 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Reconstructing Dynamic Scenes One D4RT at a Time
Dec 10, 2025



Understanding and reconstructing the complex geometry and motion of dynamic scenes from video remains a formidable challenge in computer vision. This paper introduces D4RT, a simple yet powerful feedforward model designed to efficiently solve this task. D4RT utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and full camera parameters from a single video. Its core innovation is a novel querying mechanism that sidesteps the heavy computation of dense, per-frame decoding and the complexity of managing multiple, task-specific decoders. Our decoding interface allows the model to independently and flexibly probe the 3D position of any point in space and time. The result is a lightweight and highly scalable method that enables remarkably efficient training and inference. We demonstrate that our approach sets a new state of the art, outperforming previous methods across a wide spectrum of 4D reconstruction tasks. We refer to the project webpage for animated results: https://d4rt-paper.github.io/.
Self-supervised Hypergraphs for Learning Multiple World Interpretations
Aug 21, 2023We present a method for learning multiple scene representations given a small labeled set, by exploiting the relationships between such representations in the form of a multi-task hypergraph. We also show how we can use the hypergraph to improve a powerful pretrained VisTransformer model without any additional labeled data. In our hypergraph, each node is an interpretation layer (e.g., depth or segmentation) of the scene. Within each hyperedge, one or several input nodes predict the layer at the output node. Thus, each node could be an input node in some hyperedges and an output node in others. In this way, multiple paths can reach the same node, to form ensembles from which we obtain robust pseudolabels, which allow self-supervised learning in the hypergraph. We test different ensemble models and different types of hyperedges and show superior performance to other multi-task graph models in the field. We also introduce Dronescapes, a large video dataset captured with UAVs in different complex real-world scenes, with multiple representations, suitable for multi-task learning.
HSPACE: Synthetic Parametric Humans Animated in Complex Environments
Jan 06, 2022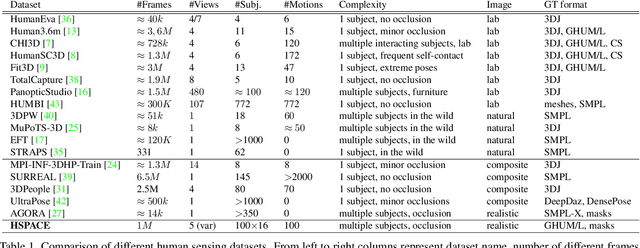
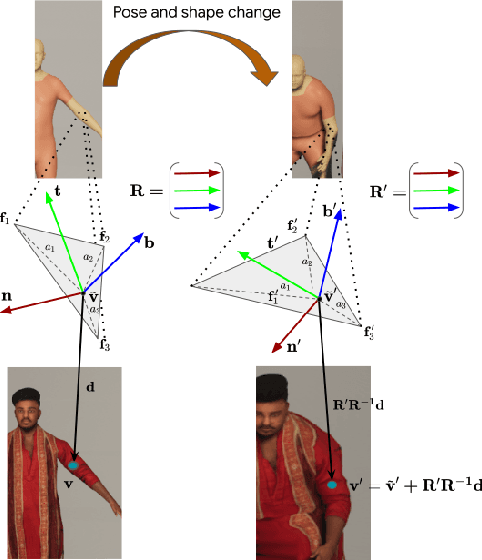
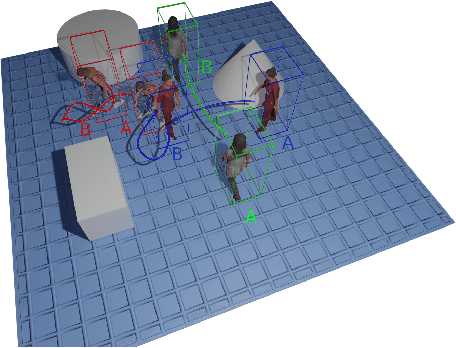
Advances in the state of the art for 3d human sensing are currently limited by the lack of visual datasets with 3d ground truth, including multiple people, in motion, operating in real-world environments, with complex illumination or occlusion, and potentially observed by a moving camera. Sophisticated scene understanding would require estimating human pose and shape as well as gestures, towards representations that ultimately combine useful metric and behavioral signals with free-viewpoint photo-realistic visualisation capabilities. To sustain progress, we build a large-scale photo-realistic dataset, Human-SPACE (HSPACE), of animated humans placed in complex synthetic indoor and outdoor environments. We combine a hundred diverse individuals of varying ages, gender, proportions, and ethnicity, with hundreds of motions and scenes, as well as parametric variations in body shape (for a total of 1,600 different humans), in order to generate an initial dataset of over 1 million frames. Human animations are obtained by fitting an expressive human body model, GHUM, to single scans of people, followed by novel re-targeting and positioning procedures that support the realistic animation of dressed humans, statistical variation of body proportions, and jointly consistent scene placement of multiple moving people. Assets are generated automatically, at scale, and are compatible with existing real time rendering and game engines. The dataset with evaluation server will be made available for research. Our large-scale analysis of the impact of synthetic data, in connection with real data and weak supervision, underlines the considerable potential for continuing quality improvements and limiting the sim-to-real gap, in this practical setting, in connection with increased model capacity.
