 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Reconstructing Dynamic Scenes One D4RT at a Time
Dec 10, 2025



Understanding and reconstructing the complex geometry and motion of dynamic scenes from video remains a formidable challenge in computer vision. This paper introduces D4RT, a simple yet powerful feedforward model designed to efficiently solve this task. D4RT utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and full camera parameters from a single video. Its core innovation is a novel querying mechanism that sidesteps the heavy computation of dense, per-frame decoding and the complexity of managing multiple, task-specific decoders. Our decoding interface allows the model to independently and flexibly probe the 3D position of any point in space and time. The result is a lightweight and highly scalable method that enables remarkably efficient training and inference. We demonstrate that our approach sets a new state of the art, outperforming previous methods across a wide spectrum of 4D reconstruction tasks. We refer to the project webpage for animated results: https://d4rt-paper.github.io/.
Robot Learning from a Physical World Model
Nov 10, 2025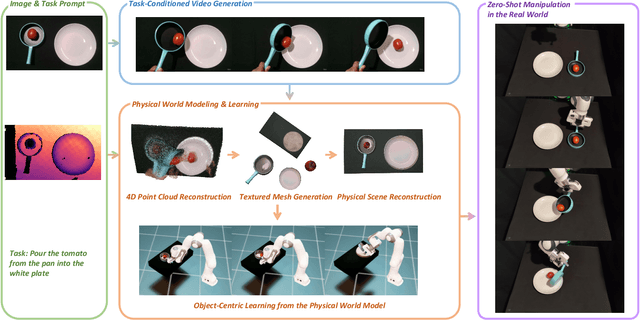

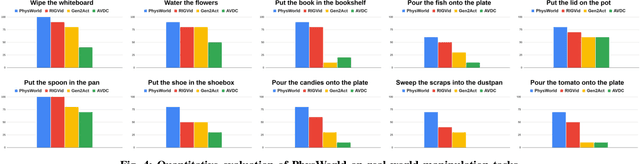

We introduce PhysWorld, a framework that enables robot learning from video generation through physical world modeling. Recent video generation models can synthesize photorealistic visual demonstrations from language commands and images, offering a powerful yet underexplored source of training signals for robotics. However, directly retargeting pixel motions from generated videos to robots neglects physics, often resulting in inaccurate manipulations. PhysWorld addresses this limitation by coupling video generation with physical world reconstruction. Given a single image and a task command, our method generates task-conditioned videos and reconstructs the underlying physical world from the videos, and the generated video motions are grounded into physically accurate actions through object-centric residual reinforcement learning with the physical world model. This synergy transforms implicit visual guidance into physically executable robotic trajectories, eliminating the need for real robot data collection and enabling zero-shot generalizable robotic manipulation. Experiments on diverse real-world tasks demonstrate that PhysWorld substantially improves manipulation accuracy compared to previous approaches. Visit \href{https://pointscoder.github.io/PhysWorld_Web/}{the project webpage} for details.
CyberV: Cybernetics for Test-time Scaling in Video Understanding
Jun 09, 2025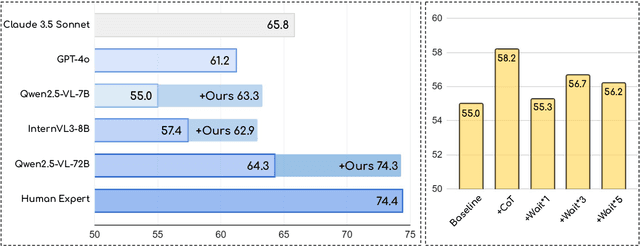
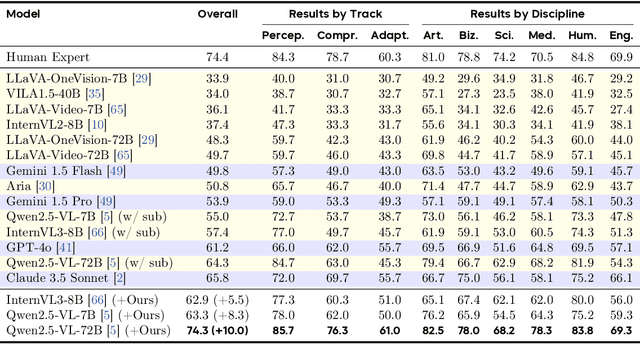
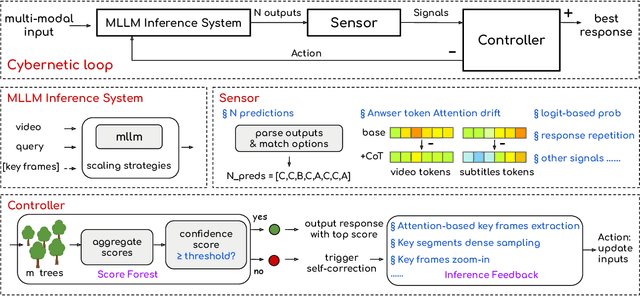
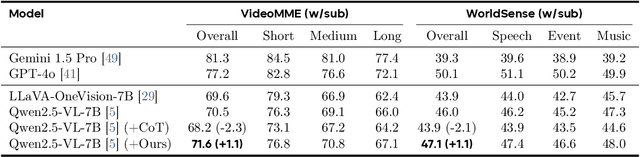
Current Multimodal Large Language Models (MLLMs) may struggle with understanding long or complex videos due to computational demands at test time, lack of robustness, and limited accuracy, primarily stemming from their feed-forward processing nature. These limitations could be more severe for models with fewer parameters. To address these limitations, we propose a novel framework inspired by cybernetic principles, redesigning video MLLMs as adaptive systems capable of self-monitoring, self-correction, and dynamic resource allocation during inference. Our approach, CyberV, introduces a cybernetic loop consisting of an MLLM Inference System, a Sensor, and a Controller. Specifically, the sensor monitors forward processes of the MLLM and collects intermediate interpretations, such as attention drift, then the controller determines when and how to trigger self-correction and generate feedback to guide the next round. This test-time adaptive scaling framework enhances frozen MLLMs without requiring retraining or additional components. Experiments demonstrate significant improvements: CyberV boosts Qwen2.5-VL-7B by 8.3% and InternVL3-8B by 5.5% on VideoMMMU, surpassing the competitive proprietary model GPT-4o. When applied to Qwen2.5-VL-72B, it yields a 10.0% improvement, achieving performance even comparable to human experts. Furthermore, our method demonstrates consistent gains on general-purpose benchmarks, such as VideoMME and WorldSense, highlighting its effectiveness and generalization capabilities in making MLLMs more robust and accurate for dynamic video understanding. The code is released at https://github.com/marinero4972/CyberV.
Diffusion Models Need Visual Priors for Image Generation
Oct 11, 2024



