 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoRemover: Automatic Object Removal for Autonomous Driving Videos
Nov 28, 2019
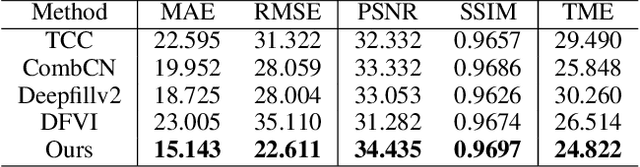
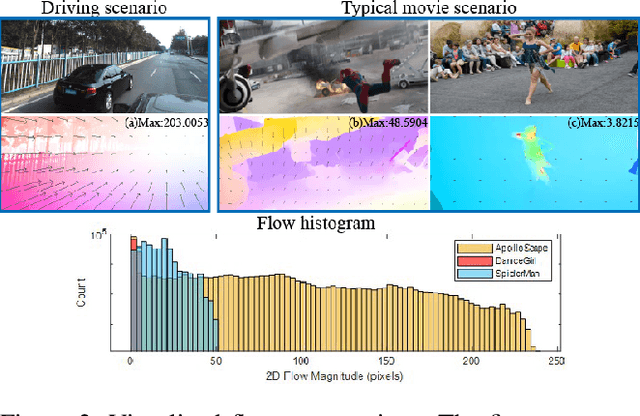
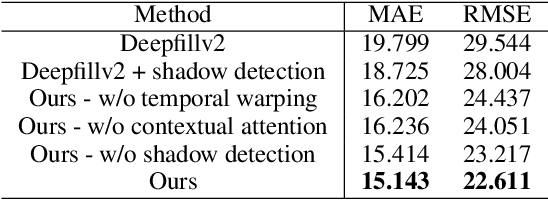
Motivated by the need for photo-realistic simulation in autonomous driving, in this paper we present a video inpainting algorithm \emph{AutoRemover}, designed specifically for generating street-view videos without any moving objects. In our setup we have two challenges: the first is the shadow, shadows are usually unlabeled but tightly coupled with the moving objects. The second is the large ego-motion in the videos. To deal with shadows, we build up an autonomous driving shadow dataset and design a deep neural network to detect shadows automatically. To deal with large ego-motion, we take advantage of the multi-source data, in particular the 3D data, in autonomous driving. More specifically, the geometric relationship between frames is incorporated into an inpainting deep neural network to produce high-quality structurally consistent video output. Experiments show that our method outperforms other state-of-the-art (SOTA) object removal algorithms, reducing the RMSE by over $19\%$.
CSPN++: Learning Context and Resource Aware Convolutional Spatial Propagation Networks for Depth Completion
Nov 22, 2019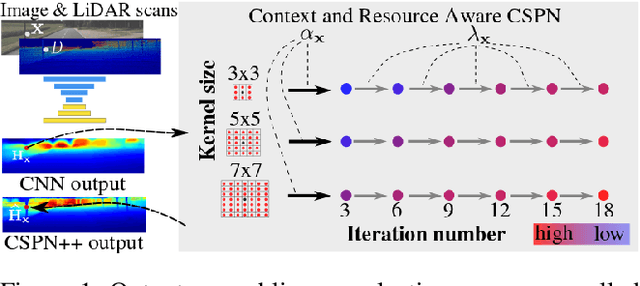

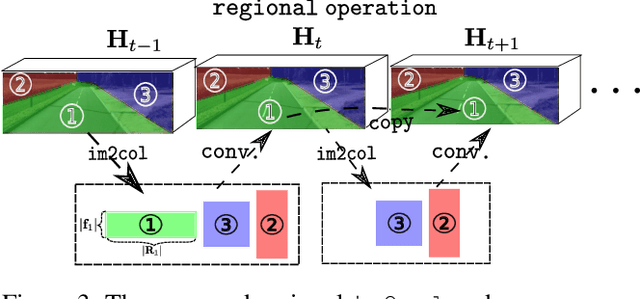
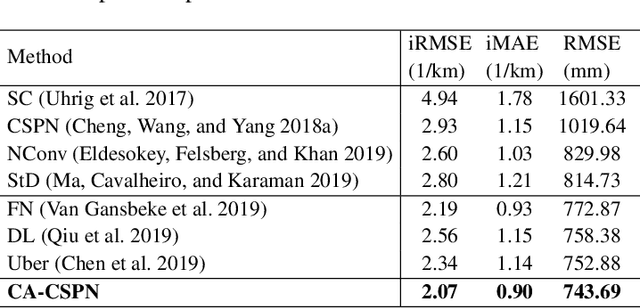
Depth Completion deals with the problem of converting a sparse depth map to a dense one, given the corresponding color image. Convolutional spatial propagation network (CSPN) is one of the state-of-the-art (SoTA) methods of depth completion, which recovers structural details of the scene. In this paper, we