 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntityBench: Towards Entity-Consistent Long-Range Multi-Shot Video Generation
May 14, 2026Multi-shot video generation extends single-shot generation to coherent visual narratives, yet maintaining consistent characters, objects, and locations across shots remains a challenge over long sequences. Existing evaluations typically use independently generated prompt sets with limited entity coverage and simple consistency metrics, making standardized comparison difficult. We introduce EntityBench, a benchmark of 140 episodes (2,491 shots) derived from real narrative media, with explicit per-shot entity schedules tracking characters, objects, and locations simultaneously across easy / medium / hard tiers of up to 50 shots, 13 cross-shot characters, 8 cross-shot locations, 22 cross-shot objects, and recurrence gaps spanning up to 48 shots. It is paired with a three-pillar evaluation suite that disentangles intra-shot quality, prompt-following alignment, and cross-shot consistency, with a fidelity gate that admits only accurate entity appearances into cross-shot scoring. As a baseline, we propose EntityMem, a memory-augmented generation system that stores verified per-entity visual references in a persistent memory bank before generation begins. Experiments show that cross-shot entity consistency degrades sharply with recurrence distance in existing methods, and that explicit per-entity memory yields the highest character fidelity (Cohen's d = +2.33) and presence among methods evaluated. Code and data are available at https://github.com/Catherine-R-He/EntityBench/.
Seedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Where It Moves, It Matters: Referring Surgical Instrument Segmentation via Motion
Jan 18, 2026Enabling intuitive, language-driven interaction with surgical scenes is a critical step toward intelligent operating rooms and autonomous surgical robotic assistance. However, the task of referring segmentation, localizing surgical instruments based on natural language descriptions, remains underexplored in surgical videos, with existing approaches struggling to generalize due to reliance on static visual cues and predefined instrument names. In this work, we introduce SurgRef, a novel motion-guided framework that grounds free-form language expressions in instrument motion, capturing how tools move and interact across time, rather than what they look like. This allows models to understand and segment instruments even under occlusion, ambiguity, or unfamiliar terminology. To train and evaluate SurgRef, we present Ref-IMotion, a diverse, multi-institutional video dataset with dense spatiotemporal masks and rich motion-centric expressions. SurgRef achieves state-of-the-art accuracy and generalization across surgical procedures, setting a new benchmark for robust, language-driven surgical video segmentation.
VL-LN Bench: Towards Long-horizon Goal-oriented Navigation with Active Dialogs
Dec 31, 2025In most existing embodied navigation tasks, instructions are well-defined and unambiguous, such as instruction following and object searching. Under this idealized setting, agents are required solely to produce effective navigation outputs conditioned on vision and language inputs. However, real-world navigation instructions are often vague and ambiguous, requiring the agent to resolve uncertainty and infer user intent through active dialog. To address this gap, we propose Interactive Instance Object Navigation (IION), a task that requires agents not only to generate navigation actions but also to produce language outputs via active dialog, thereby aligning more closely with practical settings. IION extends Instance Object Navigation (ION) by allowing agents to freely consult an oracle in natural language while navigating. Building on this task, we present the Vision Language-Language Navigation (VL-LN) benchmark, which provides a large-scale, automatically generated dataset and a comprehensive evaluation protocol for training and assessing dialog-enabled navigation models. VL-LN comprises over 41k long-horizon dialog-augmented trajectories for training and an automatic evaluation protocol with an oracle capable of responding to agent queries. Using this benchmark, we train a navigation model equipped with dialog capabilities and show that it achieves significant improvements over the baselines. Extensive experiments and analyses further demonstrate the effectiveness and reliability of VL-LN for advancing research on dialog-enabled embodied navigation. Code and dataset: https://0309hws.github.io/VL-LN.github.io/
End-to-End Training for Autoregressive Video Diffusion via Self-Resampling
Dec 17, 2025



Autoregressive video diffusion models hold promise for world simulation but are vulnerable to exposure bias arising from the train-test mismatch. While recent works address this via post-training, they typically rely on a bidirectional teacher model or online discriminator. To achieve an end-to-end solution, we introduce Resampling Forcing, a teacher-free framework that enables training autoregressive video models from scratch and at scale. Central to our approach is a self-resampling scheme that simulates inference-time model errors on history frames during training. Conditioned on these degraded histories, a sparse causal mask enforces temporal causality while enabling parallel training with frame-level diffusion loss. To facilitate efficient long-horizon generation, we further introduce history routing, a parameter-free mechanism that dynamically retrieves the top-k most relevant history frames for each query. Experiments demonstrate that our approach achieves performance comparable to distillation-based baselines while exhibiting superior temporal consistency on longer videos owing to native-length training.