Discrete Representations Strengthen Vision Transformer Robustness
Nov 20, 2021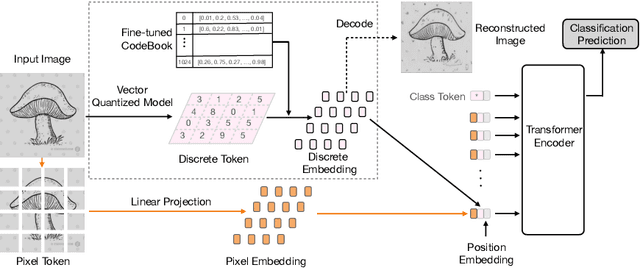
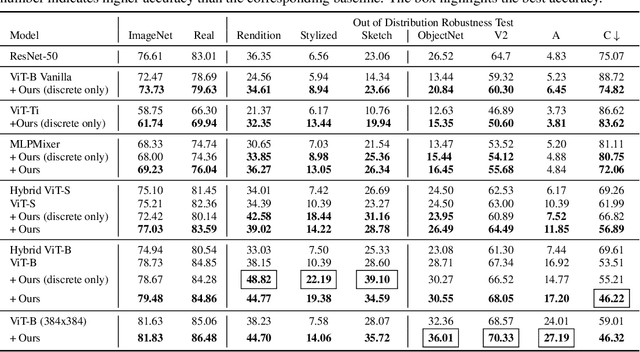


Vision Transformer (ViT) is emerging as the state-of-the-art architecture for image recognition. While recent studies suggest that ViTs are more robust than their convolutional counterparts, our experiments find that ViTs are overly reliant on local features (e.g., nuisances and texture) and fail to make adequate use of global context (e.g., shape and structure). As a result, ViTs fail to generalize to out-of-distribution, real-world data. To address this deficiency, we present a simple and effective architecture modification to ViT's input layer by adding discrete tokens produced by a vector-quantized encoder. Different from the standard continuous pixel tokens, discrete tokens are invariant under small perturbations and contain less information individually, which promote ViTs to learn global information that is invariant. Experimental results demonstrate that adding discrete representation on four architecture variants strengthens ViT robustness by up to 12% across seven ImageNet robustness benchmarks while maintaining the performance on ImageNet.