propose CSPN++, which further improves its effectiveness and efficiency by learning adaptive convolutional kernel sizes and the number of iterations for the propagation, thus the context and computational resources needed at each pixel could be dynamically assigned upon requests. Specifically, we formulate the learning of the two hyper-parameters as an architecture selection problem where various configurations of kernel sizes and numbers of iterations are first defined, and then a set of soft weighting parameters are trained to either properly assemble or select from the pre-defined configurations at each pixel. In our experiments, we find weighted assembling can lead to significant accuracy improvements, which we referred to as "context-aware CSPN", while weighted selection, "resource-aware CSPN" can reduce the computational resource significantly with similar or better accuracy. Besides, the resource needed for CSPN++ can be adjusted w.r.t. the computational budget automatically. Finally, to avoid the side effects of noise or inaccurate sparse depths, we embed a gated network inside CSPN++, which further improves the performance. We demonstrate the effectiveness of CSPN++on the KITTI depth completion benchmark, where it significantly improves over CSPN and other SoTA methods.
Learning Resilient Behaviors for Navigation Under Uncertainty Environments
Oct 22, 2019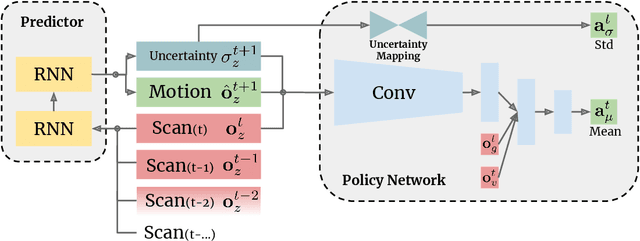
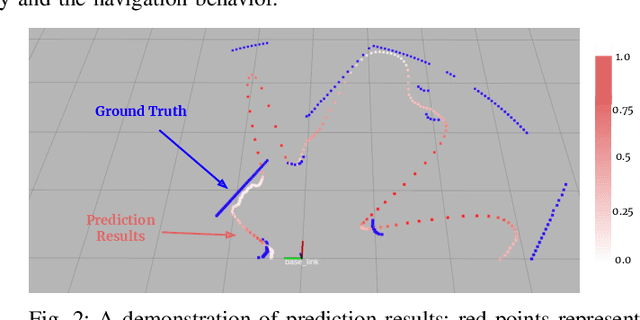
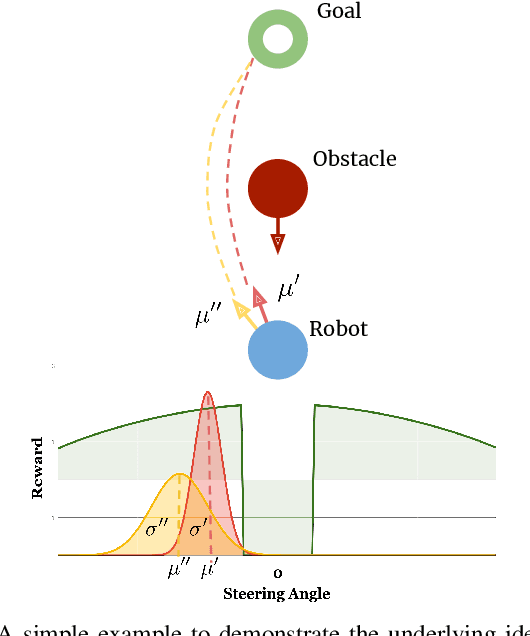
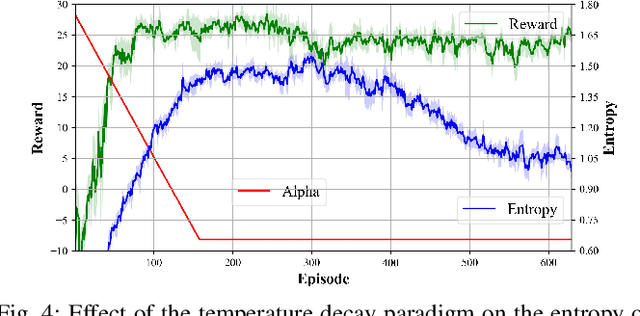