Conventional class-guided diffusion models generally succeed in generating images with correct semantic content, but often struggle with texture details. This limitation stems from the usage of class priors, which only provide coarse and limited conditional information. To address this issue, we propose Diffusion on Diffusion (DoD), an innovative multi-stage generation framework that first extracts visual priors from previously generated samples, then provides rich guidance for the diffusion model leveraging visual priors from the early stages of diffusion sampling. Specifically, we introduce a latent embedding module that employs a compression-reconstruction approach to discard redundant detail information from the conditional samples in each stage, retaining only the semantic information for guidance. We evaluate DoD on the popular ImageNet-$256 \times 256$ dataset, reducing 7$\times$ training cost compared to SiT and DiT with even better performance in terms of the FID-50K score. Our largest model DoD-XL achieves an FID-50K score of 1.83 with only 1 million training steps, which surpasses other state-of-the-art methods without bells and whistles during inference.
DreamBeast: Distilling 3D Fantastical Animals with Part-Aware Knowledge Transfer
Sep 12, 2024



We present DreamBeast, a novel method based on score distillation sampling (SDS) for generating fantastical 3D animal assets composed of distinct parts. Existing SDS methods often struggle with this generation task due to a limited understanding of part-level semantics in text-to-image diffusion models. While recent diffusion models, such as Stable Diffusion 3, demonstrate a better part-level understanding, they are prohibitively slow and exhibit other common problems associated with single-view diffusion models. DreamBeast overcomes this limitation through a novel part-aware knowledge transfer mechanism. For each generated asset, we efficiently extract part-level knowledge from the Stable Diffusion 3 model into a 3D Part-Affinity implicit representation. This enables us to instantly generate Part-Affinity maps from arbitrary camera views, which we then use to modulate the guidance of a multi-view diffusion model during SDS to create 3D assets of fantastical animals. DreamBeast significantly enhances the quality of generated 3D creatures with user-specified part compositions while reducing computational overhead, as demonstrated by extensive quantitative and qualitative evaluations.
kNN-CLIP: Retrieval Enables Training-Free Segmentation on Continually Expanding Large Vocabularies
Apr 15, 2024



