 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiFormer3D: Grid-Free Time-Domain Reconstruction of Head-Related Impulse Responses with a Spatially Encoded Transformer
Mar 30, 2026Individualized head-related impulse responses (HRIRs) enable binaural rendering, but dense per-listener measurements are costly. We address HRIR spatial up-sampling from sparse per-listener measurements: given a few measured HRIRs for a listener, predict HRIRs at unmeasured target directions. Prior learning methods often work in the frequency domain, rely on minimum-phase assumptions or separate timing models, and use a fixed direction grid, which can degrade temporal fidelity and spatial continuity. We propose BiFormer3D, a time-domain, grid-free binaural Transformer for reconstructing HRIRs at arbitrary directions from sparse inputs. It uses sinusoidal spatial features, a Conv1D refinement module, and auxiliary interaural time difference (ITD) and interaural level difference (ILD) heads. On SONICOM, it improves normalized mean squared error (NMSE), cosine distance, and ITD/ILD errors over prior methods; ablations validate modules and show minimum-phase pre-processing is unnecessary.
RIR-Former: Coordinate-Guided Transformer for Continuous Reconstruction of Room Impulse Responses
Feb 03, 2026Room impulse responses (RIRs) are essential for many acoustic signal processing tasks, yet measuring them densely across space is often impractical. In this work, we propose RIR-Former, a grid-free, one-step feed-forward model for RIR reconstruction. By introducing a sinusoidal encoding module into a transformer backbone, our method effectively incorporates microphone position information, enabling interpolation at arbitrary array locations. Furthermore, a segmented multi-branch decoder is designed to separately handle early reflections and late reverberation, improving reconstruction across the entire RIR. Experiments on diverse simulated acoustic environments demonstrate that RIR-Former consistently outperforms state-of-the-art baselines in terms of normalized mean square error (NMSE) and cosine distance (CD), under varying missing rates and array configurations. These results highlight the potential of our approach for practical deployment and motivate future work on scaling from randomly spaced linear arrays to complex array geometries, dynamic acoustic scenes, and real-world environments.
DreamBeast: Distilling 3D Fantastical Animals with Part-Aware Knowledge Transfer
Sep 12, 2024



We present DreamBeast, a novel method based on score distillation sampling (SDS) for generating fantastical 3D animal assets composed of distinct parts. Existing SDS methods often struggle with this generation task due to a limited understanding of part-level semantics in text-to-image diffusion models. While recent diffusion models, such as Stable Diffusion 3, demonstrate a better part-level understanding, they are prohibitively slow and exhibit other common problems associated with single-view diffusion models. DreamBeast overcomes this limitation through a novel part-aware knowledge transfer mechanism. For each generated asset, we efficiently extract part-level knowledge from the Stable Diffusion 3 model into a 3D Part-Affinity implicit representation. This enables us to instantly generate Part-Affinity maps from arbitrary camera views, which we then use to modulate the guidance of a multi-view diffusion model during SDS to create 3D assets of fantastical animals. DreamBeast significantly enhances the quality of generated 3D creatures with user-specified part compositions while reducing computational overhead, as demonstrated by extensive quantitative and qualitative evaluations.
3D-GPT: Procedural 3D Modeling with Large Language Models
Oct 19, 2023



In the pursuit of efficient automated content creation, procedural generation, leveraging modifiable parameters and rule-based systems, emerges as a promising approach. Nonetheless, it could be a demanding endeavor, given its intricate nature necessitating a deep understanding of rules, algorithms, and parameters. To reduce workload, we introduce 3D-GPT, a framework utilizing large language models~(LLMs) for instruction-driven 3D modeling. 3D-GPT positions LLMs as proficient problem solvers, dissecting the procedural 3D modeling tasks into accessible segments and appointing the apt agent for each task. 3D-GPT integrates three core agents: the task dispatch agent, the conceptualization agent, and the modeling agent. They collaboratively achieve two objectives. First, it enhances concise initial scene descriptions, evolving them into detailed forms while dynamically adapting the text based on subsequent instructions. Second, it integrates procedural generation, extracting parameter values from enriched text to effortlessly interface with 3D software for asset creation. Our empirical investigations confirm that 3D-GPT not only interprets and executes instructions, delivering reliable results but also collaborates effectively with human designers. Furthermore, it seamlessly integrates with Blender, unlocking expanded manipulation possibilities. Our work highlights the potential of LLMs in 3D modeling, offering a basic framework for future advancements in scene generation and animation.
NeRFEditor: Differentiable Style Decomposition for Full 3D Scene Editing
Dec 08, 2022