Deep reinforcement learning has great potential to acquire complex, adaptive behaviors for autonomous agents automatically. However, the underlying neural network polices have not been widely deployed in real-world applications, especially in these safety-critical tasks (e.g., autonomous driving). One of the reasons is that the learned policy cannot perform flexible and resilient behaviors as traditional methods to adapt to diverse environments. In this paper, we consider the problem that a mobile robot learns adaptive and resilient behaviors for navigating in unseen uncertain environments while avoiding collisions. We present a novel approach for uncertainty-aware navigation by introducing an uncertainty-aware predictor to model the environmental uncertainty, and we propose a novel uncertainty-aware navigation network to learn resilient behaviors in the prior unknown environments. To train the proposed uncertainty-aware network more stably and efficiently, we present the temperature decay training paradigm, which balances exploration and exploitation during the training process. Our experimental evaluation demonstrates that our approach can learn resilient behaviors in diverse environments and generate adaptive trajectories according to environmental uncertainties.
Improved Techniques for Training Adaptive Deep Networks
Aug 17, 2019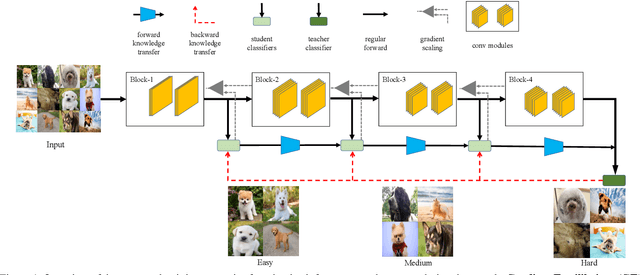
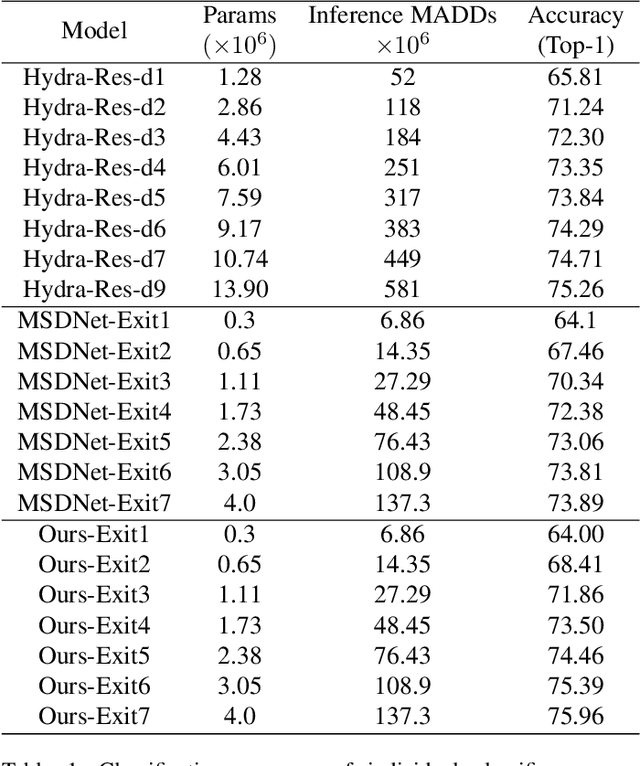
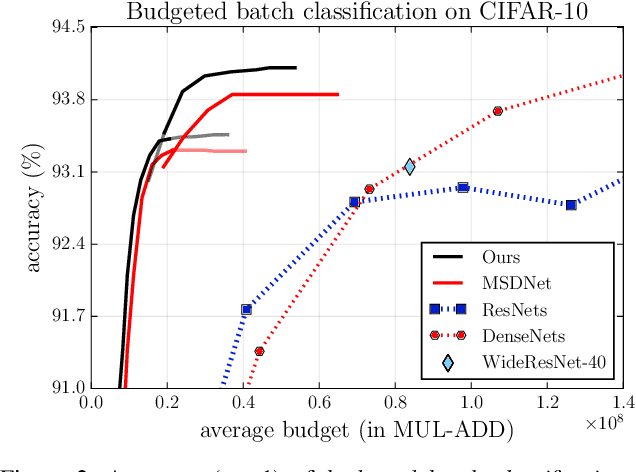
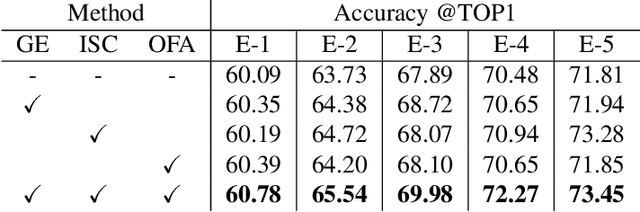
Adaptive inference is a promising technique to improve the computational efficiency of deep models at test time. In contrast to static models which use the same computation graph for all instances, adaptive networks can dynamically adjust their structure conditioned on each input. While existing research on adaptive inference mainly focuses on designing more advanced architectures, this paper investigates how to train such networks more effectively. Specifically, we consider a typical adaptive deep network with multiple intermediate classifiers. We