 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEBench:Benchmarking Large Multimodal Models for Real-World Video Editing
May 05, 2026Real-world video editing demands not only expert knowledge of cinematic techniques but also multimodal reasoning to select, align, and combine footage into coherent narratives. While recent Large Multimodal Models (LMMs) have shown remarkable progress in general video understanding, their abilities in multi-video reasoning and operational editing workflows remain largely unexplored. We introduce VEBENCH, the first comprehensive benchmark designed to evaluate both editing knowledge understanding and operational reasoning in realistic video editing scenarios. VEBENCH contains 3.9K high-quality edited videos (over 257 hours) and 3,080 human-verified QA pairs, built through a three-round human-AI collaborative annotation pipeline that ensures precise temporal labeling and semantic consistency. It features two complementary QA tasks: 1) Video Editing Technique Recognition, assessing models' ability to identify 7 editing techniques using multimodal cues; and 2) Video Editing Operation Simulation, modeling real-world editing workflows by requiring the selection and temporal localization of relevant clips from multiple candidates. Extensive experiments across proprietary (e.g., Gemini-2.5-Pro) and open-source LMMs reveal a large gap between current model performance and human-level editing cognition. These results highlight the urgent need for bridging video understanding with creative operational reasoning. We envision VEBENCH as a foundation for advancing intelligent video editing systems and driving future research on complex reasoning.
Referring Layer Decomposition
Feb 22, 2026Precise, object-aware control over visual content is essential for advanced image editing and compositional generation. Yet, most existing approaches operate on entire images holistically, limiting the ability to isolate and manipulate individual scene elements. In contrast, layered representations, where scenes are explicitly separated into objects, environmental context, and visual effects, provide a more intuitive and structured framework for interpreting and editing visual content. To bridge this gap and enable both compositional understanding and controllable editing, we introduce the Referring Layer Decomposition (RLD) task, which predicts complete RGBA layers from a single RGB image, conditioned on flexible user prompts, such as spatial inputs (e.g., points, boxes, masks), natural language descriptions, or combinations thereof. At the core is the RefLade, a large-scale dataset comprising 1.11M image-layer-prompt triplets produced by our scalable data engine, along with 100K manually curated, high-fidelity layers. Coupled with a perceptually grounded, human-preference-aligned automatic evaluation protocol, RefLade establishes RLD as a well-defined and benchmarkable research task. Building on this foundation, we present RefLayer, a simple baseline designed for prompt-conditioned layer decomposition, achieving high visual fidelity and semantic alignment. Extensive experiments show our approach enables effective training, reliable evaluation, and high-quality image decomposition, while exhibiting strong zero-shot generalization capabilities.
EchoFoley: Event-Centric Hierarchical Control for Video Grounded Creative Sound Generation
Dec 31, 2025Sound effects build an essential layer of multimodal storytelling, shaping the emotional atmosphere and the narrative semantics of videos. Despite recent advancement in video-text-to-audio (VT2A), the current formulation faces three key limitations: First, an imbalance between visual and textual conditioning that leads to visual dominance; Second, the absence of a concrete definition for fine-grained controllable generation; Third, weak instruction understanding and following, as existing datasets rely on brief categorical tags. To address these limitations, we introduce EchoFoley, a new task designed for video-grounded sound generation with both event level local control and hierarchical semantic control. Our symbolic representation for sounding events specifies when, what, and how each sound is produced within a video or instruction, enabling fine-grained controls like sound generation, insertion, and editing. To support this task, we construct EchoFoley-6k, a large-scale, expert-curated benchmark containing over 6,000 video-instruction-annotation triplets. Building upon this foundation, we propose EchoVidia a sounding-event-centric agentic generation framework with slow-fast thinking strategy. Experiments show that EchoVidia surpasses recent VT2A models by 40.7% in controllability and 12.5% in perceptual quality.
