 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVMem: Consistent Interactive Video Scene Generation with Surfel-Indexed View Memory
Jun 23, 2025We propose a novel memory mechanism to build video generators that can explore environments interactively. Similar results have previously been achieved by out-painting 2D views of the scene while incrementally reconstructing its 3D geometry, which quickly accumulates errors, or by video generators with a short context window, which struggle to maintain scene coherence over the long term. To address these limitations, we introduce Surfel-Indexed View Memory (VMem), a mechanism that remembers past views by indexing them geometrically based on the 3D surface elements (surfels) they have observed. VMem enables the efficient retrieval of the most relevant past views when generating new ones. By focusing only on these relevant views, our method produces consistent explorations of imagined environments at a fraction of the computational cost of using all past views as context. We evaluate our approach on challenging long-term scene synthesis benchmarks and demonstrate superior performance compared to existing methods in maintaining scene coherence and camera control.
DualPM: Dual Posed-Canonical Point Maps for 3D Shape and Pose Reconstruction
Dec 05, 2024



The choice of data representation is a key factor in the success of deep learning in geometric tasks. For instance, DUSt3R has recently introduced the concept of viewpoint-invariant point maps, generalizing depth prediction, and showing that one can reduce all the key problems in the 3D reconstruction of static scenes to predicting such point maps. In this paper, we develop an analogous concept for a very different problem, namely, the reconstruction of the 3D shape and pose of deformable objects. To this end, we introduce the Dual Point Maps (DualPM), where a pair of point maps is extracted from the {same} image, one associating pixels to their 3D locations on the object, and the other to a canonical version of the object at rest pose. We also extend point maps to amodal reconstruction, seeing through self-occlusions to obtain the complete shape of the object. We show that 3D reconstruction and 3D pose estimation reduce to the prediction of the DualPMs. We demonstrate empirically that this representation is a good target for a deep network to predict; specifically, we consider modeling horses, showing that DualPMs can be trained purely on 3D synthetic data, consisting of a single model of a horse, while generalizing very well to real images. With this, we improve by a large margin previous methods for the 3D analysis and reconstruction of this type of objects.
DreamHOI: Subject-Driven Generation of 3D Human-Object Interactions with Diffusion Priors
Sep 12, 2024



We present DreamHOI, a novel method for zero-shot synthesis of human-object interactions (HOIs), enabling a 3D human model to realistically interact with any given object based on a textual description. This task is complicated by the varying categories and geometries of real-world objects and the scarcity of datasets encompassing diverse HOIs. To circumvent the need for extensive data, we leverage text-to-image diffusion models trained on billions of image-caption pairs. We optimize the articulation of a skinned human mesh using Score Distillation Sampling (SDS) gradients obtained from these models, which predict image-space edits. However, directly backpropagating image-space gradients into complex articulation parameters is ineffective due to the local nature of such gradients. To overcome this, we introduce a dual implicit-explicit representation of a skinned mesh, combining (implicit) neural radiance fields (NeRFs) with (explicit) skeleton-driven mesh articulation. During optimization, we transition between implicit and explicit forms, grounding the NeRF generation while refining the mesh articulation. We validate our approach through extensive experiments, demonstrating its effectiveness in generating realistic HOIs.
DreamBeast: Distilling 3D Fantastical Animals with Part-Aware Knowledge Transfer
Sep 12, 2024



We present DreamBeast, a novel method based on score distillation sampling (SDS) for generating fantastical 3D animal assets composed of distinct parts. Existing SDS methods often struggle with this generation task due to a limited understanding of part-level semantics in text-to-image diffusion models. While recent diffusion models, such as Stable Diffusion 3, demonstrate a better part-level understanding, they are prohibitively slow and exhibit other common problems associated with single-view diffusion models. DreamBeast overcomes this limitation through a novel part-aware knowledge transfer mechanism. For each generated asset, we efficiently extract part-level knowledge from the Stable Diffusion 3 model into a 3D Part-Affinity implicit representation. This enables us to instantly generate Part-Affinity maps from arbitrary camera views, which we then use to modulate the guidance of a multi-view diffusion model during SDS to create 3D assets of fantastical animals. DreamBeast significantly enhances the quality of generated 3D creatures with user-specified part compositions while reducing computational overhead, as demonstrated by extensive quantitative and qualitative evaluations.
