 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Learning from a Physical World Model
Nov 10, 2025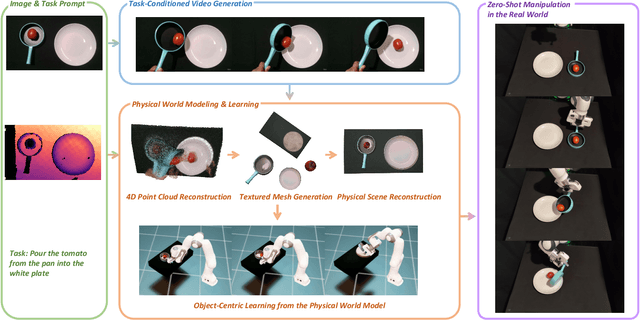

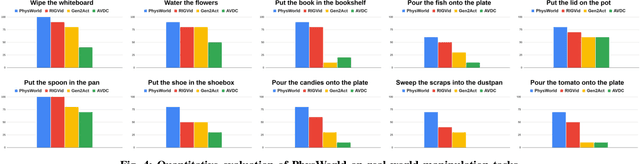

We introduce PhysWorld, a framework that enables robot learning from video generation through physical world modeling. Recent video generation models can synthesize photorealistic visual demonstrations from language commands and images, offering a powerful yet underexplored source of training signals for robotics. However, directly retargeting pixel motions from generated videos to robots neglects physics, often resulting in inaccurate manipulations. PhysWorld addresses this limitation by coupling video generation with physical world reconstruction. Given a single image and a task command, our method generates task-conditioned videos and reconstructs the underlying physical world from the videos, and the generated video motions are grounded into physically accurate actions through object-centric residual reinforcement learning with the physical world model. This synergy transforms implicit visual guidance into physically executable robotic trajectories, eliminating the need for real robot data collection and enabling zero-shot generalizable robotic manipulation. Experiments on diverse real-world tasks demonstrate that PhysWorld substantially improves manipulation accuracy compared to previous approaches. Visit \href{https://pointscoder.github.io/PhysWorld_Web/}{the project webpage} for details.
Enhanced total variation minimization for stable image reconstruction
Jan 09, 2022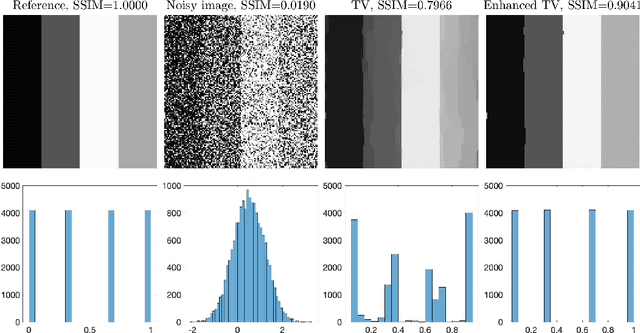
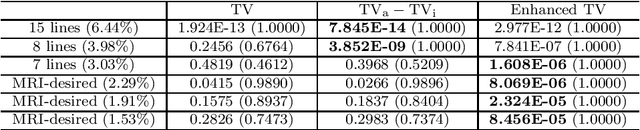
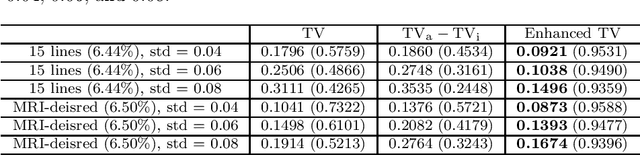
The total variation (TV) regularization has phenomenally boosted various variational models for image processing tasks. We propose combining the backward diffusion process in the earlier literature of image enhancement with the TV regularization and show that the resulting enhanced TV minimization model is particularly effective for reducing the loss of contrast, which is often encountered by models using the TV regularization. We establish stable reconstruction guarantees for the enhanced TV model from noisy subsampled measurements; non-adaptive linear measurements and variable-density sampled Fourier measurements are considered. In particular, under some weaker restricted isometry property conditions, the enhanced TV minimization model is shown to have tighter reconstruction error bounds than various TV-based models for the scenario where the level of noise is significant and the amount of measurements is limited. The advantages of the enhanced TV model are also numerically validated by preliminary experiments on the reconstruction of some synthetic, natural, and medical images.