THUNDR: Transformer-based 3D HUmaN Reconstruction with Markers
Jun 17, 2021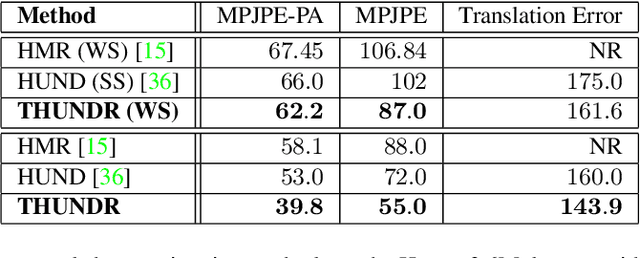
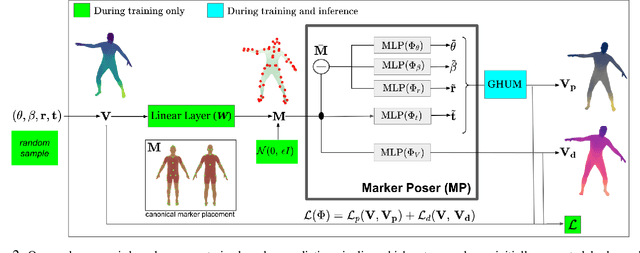
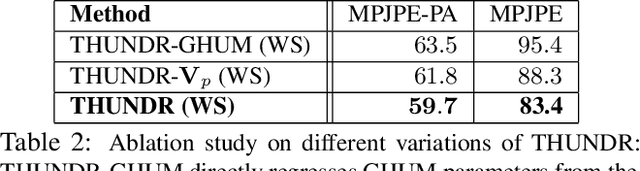
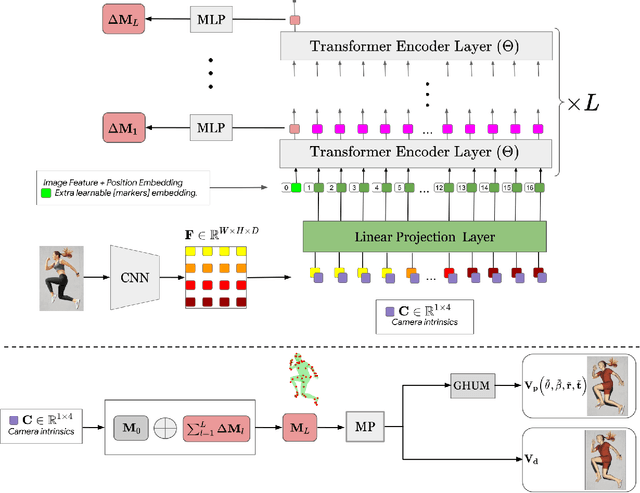
We present THUNDR, a transformer-based deep neural network methodology to reconstruct the 3d pose and shape of people, given monocular RGB images. Key to our methodology is an intermediate 3d marker representation, where we aim to combine the predictive power of model-free-output architectures and the regularizing, anthropometrically-preserving properties of a statistical human surface model like GHUM -- a recently introduced, expressive full body statistical 3d human model, trained end-to-end. Our novel transformer-based prediction pipeline can focus on image regions relevant to the task, supports self-supervised regimes, and ensures that solutions are consistent with human anthropometry. We show state-of-the-art results on Human3.6M and 3DPW, for both the fully-supervised and the self-supervised models, for the task of inferring 3d human shape, joint positions, and global translation. Moreover, we observe very solid 3d reconstruction performance for difficult human poses collected in the wild.
Semi-Supervised Learning for Multi-Task Scene Understanding by Neural Graph Consensus
Oct 02, 2020
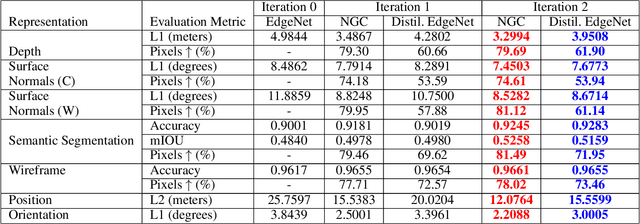
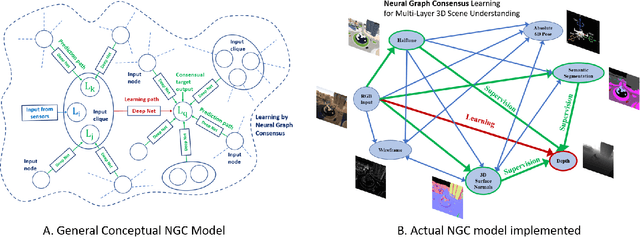

We address the challenging problem of semi-supervised learning in the context of multiple visual interpretations of the world by finding consensus in a graph of neural networks. Each graph node is a scene interpretation layer, while each edge is a deep net that transforms one layer at one node into another from a different node. During the supervised phase edge networks are trained independently. During the next unsupervised stage edge nets are trained on the pseudo-ground truth provided by consensus among multiple paths that reach the nets' start and end nodes. These paths act as ensemble teachers for any given edge and strong consensus is used for high-confidence supervisory signal. The unsupervised learning process is repeated over several generations, in which each edge becomes a "student" and also part of different ensemble "teachers" for training other students. By optimizing such consensus between different paths, the graph reaches consistency and robustness over multiple interpretations and generations, in the face of unknown labels. We give theoretical justifications of the proposed idea and validate it on a large dataset. We show how prediction of different representations such as depth, semantic segmentation, surface normals and pose from RGB input could be effectively learned through self-supervised consensus in our graph. We also compare to state-of-the-art methods for multi-task and semi-supervised learning and show superior performance.