Learning the 3D Fauna of the Web
Jan 04, 2024Learning 3D models of all animals on the Earth requires massively scaling up existing solutions. With this ultimate goal in mind, we develop 3D-Fauna, an approach that learns a pan-category deformable 3D animal model for more than 100 animal species jointly. One crucial bottleneck of modeling animals is the limited availability of training data, which we overcome by simply learning from 2D Internet images. We show that prior category-specific attempts fail to generalize to rare species with limited training images. We address this challenge by introducing the Semantic Bank of Skinned Models (SBSM), which automatically discovers a small set of base animal shapes by combining geometric inductive priors with semantic knowledge implicitly captured by an off-the-shelf self-supervised feature extractor. To train such a model, we also contribute a new large-scale dataset of diverse animal species. At inference time, given a single image of any quadruped animal, our model reconstructs an articulated 3D mesh in a feed-forward fashion within seconds.
Scene-Conditional 3D Object Stylization and Composition
Dec 19, 2023Recently, 3D generative models have made impressive progress, enabling the generation of almost arbitrary 3D assets from text or image inputs. However, these approaches generate objects in isolation without any consideration for the scene where they will eventually be placed. In this paper, we propose a framework that allows for the stylization of an existing 3D asset to fit into a given 2D scene, and additionally produce a photorealistic composition as if the asset was placed within the environment. This not only opens up a new level of control for object stylization, for example, the same assets can be stylized to reflect changes in the environment, such as summer to winter or fantasy versus futuristic settings-but also makes the object-scene composition more controllable. We achieve this by combining modeling and optimizing the object's texture and environmental lighting through differentiable ray tracing with image priors from pre-trained text-to-image diffusion models. We demonstrate that our method is applicable to a wide variety of indoor and outdoor scenes and arbitrary objects.
Calibrated Uncertainties for Neural Radiance Fields
Dec 04, 2023Neural Radiance Fields have achieved remarkable results for novel view synthesis but still lack a crucial component: precise measurement of uncertainty in their predictions. Probabilistic NeRF methods have tried to address this, but their output probabilities are not typically accurately calibrated, and therefore do not capture the true confidence levels of the model. Calibration is a particularly challenging problem in the sparse-view setting, where additional held-out data is unavailable for fitting a calibrator that generalizes to the test distribution. In this paper, we introduce the first method for obtaining calibrated uncertainties from NeRF models. Our method is based on a robust and efficient metric to calculate per-pixel uncertainties from the predictive posterior distribution. We propose two techniques that eliminate the need for held-out data. The first, based on patch sampling, involves training two NeRF models for each scene. The second is a novel meta-calibrator that only requires the training of one NeRF model. Our proposed approach for obtaining calibrated uncertainties achieves state-of-the-art uncertainty in the sparse-view setting while maintaining image quality. We further demonstrate our method's effectiveness in applications such as view enhancement and next-best view selection.
Farm3D: Learning Articulated 3D Animals by Distilling 2D Diffusion
Apr 20, 2023We present Farm3D, a method to learn category-specific 3D reconstructors for articulated objects entirely from "free" virtual supervision from a pre-trained 2D diffusion-based image generator. Recent approaches can learn, given a collection of single-view images of an object category, a monocular network to predict the 3D shape, albedo, illumination and viewpoint of any object occurrence. We propose a framework using an image generator like Stable Diffusion to generate virtual training data for learning such a reconstruction network from scratch. Furthermore, we include the diffusion model as a score to further improve learning. The idea is to randomise some aspects of the reconstruction, such as viewpoint and illumination, generating synthetic views of the reconstructed 3D object, and have the 2D network assess the quality of the resulting image, providing feedback to the reconstructor. Different from work based on distillation which produces a single 3D asset for each textual prompt in hours, our approach produces a monocular reconstruction network that can output a controllable 3D asset from a given image, real or generated, in only seconds. Our network can be used for analysis, including monocular reconstruction, or for synthesis, generating articulated assets for real-time applications such as video games.