We present NeRFEditor, an efficient learning framework for 3D scene editing, which takes a video captured over 360{\deg} as input and outputs a high-quality, identity-preserving stylized 3D scene. Our method supports diverse types of editing such as guided by reference images, text prompts, and user interactions. We achieve this by encouraging a pre-trained StyleGAN model and a NeRF model to learn from each other mutually. Specifically, we use a NeRF model to generate numerous image-angle pairs to train an adjustor, which can adjust the StyleGAN latent code to generate high-fidelity stylized images for any given angle. To extrapolate editing to GAN out-of-domain views, we devise another module that is trained in a self-supervised learning manner. This module maps novel-view images to the hidden space of StyleGAN that allows StyleGAN to generate stylized images on novel views. These two modules together produce guided images in 360{\deg}views to finetune a NeRF to make stylization effects, where a stable fine-tuning strategy is proposed to achieve this. Experiments show that NeRFEditor outperforms prior work on benchmark and real-world scenes with better editability, fidelity, and identity preservation.
Harmonizer: Learning to Perform White-Box Image and Video Harmonization
Jul 04, 2022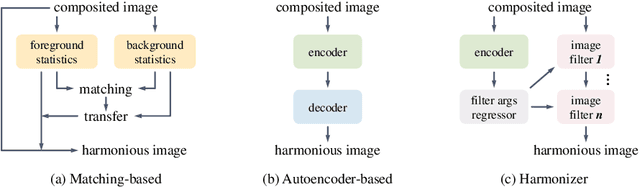
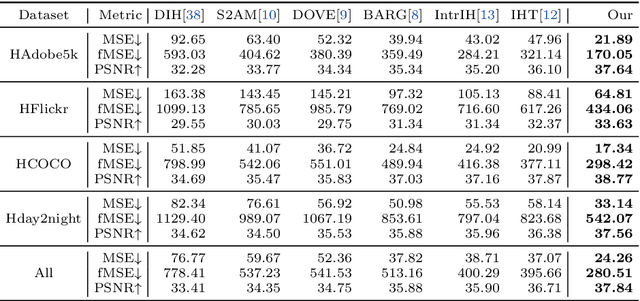
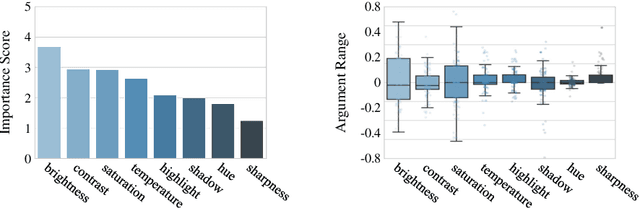
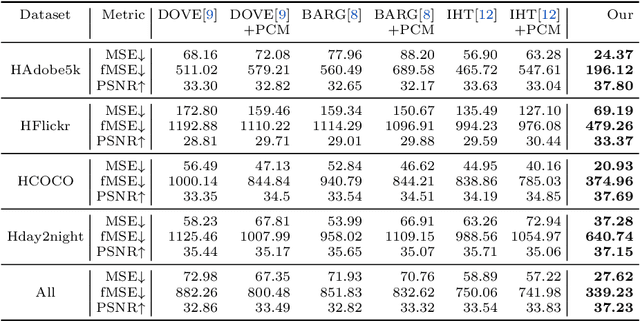
Recent works on image harmonization solve the problem as a pixel-wise image translation task via large autoencoders. They have unsatisfactory performances and slow inference speeds when dealing with high-resolution images. In this work, we observe that adjusting the input arguments of basic image filters, e.g., brightness and contrast, is sufficient for humans to produce realistic images from the composite ones. Hence, we frame image harmonization as an image-level regression problem to learn the arguments of the filters that humans use for the task. We present a Harmonizer framework for image harmonization. Unlike prior methods that are based on black-box autoencoders, Harmonizer contains a neural network for filter argument prediction and several white-box filters (based on the predicted arguments) for image harmonization. We also introduce a cascade regressor and a dynamic loss strategy for Harmonizer to learn filter arguments more stably and precisely. Since our network only outputs image-level arguments and the filters we used are efficient, Harmonizer is much lighter and faster than existing methods. Comprehensive experiments demonstrate that Harmonizer surpasses existing methods notably, especially with high-resolution inputs. Finally, we apply Harmonizer to video harmonization, which achieves consistent results across frames and 56 fps at 1080P resolution. Code and models are available at: https://github.com/ZHKKKe/Harmonizer.
Blind Image Decomposition
Aug 28, 2021
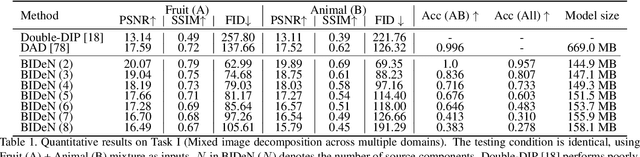
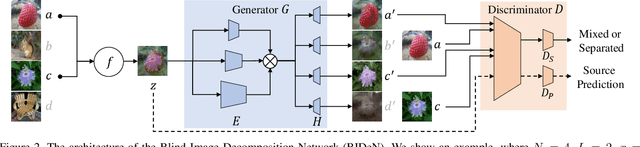

