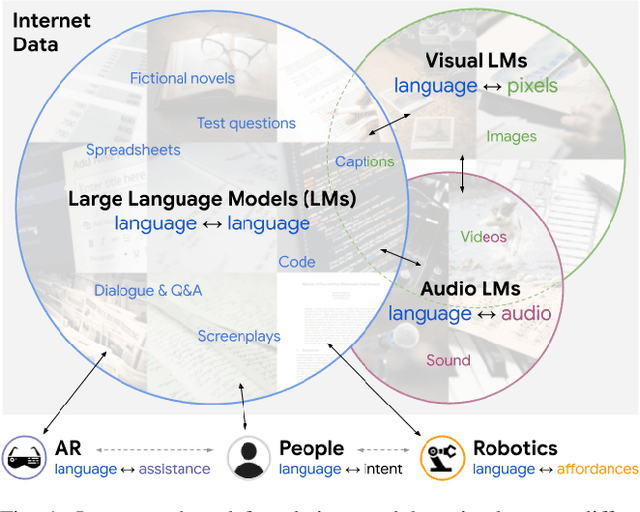
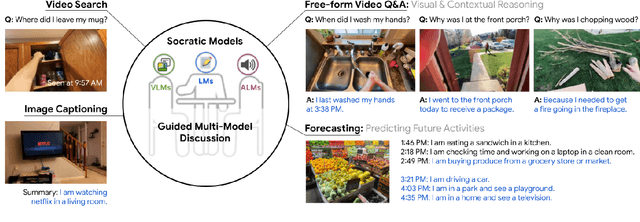
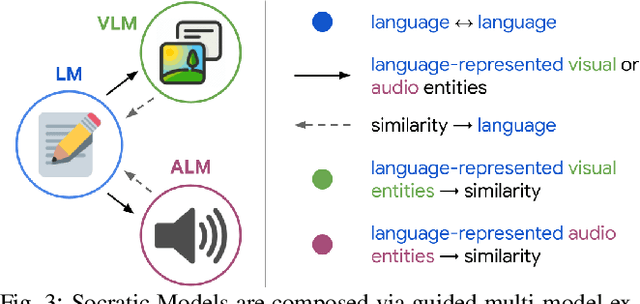
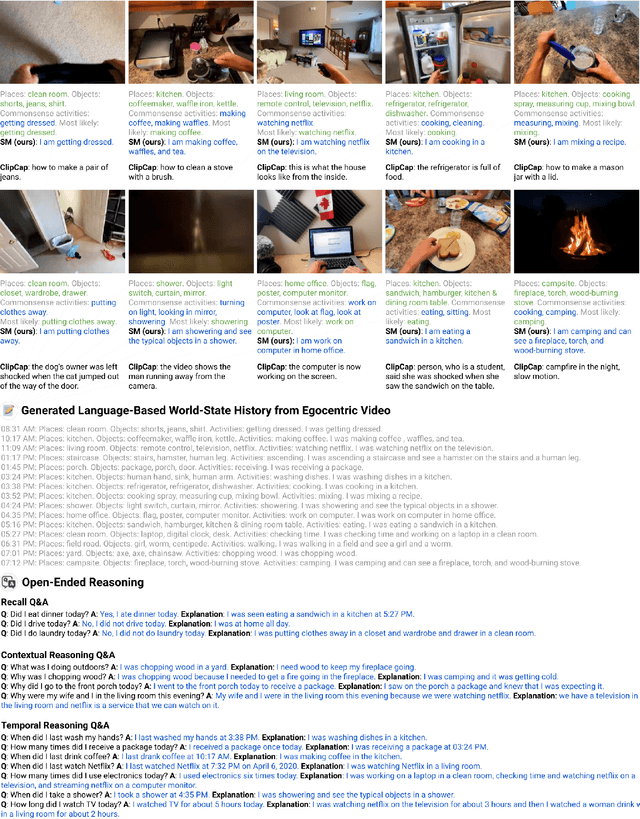
Large foundation models can exhibit unique capabilities depending on the domain of data they are trained on. While these domains are generic, they may only barely overlap. For example, visual-language models (VLMs) are trained on Internet-scale image captions, but large language models (LMs) are further trained on Internet-scale text with no images (e.g. from spreadsheets, to SAT questions). As a result, these models store different forms of commonsense knowledge across different domains. In this work, we show that this model diversity is symbiotic, and can be leveraged to build AI systems with structured Socratic dialogue -- in which new multimodal tasks are formulated as a guided language-based exchange between different pre-existing foundation models, without additional finetuning. In the context of egocentric perception, we present a case study of Socratic Models (SMs) that can provide meaningful results for complex tasks such as generating free-form answers to contextual questions about egocentric video, by formulating video Q&A as short story Q&A, i.e. summarizing the video into a short story, then answering questions about it. Additionally, SMs can generate captions for Internet images, and are competitive with state-of-the-art on zero-shot video-to-text retrieval with 42.8 R@1 on MSR-VTT 1k-A. SMs demonstrate how to compose foundation models zero-shot to capture new multimodal functionalities, without domain-specific data collection. Prototypes are available at socraticmodels.github.io.