MagicPony: Learning Articulated 3D Animals in the Wild
Nov 22, 2022We consider the problem of learning a function that can estimate the 3D shape, articulation, viewpoint, texture, and lighting of an articulated animal like a horse, given a single test image. We present a new method, dubbed MagicPony, that learns this function purely from in-the-wild single-view images of the object category, with minimal assumptions about the topology of deformation. At its core is an implicit-explicit representation of articulated shape and appearance, combining the strengths of neural fields and meshes. In order to help the model understand an object's shape and pose, we distil the knowledge captured by an off-the-shelf self-supervised vision transformer and fuse it into the 3D model. To overcome common local optima in viewpoint estimation, we further introduce a new viewpoint sampling scheme that comes at no added training cost. Compared to prior works, we show significant quantitative and qualitative improvements on this challenging task. The model also demonstrates excellent generalisation in reconstructing abstract drawings and artefacts, despite the fact that it is only trained on real images.
DOVE: Learning Deformable 3D Objects by Watching Videos
Jul 22, 2021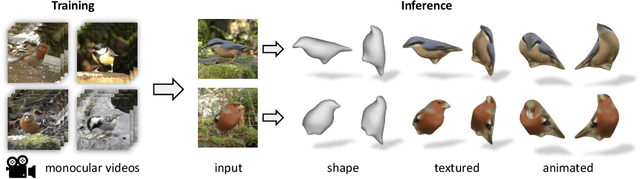
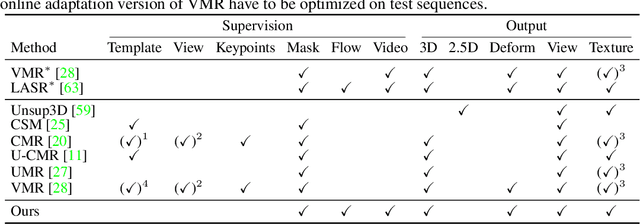
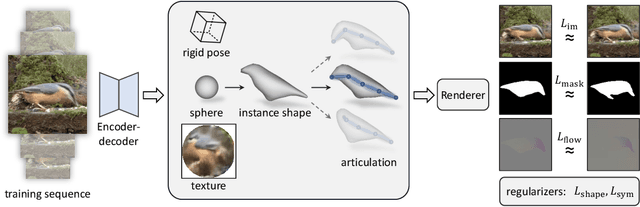
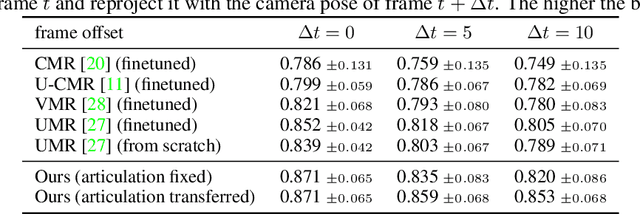
Learning deformable 3D objects from 2D images is an extremely ill-posed problem. Existing methods rely on explicit supervision to establish multi-view correspondences, such as template shape models and keypoint annotations, which restricts their applicability on objects "in the wild". In this paper, we propose to use monocular videos, which naturally provide correspondences across time, allowing us to learn 3D shapes of deformable object categories without explicit keypoints or template shapes. Specifically, we present DOVE, which learns to predict 3D canonical shape, deformation, viewpoint and texture from a single 2D image of a bird, given a bird video collection as well as automatically obtained silhouettes and optical flows as training data. Our method reconstructs temporally consistent 3D shape and deformation, which allows us to animate and re-render the bird from arbitrary viewpoints from a single image.