 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Generators are Generalist Vision Learners
Apr 22, 2026Recent works show that image and video generators exhibit zero-shot visual understanding behaviors, in a way reminiscent of how LLMs develop emergent capabilities of language understanding and reasoning from generative pretraining. While it has long been conjectured that the ability to create visual content implies an ability to understand it, there has been limited evidence that generative vision models have developed strong understanding capabilities. In this work, we demonstrate that image generation training serves a role similar to LLM pretraining, and lets models learn powerful and general visual representations that enable SOTA performance on various vision tasks. We introduce Vision Banana, a generalist model built by instruction-tuning Nano Banana Pro (NBP) on a mixture of its original training data alongside a small amount of vision task data. By parameterizing the output space of vision tasks as RGB images, we seamlessly reframe perception as image generation. Our generalist model, Vision Banana, achieves SOTA results on a variety of vision tasks involving both 2D and 3D understanding, beating or rivaling zero-shot domain-specialists, including Segment Anything Model 3 on segmentation tasks, and the Depth Anything series on metric depth estimation. We show that these results can be achieved with lightweight instruction-tuning without sacrificing the base model's image generation capabilities. The superior results suggest that image generation pretraining is a generalist vision learner. It also shows that image generation serves as a unified and universal interface for vision tasks, similar to text generation's role in language understanding and reasoning. We could be witnessing a major paradigm shift for computer vision, where generative vision pretraining takes a central role in building Foundational Vision Models for both generation and understanding.
When AI Meets Early Childhood Education: Large Language Models as Assessment Teammates in Chinese Preschools
Mar 25, 2026High-quality teacher-child interaction (TCI) is fundamental to early childhood development, yet traditional expert-based assessment faces a critical scalability challenge. In large systems like China's-serving 36 million children across 250,000+ kindergartens-the cost and time requirements of manual observation make continuous quality monitoring infeasible, relegating assessment to infrequent episodic audits that limit timely intervention and improvement tracking. In this paper, we investigate whether AI can serve as a scalable assessment teammate by extracting structured quality indicators and validating their alignment with human expert judgments. Our contributions include: (1) TEPE-TCI-370h (Tracing Effective Preschool Education), the first large-scale dataset of naturalistic teacher-child interactions in Chinese preschools (370 hours, 105 classrooms) with standardized ECQRS-EC and SSTEW annotations; (2) We develop Interaction2Eval, a specialized LLM-based framework addressing domain-specific challenges-child speech recognition, Mandarin homophone disambiguation, and rubric-based reasoning-achieving up to 88% agreement; (3) Deployment validation across 43 classrooms demonstrating an 18x efficiency gain in the assessment workflow, highlighting its potential for shifting from annual expert audits to monthly AI-assisted monitoring with targeted human oversight. This work not only demonstrates the technical feasibility of scalable, AI-augmented quality assessment but also lays the foundation for a new paradigm in early childhood education-one where continuous, inclusive, AI-assisted evaluation becomes the engine of systemic improvement and equitable growth.
Robot Learning from a Physical World Model
Nov 10, 2025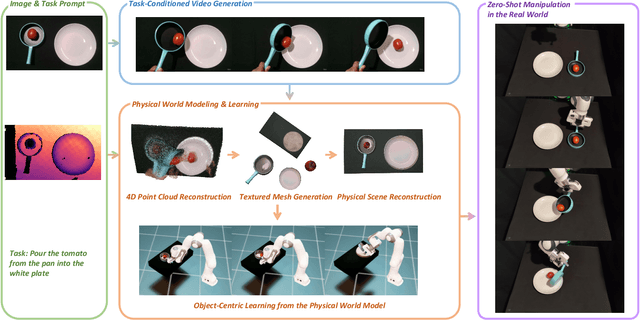

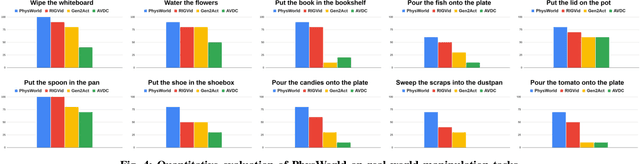

We introduce PhysWorld, a framework that enables robot learning from video generation through physical world modeling. Recent video generation models can synthesize photorealistic visual demonstrations from language commands and images, offering a powerful yet underexplored source of training signals for robotics. However, directly retargeting pixel motions from generated videos to robots neglects physics, often resulting in inaccurate manipulations. PhysWorld addresses this limitation by coupling video generation with physical world reconstruction. Given a single image and a task command, our method generates task-conditioned videos and reconstructs the underlying physical world from the videos, and the generated video motions are grounded into physically accurate actions through object-centric residual reinforcement learning with the physical world model. This synergy transforms implicit visual guidance into physically executable robotic trajectories, eliminating the need for real robot data collection and enabling zero-shot generalizable robotic manipulation. Experiments on diverse real-world tasks demonstrate that PhysWorld substantially improves manipulation accuracy compared to previous approaches. Visit \href{https://pointscoder.github.io/PhysWorld_Web/}{the project webpage} for details.
FirePlace: Geometric Refinements of LLM Common Sense Reasoning for 3D Object Placement
Mar 06, 2025Scene generation with 3D assets presents a complex challenge, requiring both high-level semantic understanding and low-level geometric reasoning. While Multimodal Large Language Models (MLLMs) excel at semantic tasks, their application to 3D scene generation is hindered by their limited grounding on 3D geometry. In this paper, we investigate how to best work with MLLMs in an object placement task. Towards this goal, we introduce a novel framework, FirePlace, that applies existing MLLMs in (1) 3D geometric reasoning and the extraction of relevant geometric details from the 3D scene, (2) constructing and solving geometric constraints on the extracted low-level geometry, and (3) pruning for final placements that conform to common sense. By combining geometric reasoning with real-world understanding of MLLMs, our method can propose object placements that satisfy both geometric constraints as well as high-level semantic common-sense considerations. Our experiments show that these capabilities allow our method to place objects more effectively in complex scenes with intricate geometry, surpassing the quality of prior work.