CyberV: Cybernetics for Test-time Scaling in Video Understanding
Jun 09, 2025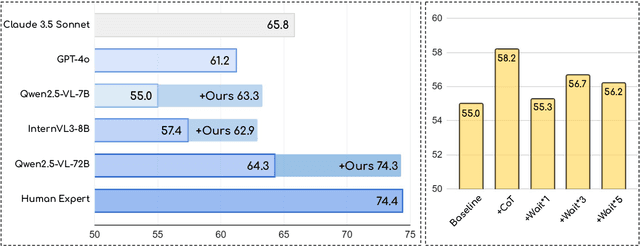
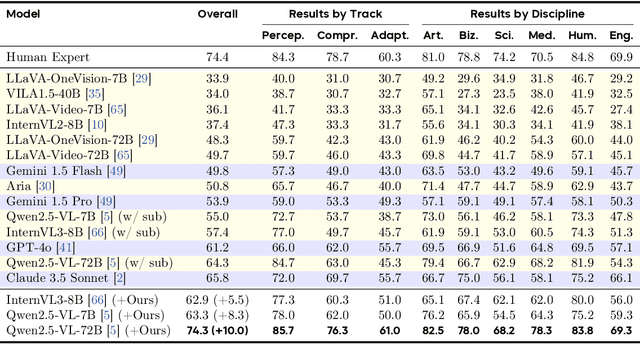
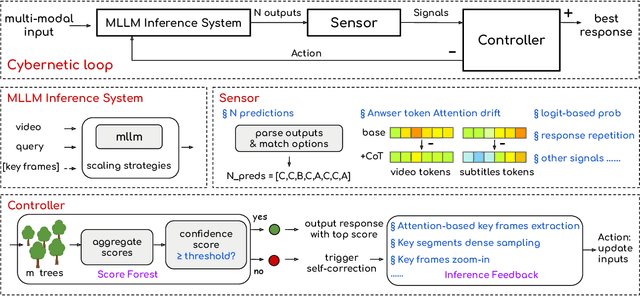
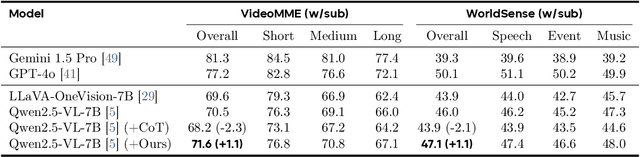
Current Multimodal Large Language Models (MLLMs) may struggle with understanding long or complex videos due to computational demands at test time, lack of robustness, and limited accuracy, primarily stemming from their feed-forward processing nature. These limitations could be more severe for models with fewer parameters. To address these limitations, we propose a novel framework inspired by cybernetic principles, redesigning video MLLMs as adaptive systems capable of self-monitoring, self-correction, and dynamic resource allocation during inference. Our approach, CyberV, introduces a cybernetic loop consisting of an MLLM Inference System, a Sensor, and a Controller. Specifically, the sensor monitors forward processes of the MLLM and collects intermediate interpretations, such as attention drift, then the controller determines when and how to trigger self-correction and generate feedback to guide the next round. This test-time adaptive scaling framework enhances frozen MLLMs without requiring retraining or additional components. Experiments demonstrate significant improvements: CyberV boosts Qwen2.5-VL-7B by 8.3% and InternVL3-8B by 5.5% on VideoMMMU, surpassing the competitive proprietary model GPT-4o. When applied to Qwen2.5-VL-72B, it yields a 10.0% improvement, achieving performance even comparable to human experts. Furthermore, our method demonstrates consistent gains on general-purpose benchmarks, such as VideoMME and WorldSense, highlighting its effectiveness and generalization capabilities in making MLLMs more robust and accurate for dynamic video understanding. The code is released at https://github.com/marinero4972/CyberV.