present three techniques to improve its training efficacy from two aspects: 1) a Gradient Equilibrium algorithm to resolve the conflict of learning of different classifiers; 2) an Inline Subnetwork Collaboration approach and a One-for-all Knowledge Distillation algorithm to enhance the collaboration among classifiers. On multiple datasets (CIFAR-10, CIFAR-100 and ImageNet), we show that the proposed approach consistently leads to further improved efficiency on top of state-of-the-art adaptive deep networks.
IoU Loss for 2D/3D Object Detection
Aug 11, 2019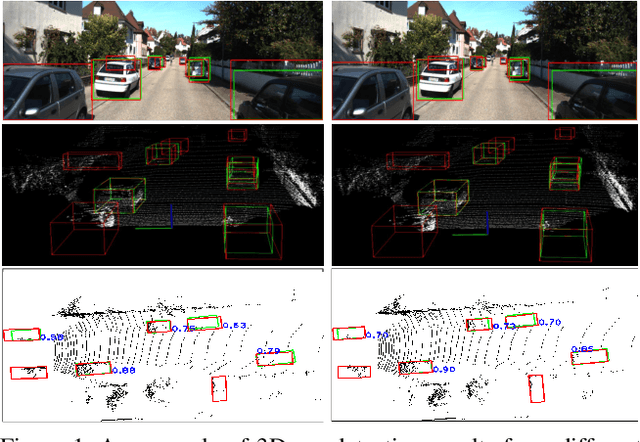

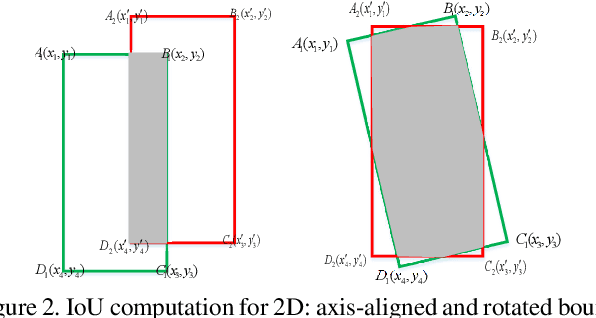
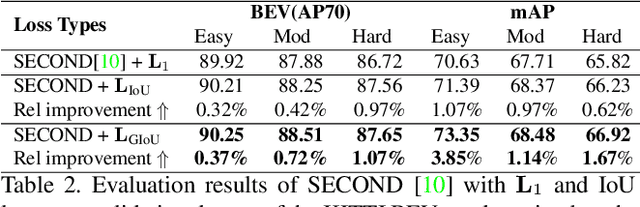
In 2D/3D object detection task, Intersection-over-Union (IoU) has been widely employed as an evaluation metric to evaluate the performance of different detectors in the testing stage. However, during the training stage, the common distance loss (\eg, $L_1$ or $L_2$) is often adopted as the loss function to minimize the discrepancy between the predicted and ground truth Bounding Box (Bbox). To eliminate the performance gap between training and testing, the IoU loss has been introduced for 2D object detection in \cite{yu2016unitbox} and \cite{rezatofighi2019generalized}. Unfortunately, all these approaches only work for axis-aligned 2D Bboxes, which cannot be applied for more general object detection task with rotated Bboxes. To resolve this issue, we investigate the IoU computation for two rotated Bboxes first and then implement a unified framework, IoU loss layer for both 2D and 3D object detection tasks. By integrating the implemented IoU loss into several state-of-the-art 3D object detectors, consistent improvements have been achieved for both bird-eye-view 2D detection and point cloud 3D detection on the public KITTI benchmark.
