 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transparency Paradox? Investigating the Impact of Explanation Specificity and Autonomous Vehicle Perceptual Inaccuracies on Passengers
Aug 16, 2024Transparency in automated systems could be afforded through the provision of intelligible explanations. While transparency is desirable, might it lead to catastrophic outcomes (such as anxiety), that could outweigh its benefits? It's quite unclear how the specificity of explanations (level of transparency) influences recipients, especially in autonomous driving (AD). In this work, we examined the effects of transparency mediated through varying levels of explanation specificity in AD. We first extended a data-driven explainer model by adding a rule-based option for explanation generation in AD, and then conducted a within-subject lab study with 39 participants in an immersive driving simulator to study the effect of the resulting explanations. Specifically, our investigation focused on: (1) how different types of explanations (specific vs. abstract) affect passengers' perceived safety, anxiety, and willingness to take control of the vehicle when the vehicle perception system makes erroneous predictions; and (2) the relationship between passengers' behavioural cues and their feelings during the autonomous drives. Our findings showed that passengers felt safer with specific explanations when the vehicle's perception system had minimal errors, while abstract explanations that hid perception errors led to lower feelings of safety. Anxiety levels increased when specific explanations revealed perception system errors (high transparency). We found no significant link between passengers' visual patterns and their anxiety levels. Our study suggests that passengers prefer clear and specific explanations (high transparency) when they originate from autonomous vehicles (AVs) with optimal perceptual accuracy.
S-RAF: A Simulation-Based Robustness Assessment Framework for Responsible Autonomous Driving
Aug 16, 2024



As artificial intelligence (AI) technology advances, ensuring the robustness and safety of AI-driven systems has become paramount. However, varying perceptions of robustness among AI developers create misaligned evaluation metrics, complicating the assessment and certification of safety-critical and complex AI systems such as autonomous driving (AD) agents. To address this challenge, we introduce Simulation-Based Robustness Assessment Framework (S-RAF) for autonomous driving. S-RAF leverages the CARLA Driving simulator to rigorously assess AD agents across diverse conditions, including faulty sensors, environmental changes, and complex traffic situations. By quantifying robustness and its relationship with other safety-critical factors, such as carbon emissions, S-RAF aids developers and stakeholders in building safe and responsible driving agents, and streamlining safety certification processes. Furthermore, S-RAF offers significant advantages, such as reduced testing costs, and the ability to explore edge cases that may be unsafe to test in the real world. The code for this framework is available here: https://github.com/cognitive-robots/rai-leaderboard
Learning Run-time Safety Monitors for Machine Learning Components
Jun 23, 2024



For machine learning components used as part of autonomous systems (AS) in carrying out critical tasks it is crucial that assurance of the models can be maintained in the face of post-deployment changes (such as changes in the operating environment of the system). A critical part of this is to be able to monitor when the performance of the model at runtime (as a result of changes) poses a safety risk to the system. This is a particularly difficult challenge when ground truth is unavailable at runtime. In this paper we introduce a process for creating safety monitors for ML components through the use of degraded datasets and machine learning. The safety monitor that is created is deployed to the AS in parallel to the ML component to provide a prediction of the safety risk associated with the model output. We demonstrate the viability of our approach through some initial experiments using publicly available speed sign datasets.
RAG-Driver: Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model
Feb 16, 2024



Robots powered by 'blackbox' models need to provide human-understandable explanations which we can trust. Hence, explainability plays a critical role in trustworthy autonomous decision-making to foster transparency and acceptance among end users, especially in complex autonomous driving. Recent advancements in Multi-Modal Large Language models (MLLMs) have shown promising potential in enhancing the explainability as a driving agent by producing control predictions along with natural language explanations. However, severe data scarcity due to expensive annotation costs and significant domain gaps between different datasets makes the development of a robust and generalisable system an extremely challenging task. Moreover, the prohibitively expensive training requirements of MLLM and the unsolved problem of catastrophic forgetting further limit their generalisability post-deployment. To address these challenges, we present RAG-Driver, a novel retrieval-augmented multi-modal large language model that leverages in-context learning for high-performance, explainable, and generalisable autonomous driving. By grounding in retrieved expert demonstration, we empirically validate that RAG-Driver achieves state-of-the-art performance in producing driving action explanations, justifications, and control signal prediction. More importantly, it exhibits exceptional zero-shot generalisation capabilities to unseen environments without further training endeavours.