SuperEdit: Rectifying and Facilitating Supervision for Instruction-Based Image Editing
May 05, 2025Due to the challenges of manually collecting accurate editing data, existing datasets are typically constructed using various automated methods, leading to noisy supervision signals caused by the mismatch between editing instructions and original-edited image pairs. Recent efforts attempt to improve editing models through generating higher-quality edited images, pre-training on recognition tasks, or introducing vision-language models (VLMs) but fail to resolve this fundamental issue. In this paper, we offer a novel solution by constructing more effective editing instructions for given image pairs. This includes rectifying the editing instructions to better align with the original-edited image pairs and using contrastive editing instructions to further enhance their effectiveness. Specifically, we find that editing models exhibit specific generation attributes at different inference steps, independent of the text. Based on these prior attributes, we define a unified guide for VLMs to rectify editing instructions. However, there are some challenging editing scenarios that cannot be resolved solely with rectified instructions. To this end, we further construct contrastive supervision signals with positive and negative instructions and introduce them into the model training using triplet loss, thereby further facilitating supervision effectiveness. Our method does not require the VLM modules or pre-training tasks used in previous work, offering a more direct and efficient way to provide better supervision signals, and providing a novel, simple, and effective solution for instruction-based image editing. Results on multiple benchmarks demonstrate that our method significantly outperforms existing approaches. Compared with previous SOTA SmartEdit, we achieve 9.19% improvements on the Real-Edit benchmark with 30x less training data and 13x smaller model size.
Vidi: Large Multimodal Models for Video Understanding and Editing
Apr 22, 2025



Humans naturally share information with those they are connected to, and video has become one of the dominant mediums for communication and expression on the Internet. To support the creation of high-quality large-scale video content, a modern pipeline requires a comprehensive understanding of both the raw input materials (e.g., the unedited footage captured by cameras) and the editing components (e.g., visual effects). In video editing scenarios, models must process multiple modalities (e.g., vision, audio, text) with strong background knowledge and handle flexible input lengths (e.g., hour-long raw videos), which poses significant challenges for traditional models. In this report, we introduce Vidi, a family of Large Multimodal Models (LMMs) for a wide range of video understand editing scenarios. The first release focuses on temporal retrieval, i.e., identifying the time ranges within the input videos corresponding to a given text query, which plays a critical role in intelligent editing. The model is capable of processing hour-long videos with strong temporal understanding capability, e.g., retrieve time ranges for certain queries. To support a comprehensive evaluation in real-world scenarios, we also present the VUE-TR benchmark, which introduces five key advancements. 1) Video duration: significantly longer than existing temporal retrival datasets, 2) Audio support: includes audio-based queries, 3) Query format: diverse query lengths/formats, 4) Annotation quality: ground-truth time ranges are manually annotated. 5) Evaluation metric: a refined IoU metric to support evaluation over multiple time ranges. Remarkably, Vidi significantly outperforms leading proprietary models, e.g., GPT-4o and Gemini, on the temporal retrieval task, indicating its superiority in video editing scenarios.
Where do Large Vision-Language Models Look at when Answering Questions?
Mar 18, 2025Large Vision-Language Models (LVLMs) have shown promising performance in vision-language understanding and reasoning tasks. However, their visual understanding behaviors remain underexplored. A fundamental question arises: to what extent do LVLMs rely on visual input, and which image regions contribute to their responses? It is non-trivial to interpret the free-form generation of LVLMs due to their complicated visual architecture (e.g., multiple encoders and multi-resolution) and variable-length outputs. In this paper, we extend existing heatmap visualization methods (e.g., iGOS++) to support LVLMs for open-ended visual question answering. We propose a method to select visually relevant tokens that reflect the relevance between generated answers and input image. Furthermore, we conduct a comprehensive analysis of state-of-the-art LVLMs on benchmarks designed to require visual information to answer. Our findings offer several insights into LVLM behavior, including the relationship between focus region and answer correctness, differences in visual attention across architectures, and the impact of LLM scale on visual understanding. The code and data are available at https://github.com/bytedance/LVLM_Interpretation.