ASAP-Textured Gaussians: Enhancing Textured Gaussians with Adaptive Sampling and Anisotropic Parameterization
Dec 16, 2025



Recent advances have equipped 3D Gaussian Splatting with texture parameterizations to capture spatially varying attributes, improving the performance of both appearance modeling and downstream tasks. However, the added texture parameters introduce significant memory efficiency challenges. Rather than proposing new texture formulations, we take a step back to examine the characteristics of existing textured Gaussian methods and identify two key limitations in common: (1) Textures are typically defined in canonical space, leading to inefficient sampling that wastes textures' capacity on low-contribution regions; and (2) texture parameterization is uniformly assigned across all Gaussians, regardless of their visual complexity, resulting in over-parameterization. In this work, we address these issues through two simple yet effective strategies: adaptive sampling based on the Gaussian density distribution and error-driven anisotropic parameterization that allocates texture resources according to rendering error. Our proposed ASAP Textured Gaussians, short for Adaptive Sampling and Anisotropic Parameterization, significantly improve the quality efficiency tradeoff, achieving high-fidelity rendering with far fewer texture parameters.
Ground Slow, Move Fast: A Dual-System Foundation Model for Generalizable Vision-and-Language Navigation
Dec 09, 2025While recent large vision-language models (VLMs) have improved generalization in vision-language navigation (VLN), existing methods typically rely on end-to-end pipelines that map vision-language inputs directly to short-horizon discrete actions. Such designs often produce fragmented motions, incur high latency, and struggle with real-world challenges like dynamic obstacle avoidance. We propose DualVLN, the first dual-system VLN foundation model that synergistically integrates high-level reasoning with low-level action execution. System 2, a VLM-based global planner, "grounds slowly" by predicting mid-term waypoint goals via image-grounded reasoning. System 1, a lightweight, multi-modal conditioning Diffusion Transformer policy, "moves fast" by leveraging both explicit pixel goals and latent features from System 2 to generate smooth and accurate trajectories. The dual-system design enables robust real-time control and adaptive local decision-making in complex, dynamic environments. By decoupling training, the VLM retains its generalization, while System 1 achieves interpretable and effective local navigation. DualVLN outperforms prior methods across all VLN benchmarks and real-world experiments demonstrate robust long-horizon planning and real-time adaptability in dynamic environments.
Unified Camera Positional Encoding for Controlled Video Generation
Dec 08, 2025Transformers have emerged as a universal backbone across 3D perception, video generation, and world models for autonomous driving and embodied AI, where understanding camera geometry is essential for grounding visual observations in three-dimensional space. However, existing camera encoding methods often rely on simplified pinhole assumptions, restricting generalization across the diverse intrinsics and lens distortions in real-world cameras. We introduce Relative Ray Encoding, a geometry-consistent representation that unifies complete camera information, including 6-DoF poses, intrinsics, and lens distortions. To evaluate its capability under diverse controllability demands, we adopt camera-controlled text-to-video generation as a testbed task. Within this setting, we further identify pitch and roll as two components effective for Absolute Orientation Encoding, enabling full control over the initial camera orientation. Together, these designs form UCPE (Unified Camera Positional Encoding), which integrates into a pretrained video Diffusion Transformer through a lightweight spatial attention adapter, adding less than 1% trainable parameters while achieving state-of-the-art camera controllability and visual fidelity. To facilitate systematic training and evaluation, we construct a large video dataset covering a wide range of camera motions and lens types. Extensive experiments validate the effectiveness of UCPE in camera-controllable video generation and highlight its potential as a general camera representation for Transformers across future multi-view, video, and 3D tasks. Code will be available at https://github.com/chengzhag/UCPE.
Comparative validation of surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation in endoscopy: Results of the PhaKIR 2024 challenge
Jul 22, 2025Reliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability. To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures. We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.
SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
Jun 05, 2025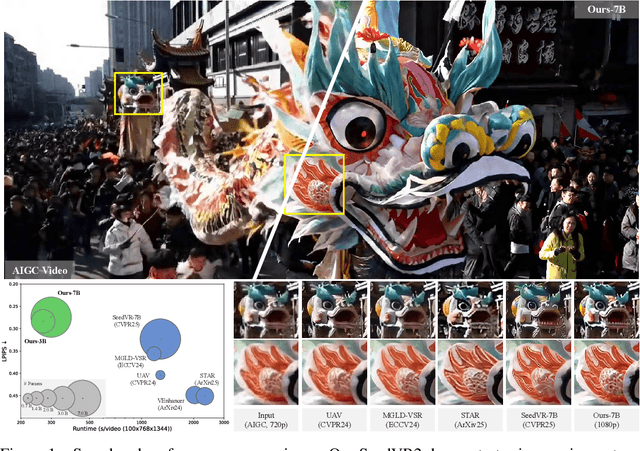
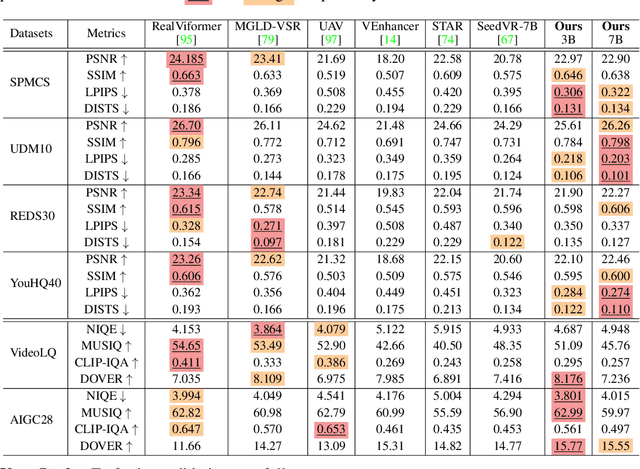
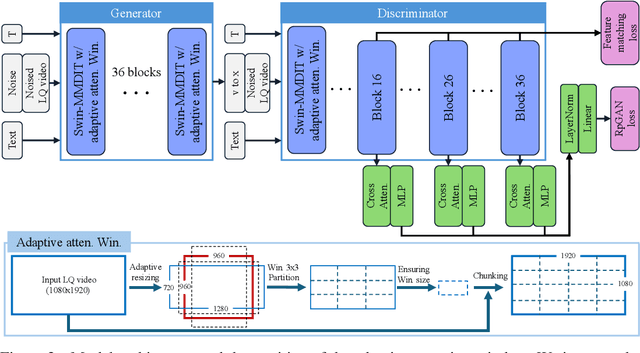
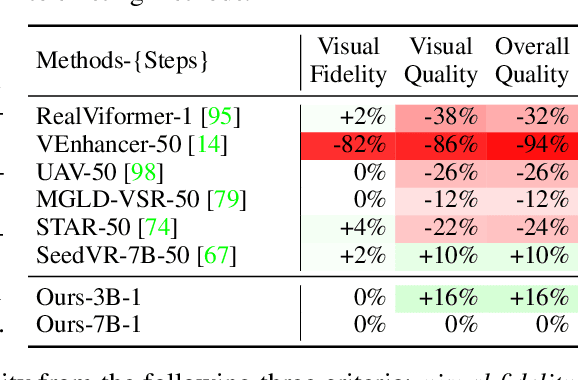
Recent advances in diffusion-based video restoration (VR) demonstrate significant improvement in visual quality, yet yield a prohibitive computational cost during inference. While several distillation-based approaches have exhibited the potential of one-step image restoration, extending existing approaches to VR remains challenging and underexplored, particularly when dealing with high-resolution video in real-world settings. In this work, we propose a one-step diffusion-based VR model, termed as SeedVR2, which performs adversarial VR training against real data. To handle the challenging high-resolution VR within a single step, we introduce several enhancements to both model architecture and training procedures. Specifically, an adaptive window attention mechanism is proposed, where the window size is dynamically adjusted to fit the output resolutions, avoiding window inconsistency observed under high-resolution VR using window attention with a predefined window size. To stabilize and improve the adversarial post-training towards VR, we further verify the effectiveness of a series of losses, including a proposed feature matching loss without significantly sacrificing training efficiency. Extensive experiments show that SeedVR2 can achieve comparable or even better performance compared with existing VR approaches in a single step.