CC-SGG: Corner Case Scenario Generation using Learned Scene Graphs
Sep 18, 2023



Corner case scenarios are an essential tool for testing and validating the safety of autonomous vehicles (AVs). As these scenarios are often insufficiently present in naturalistic driving datasets, augmenting the data with synthetic corner cases greatly enhances the safe operation of AVs in unique situations. However, the generation of synthetic, yet realistic, corner cases poses a significant challenge. In this work, we introduce a novel approach based on Heterogeneous Graph Neural Networks (HGNNs) to transform regular driving scenarios into corner cases. To achieve this, we first generate concise representations of regular driving scenes as scene graphs, minimally manipulating their structure and properties. Our model then learns to perturb those graphs to generate corner cases using attention and triple embeddings. The input and perturbed graphs are then imported back into the simulation to generate corner case scenarios. Our model successfully learned to produce corner cases from input scene graphs, achieving 89.9% prediction accuracy on our testing dataset. We further validate the generated scenarios on baseline autonomous driving methods, demonstrating our model's ability to effectively create critical situations for the baselines.
Effects of Explanation Specificity on Passengers in Autonomous Driving
Jul 02, 2023
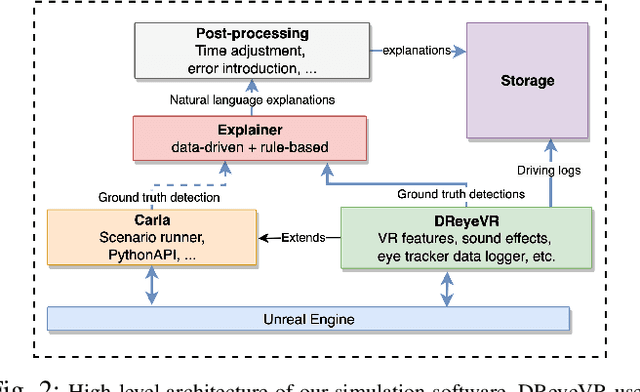
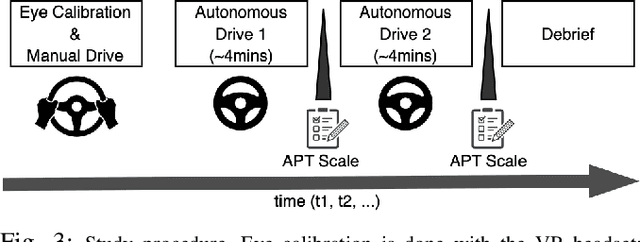
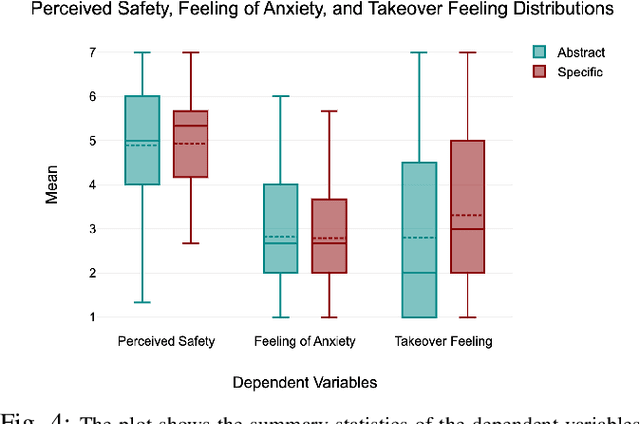
The nature of explanations provided by an explainable AI algorithm has been a topic of interest in the explainable AI and human-computer interaction community. In this paper, we investigate the effects of natural language explanations' specificity on passengers in autonomous driving. We extended an existing data-driven tree-based explainer algorithm by adding a rule-based option for explanation generation. We generated auditory natural language explanations with different levels of specificity (abstract and specific) and tested these explanations in a within-subject user study (N=39) using an immersive physical driving simulation setup. Our results showed that both abstract and specific explanations had similar positive effects on passengers' perceived safety and the feeling of anxiety. However, the specific explanations influenced the desire of passengers to takeover driving control from the autonomous vehicle (AV), while the abstract explanations did not. We conclude that natural language auditory explanations are useful for passengers in autonomous driving, and their specificity levels could influence how much in-vehicle participants would wish to be in control of the driving activity.