Rapid advancements in continual segmentation have yet to bridge the gap of scaling to large continually expanding vocabularies under compute-constrained scenarios. We discover that traditional continual training leads to catastrophic forgetting under compute constraints, unable to outperform zero-shot segmentation methods. We introduce a novel strategy for semantic and panoptic segmentation with zero forgetting, capable of adapting to continually growing vocabularies without the need for retraining or large memory costs. Our training-free approach, kNN-CLIP, leverages a database of instance embeddings to enable open-vocabulary segmentation approaches to continually expand their vocabulary on any given domain with a single-pass through data, while only storing embeddings minimizing both compute and memory costs. This method achieves state-of-the-art mIoU performance across large-vocabulary semantic and panoptic segmentation datasets. We hope kNN-CLIP represents a step forward in enabling more efficient and adaptable continual segmentation, paving the way for advances in real-world large-vocabulary continual segmentation methods.
SynArtifact: Classifying and Alleviating Artifacts in Synthetic Images via Vision-Language Model
Mar 05, 2024



In the rapidly evolving area of image synthesis, a serious challenge is the presence of complex artifacts that compromise perceptual realism of synthetic images. To alleviate artifacts and improve quality of synthetic images, we fine-tune Vision-Language Model (VLM) as artifact classifier to automatically identify and classify a wide range of artifacts and provide supervision for further optimizing generative models. Specifically, we develop a comprehensive artifact taxonomy and construct a dataset of synthetic images with artifact annotations for fine-tuning VLM, named SynArtifact-1K. The fine-tuned VLM exhibits superior ability of identifying artifacts and outperforms the baseline by 25.66%. To our knowledge, this is the first time such end-to-end artifact classification task and solution have been proposed. Finally, we leverage the output of VLM as feedback to refine the generative model for alleviating artifacts. Visualization results and user study demonstrate that the quality of images synthesized by the refined diffusion model has been obviously improved.
RAG-Driver: Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model
Feb 16, 2024



Robots powered by 'blackbox' models need to provide human-understandable explanations which we can trust. Hence, explainability plays a critical role in trustworthy autonomous decision-making to foster transparency and acceptance among end users, especially in complex autonomous driving. Recent advancements in Multi-Modal Large Language models (MLLMs) have shown promising potential in enhancing the explainability as a driving agent by producing control predictions along with natural language explanations. However, severe data scarcity due to expensive annotation costs and significant domain gaps between different datasets makes the development of a robust and generalisable system an extremely challenging task. Moreover, the prohibitively expensive training requirements of MLLM and the unsolved problem of catastrophic forgetting further limit their generalisability post-deployment. To address these challenges, we present RAG-Driver, a novel retrieval-augmented multi-modal large language model that leverages in-context learning for high-performance, explainable, and generalisable autonomous driving. By grounding in retrieved expert demonstration, we empirically validate that RAG-Driver achieves state-of-the-art performance in producing driving action explanations, justifications, and control signal prediction. More importantly, it exhibits exceptional zero-shot generalisation capabilities to unseen environments without further training endeavours.
CLIP as RNN: Segment Countless Visual Concepts without Training Endeavor
Dec 21, 2023



Existing open-vocabulary image segmentation methods require a fine-tuning step on mask annotations and/or image-text datasets. Mask labels are labor-intensive, which limits the number of categories in segmentation datasets. As a result, the open-vocabulary capacity of pre-trained VLMs is severely reduced after fine-tuning. However, without fine-tuning, VLMs trained under weak image-text supervision tend to make suboptimal mask predictions when there are text queries referring to non-existing concepts in the image. To alleviate these issues, we introduce a novel recurrent framework that progressively filters out irrelevant texts and enhances mask quality without training efforts. The recurrent unit is a two-stage segmenter built upon a VLM with frozen weights. Thus, our model retains the VLM's broad vocabulary space and strengthens its segmentation capability. Experimental results show that our method outperforms not only the training-free counterparts, but also those fine-tuned with millions of additional data samples, and sets new state-of-the-art records for both zero-shot semantic and referring image segmentation tasks. Specifically, we improve the current record by 28.8, 16.0, and 6.9 mIoU on Pascal VOC, COCO Object, and Pascal Context.
Real-Fake: Effective Training Data Synthesis Through Distribution Matching
Oct 16, 2023



Synthetic training data has gained prominence in numerous learning tasks and scenarios, offering advantages such as dataset augmentation, generalization evaluation, and privacy preservation. Despite these benefits, the efficiency of synthetic data generated by current methodologies remains inferior when training advanced deep models exclusively, limiting its practical utility. To address this challenge, we analyze the principles underlying training data synthesis for supervised learning and elucidate a principled theoretical framework from the distribution-matching perspective that explicates the mechanisms governing synthesis efficacy. Through extensive experiments, we demonstrate the effectiveness of our synthetic data across diverse image classification tasks, both as a replacement for and augmentation to real datasets, while also benefits challenging tasks such as out-of-distribution generalization and privacy preservation.