Neural Descent for Visual 3D Human Pose and Shape
Aug 16, 2020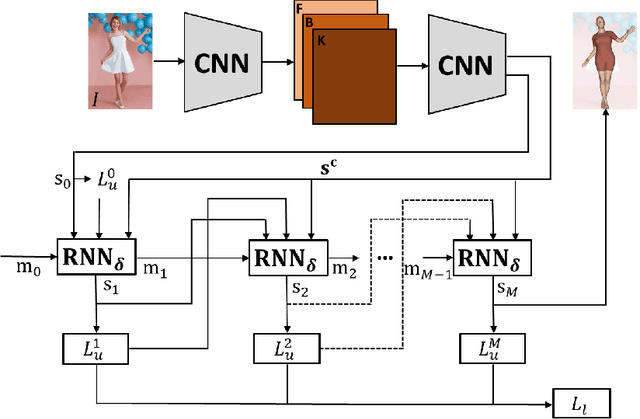
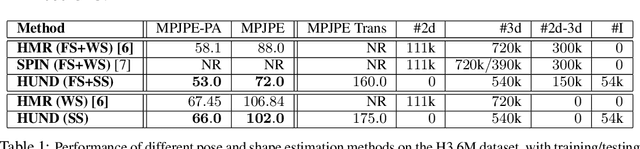

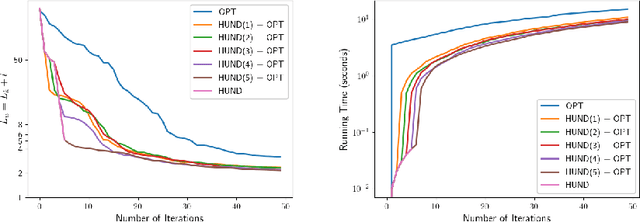
We present deep neural network methodology to reconstruct the 3d pose and shape of people, given an input RGB image. We rely on a recently introduced, expressivefull body statistical 3d human model, GHUM, trained end-to-end, and learn to reconstruct its pose and shape state in a self-supervised regime. Central to our methodology, is a learning to learn and optimize approach, referred to as HUmanNeural Descent (HUND), which avoids both second-order differentiation when training the model parameters,and expensive state gradient descent in order to accurately minimize a semantic differentiable rendering loss at test time. Instead, we rely on novel recurrent stages to update the pose and shape parameters such that not only losses are minimized effectively, but the process is meta-regularized in order to ensure end-progress. HUND's symmetry between training and testing makes it the first 3d human sensing architecture to natively support different operating regimes including self-supervised ones. In diverse tests, we show that HUND achieves very competitive results in datasets like H3.6M and 3DPW, aswell as good quality 3d reconstructions for complex imagery collected in-the-wild.
The End-of-End-to-End: A Video Understanding Pentathlon Challenge
Aug 03, 2020
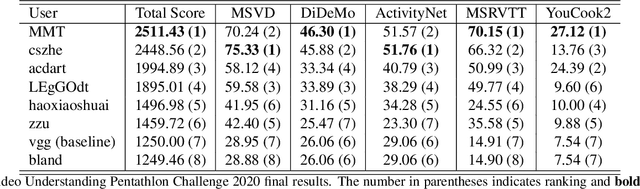
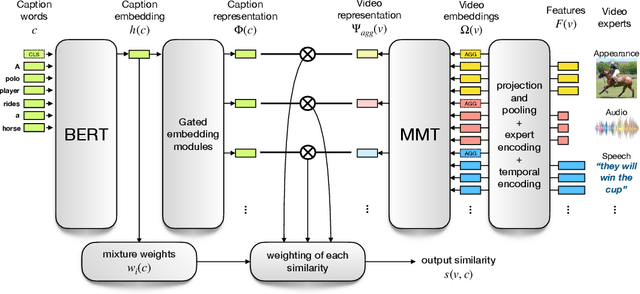
We present a new video understanding pentathlon challenge, an open competition held in conjunction with the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020. The objective of the challenge was to explore and evaluate new methods for text-to-video retrieval-the task of searching for content within a corpus of videos using natural language queries. This report summarizes the results of the first edition of the challenge together with the findings of the participants.