Textual Explanations for Automated Commentary Driving
Apr 12, 2023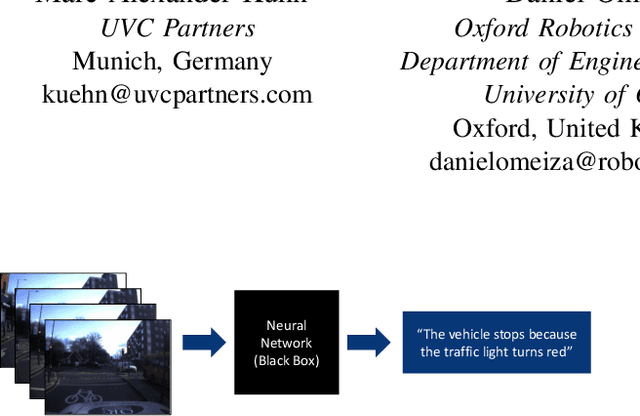
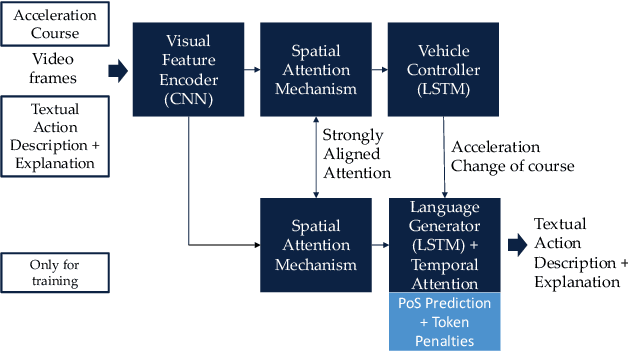

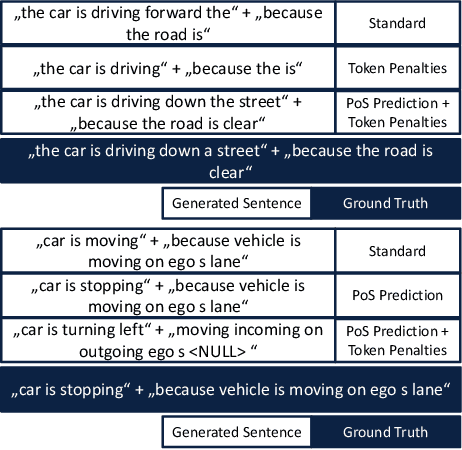
The provision of natural language explanations for the predictions of deep-learning-based vehicle controllers is critical as it enhances transparency and easy audit. In this work, a state-of-the-art (SOTA) prediction and explanation model is thoroughly evaluated and validated (as a benchmark) on the new Sense--Assess--eXplain (SAX). Additionally, we developed a new explainer model that improved over the baseline architecture in two ways: (i) an integration of part of speech prediction and (ii) an introduction of special token penalties. On the BLEU metric, our explanation generation technique outperformed SOTA by a factor of 7.7 when applied on the BDD-X dataset. The description generation technique is also improved by a factor of 1.3. Hence, our work contributes to the realisation of future explainable autonomous vehicles.