Rethinking Homogeneity of Vision and Text Tokens in Large Vision-and-Language Models
Feb 04, 2025



Large vision-and-language models (LVLMs) typically treat visual and textual embeddings as homogeneous inputs to a large language model (LLM). However, these inputs are inherently different: visual inputs are multi-dimensional and contextually rich, often pre-encoded by models like CLIP, while textual inputs lack this structure. In this paper, we propose Decomposed Attention (D-Attn), a novel method that processes visual and textual embeddings differently by decomposing the 1-D causal self-attention in LVLMs. After the attention decomposition, D-Attn diagonalizes visual-to-visual self-attention, reducing computation from $\mathcal{O}(|V|^2)$ to $\mathcal{O}(|V|)$ for $|V|$ visual embeddings without compromising performance. Moreover, D-Attn debiases positional encodings in textual-to-visual cross-attention, further enhancing visual understanding. Finally, we introduce an $\alpha$-weighting strategy to merge visual and textual information, maximally preserving the pre-trained LLM's capabilities with minimal modifications. Extensive experiments and rigorous analyses validate the effectiveness of D-Attn, demonstrating significant improvements on multiple image benchmarks while significantly reducing computational costs. Code, data, and models will be publicly available.
Multi-Reward as Condition for Instruction-based Image Editing
Nov 06, 2024
High-quality training triplets (instruction, original image, edited image) are essential for instruction-based image editing. Predominant training datasets (e.g., InsPix2Pix) are created using text-to-image generative models (e.g., Stable Diffusion, DALL-E) which are not trained for image editing. Accordingly, these datasets suffer from inaccurate instruction following, poor detail preserving, and generation artifacts. In this paper, we propose to address the training data quality issue with multi-perspective reward data instead of refining the ground-truth image quality. 1) we first design a quantitative metric system based on best-in-class LVLM (Large Vision Language Model), i.e., GPT-4o in our case, to evaluate the generation quality from 3 perspectives, namely, instruction following, detail preserving, and generation quality. For each perspective, we collected quantitative score in $0\sim 5$ and text descriptive feedback on the specific failure points in ground-truth edited images, resulting in a high-quality editing reward dataset, i.e., RewardEdit20K. 2) We further proposed a novel training framework to seamlessly integrate the metric output, regarded as multi-reward, into editing models to learn from the imperfect training triplets. During training, the reward scores and text descriptions are encoded as embeddings and fed into both the latent space and the U-Net of the editing models as auxiliary conditions. During inference, we set these additional conditions to the highest score with no text description for failure points, to aim at the best generation outcome. Experiments indicate that our multi-reward conditioned model outperforms its no-reward counterpart on two popular editing pipelines, i.e., InsPix2Pix and SmartEdit. The code and dataset will be released.
DiffLM: Controllable Synthetic Data Generation via Diffusion Language Models
Nov 05, 2024



Recent advancements in large language models (LLMs) have significantly enhanced their knowledge and generative capabilities, leading to a surge of interest in leveraging LLMs for high-quality data synthesis. However, synthetic data generation via prompting LLMs remains challenging due to LLMs' limited understanding of target data distributions and the complexity of prompt engineering, especially for structured formatted data. To address these issues, we introduce DiffLM, a controllable data synthesis framework based on variational autoencoder (VAE), which further (1) leverages diffusion models to reserve more information of original distribution and format structure in the learned latent distribution and (2) decouples the learning of target distribution knowledge from the LLM's generative objectives via a plug-and-play latent feature injection module. As we observed significant discrepancies between the VAE's latent representations and the real data distribution, the latent diffusion module is introduced into our framework to learn a fully expressive latent distribution. Evaluations on seven real-world datasets with structured formatted data (i.e., Tabular, Code and Tool data) demonstrate that DiffLM generates high-quality data, with performance on downstream tasks surpassing that of real data by 2-7 percent in certain cases. The data and code will be publicly available upon completion of internal review.