We present and study a novel task named Blind Image Decomposition (BID), which requires separating a superimposed image into constituent underlying images in a blind setting, that is, both the source components involved in mixing as well as the mixing mechanism are unknown. For example, rain may consist of multiple components, such as rain streaks, raindrops, snow, and haze. Rainy images can be treated as an arbitrary combination of these components, some of them or all of them. How to decompose superimposed images, like rainy images, into distinct source components is a crucial step towards real-world vision systems. To facilitate research on this new task, we construct three benchmark datasets, including mixed image decomposition across multiple domains, real-scenario deraining, and joint shadow/reflection/watermark removal. Moreover, we propose a simple yet general Blind Image Decomposition Network (BIDeN) to serve as a strong baseline for future work. Experimental results demonstrate the tenability of our benchmarks and the effectiveness of BIDeN. Code and project page are available.
Defocus Blur Detection via Salient Region Detection Prior
Nov 19, 2020
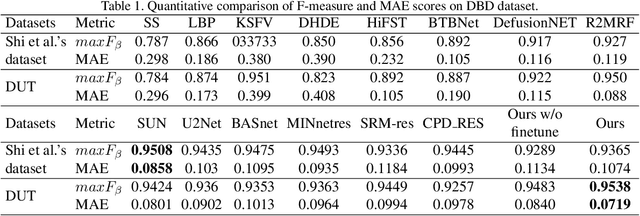


Defocus blur always occurred in photos when people take photos by Digital Single Lens Reflex Camera(DSLR), giving salient region and aesthetic pleasure. Defocus blur Detection aims to separate the out-of-focus and depth-of-field areas in photos, which is an important work in computer vision. Current works for defocus blur detection mainly focus on the designing of networks, the optimizing of the loss function, and the application of multi-stream strategy, meanwhile, these works do not pay attention to the shortage of training data. In this work, to address the above data-shortage problem, we turn to rethink the relationship between two tasks: defocus blur detection and salient region detection. In an image with bokeh effect, it is obvious that the salient region and the depth-of-field area overlap in most cases. So we first train our network on the salient region detection tasks, then transfer the pre-trained model to the defocus blur detection tasks. Besides, we propose a novel network for defocus blur detection. Experiments show that our transfer strategy works well on many current models, and demonstrate the superiority of our network.