Explainable Action Prediction through Self-Supervision on Scene Graphs
Feb 07, 2023



This work explores scene graphs as a distilled representation of high-level information for autonomous driving, applied to future driver-action prediction. Given the scarcity and strong imbalance of data samples, we propose a self-supervision pipeline to infer representative and well-separated embeddings. Key aspects are interpretability and explainability; as such, we embed in our architecture attention mechanisms that can create spatial and temporal heatmaps on the scene graphs. We evaluate our system on the ROAD dataset against a fully-supervised approach, showing the superiority of our training regime.
From Spoken Thoughts to Automated Driving Commentary: Predicting and Explaining Intelligent Vehicles' Actions
Apr 19, 2022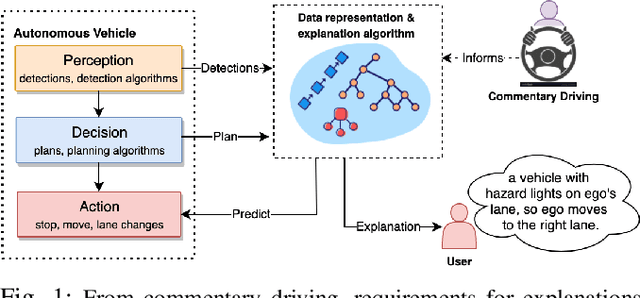
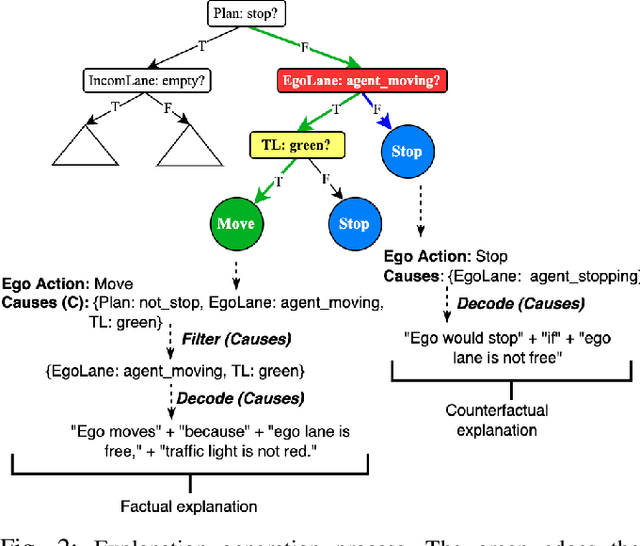
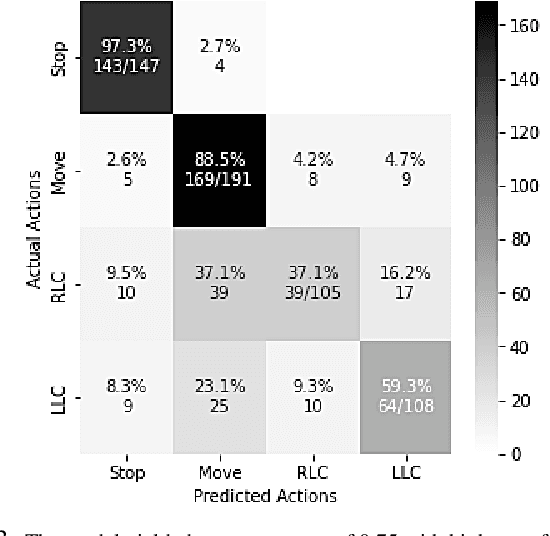

Commentary driving is a technique in which drivers verbalise their observations, assessments and intentions. By speaking out their thoughts, both learning and expert drivers are able to create a better understanding and awareness of their surroundings. In the intelligent vehicle context, automated driving commentary can provide intelligible explanations about driving actions, and thereby assist a driver or an end-user during driving operations in challenging and safety-critical scenarios. In this paper, we conducted a field study in which we deployed a research vehicle in an urban environment to obtain data. While collecting sensor data of the vehicle's surroundings, we obtained driving commentary from a driving instructor using the think-aloud protocol. We analysed the driving commentary and uncovered an explanation style; the driver first announces his observations, announces his plans, and then makes general remarks. He also made counterfactual comments. We successfully demonstrated how factual and counterfactual natural language explanations that follow this style could be automatically generated using a simple tree-based approach. Generated explanations for longitudinal actions (e.g., stop and move) were deemed more intelligible and plausible by human judges compared to lateral actions, such as lane changes. We discussed how our approach can be built on in the future to realise more robust and effective explainability for driver assistance as well as partial and conditional automation of driving functions.