Learning Video Representations from Textual Web Supervision
Jul 29, 2020
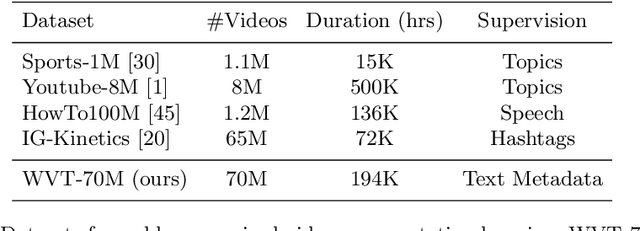
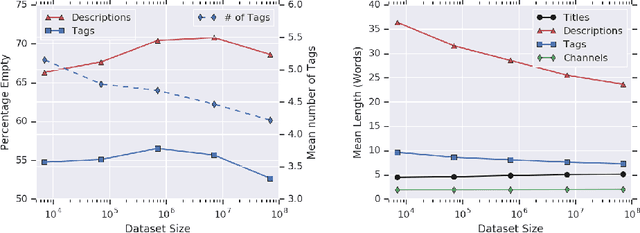

Videos found on the Internet are paired with pieces of text, such as titles and descriptions. This text typically describes the most important content in the video, such as the objects in the scene and the actions being performed. Based on this observation, we propose to use such text as a method for learning video representations. To accomplish this, we propose a data collection process and use it to collect 70M video clips shared publicly on the Internet, and we then train a model to pair each video with its associated text. We fine-tune the model on several down-stream action recognition tasks, including Kinetics, HMDB-51, and UCF-101. We find that this approach is an effective method of pretraining video representations. Specifically, it leads to improvements over from-scratch training on all benchmarks, outperforms many methods for self-supervised and webly-supervised video representation learning, and achieves an improvement of 2.2% accuracy on HMDB-51.
Speech2Action: Cross-modal Supervision for Action Recognition
Mar 30, 2020

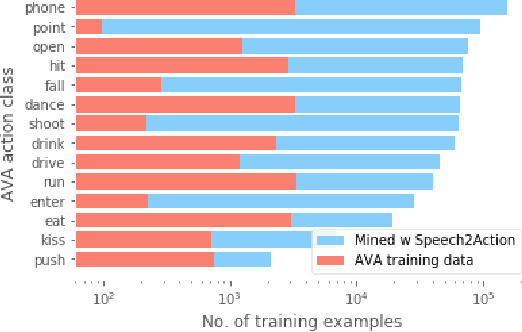
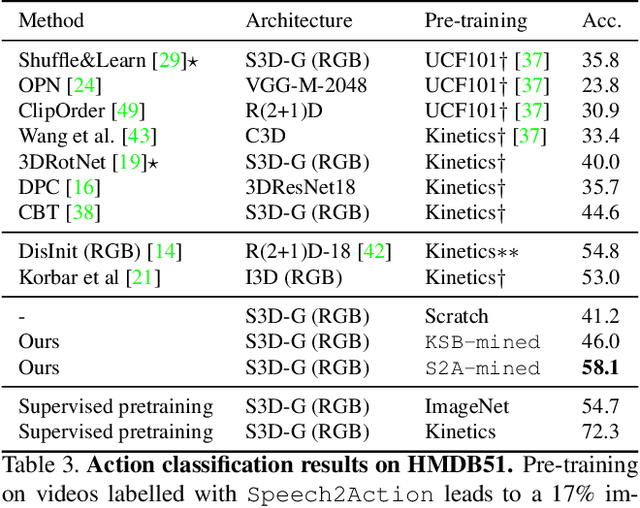
Is it possible to guess human action from dialogue alone? In this work we investigate the link between spoken words and actions in movies. We note that movie screenplays describe actions, as well as contain the speech of characters and hence can be used to learn this correlation with no additional supervision. We train a BERT-based Speech2Action classifier on over a thousand movie screenplays, to predict action labels from transcribed speech segments. We then apply this model to the speech segments of a large unlabelled movie corpus (188M speech segments from 288K movies). Using the predictions of this model, we obtain weak action labels for over 800K video clips. By training on these video clips, we demonstrate superior action recognition performance on standard action recognition benchmarks, without using a single manually labelled action example.