Explanations in Autonomous Driving: A Survey
Mar 11, 2021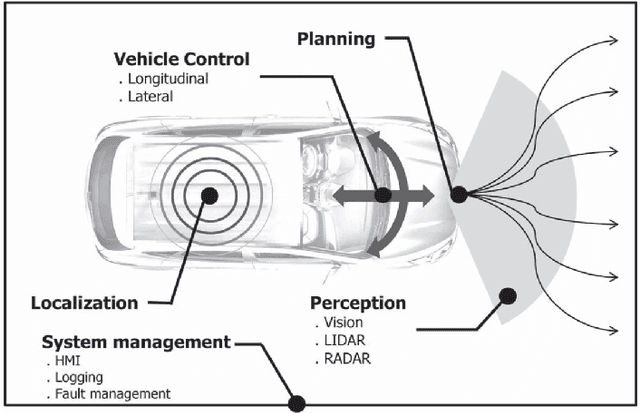


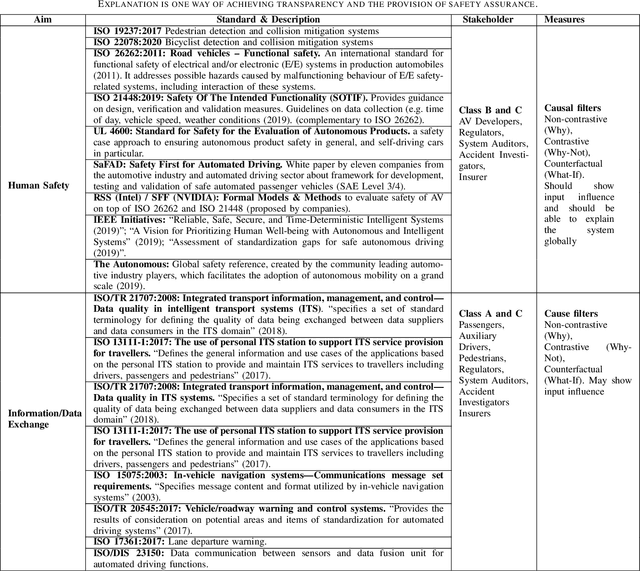
The automotive industry is seen to have witnessed an increasing level of development in the past decades; from manufacturing manually operated vehicles to manufacturing vehicles with high level of automation. With the recent developments in Artificial Intelligence (AI), automotive companies now employ high performance AI models to enable vehicles to perceive their environment and make driving decisions with little or no influence from a human. With the hope to deploy autonomous vehicles (AV) on a commercial scale, the acceptance of AV by society becomes paramount and may largely depend on their degree of transparency, trustworthiness, and compliance to regulations. The assessment of these acceptance requirements can be facilitated through the provision of explanations for AVs' behaviour. Explainability is therefore seen as an important requirement for AVs. AVs should be able to explain what they have 'seen', done and might do in environments where they operate. In this paper, we provide a comprehensive survey of the existing work in explainable autonomous driving. First, we open by providing a motivation for explanations and examining existing standards related to AVs. Second, we identify and categorise the different stakeholders involved in the development, use, and regulation of AVs and show their perceived need for explanation. Third, we provide a taxonomy of explanations and reviewed previous work on explanation in the different AV operations. Finally, we draw a close by pointing out pertinent challenges and future research directions. This survey serves to provide fundamental knowledge required of researchers who are interested in explanation in autonomous driving.