Adversarial Objects Against LiDAR-Based Autonomous Driving Systems
Jul 11, 2019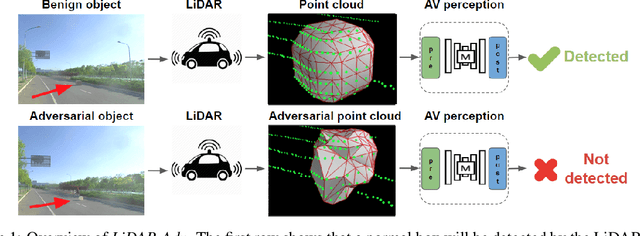


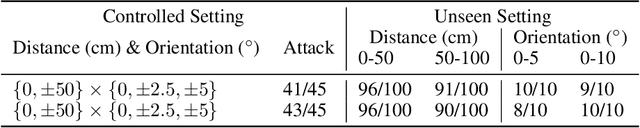
Deep neural networks (DNNs) are found to be vulnerable against adversarial examples, which are carefully crafted inputs with a small magnitude of perturbation aiming to induce arbitrarily incorrect predictions. Recent studies show that adversarial examples can pose a threat to real-world security-critical applications: a "physical adversarial Stop Sign" can be synthesized such that the autonomous driving cars will misrecognize it as others (e.g., a speed limit sign). However, these image-space adversarial examples cannot easily alter 3D scans of widely equipped LiDAR or radar on autonomous vehicles. In this paper, we reveal the potential vulnerabilities of LiDAR-based autonomous driving detection systems, by proposing an optimization based approach LiDAR-Adv to generate adversarial objects that can evade the LiDAR-based detection system under various conditions. We first show the vulnerabilities using a blackbox evolution-based algorithm, and then explore how much a strong adversary can do, using our gradient-based approach LiDAR-Adv. We test the generated adversarial objects on the Baidu Apollo autonomous driving platform and show that such physical systems are indeed vulnerable to the proposed attacks. We also 3D-print our adversarial objects and perform physical experiments to illustrate that such vulnerability exists in the real world. Please find more visualizations and results on the anonymous website: https://sites.google.com/view/lidar-adv.
Detailed Human Shape Estimation from a Single Image by Hierarchical Mesh Deformation
May 08, 2019
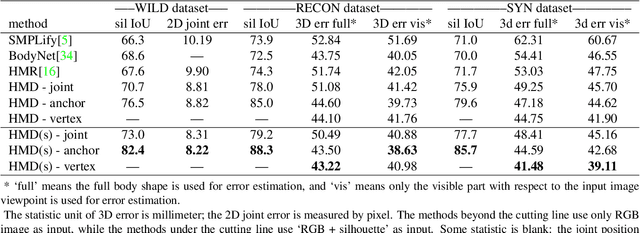

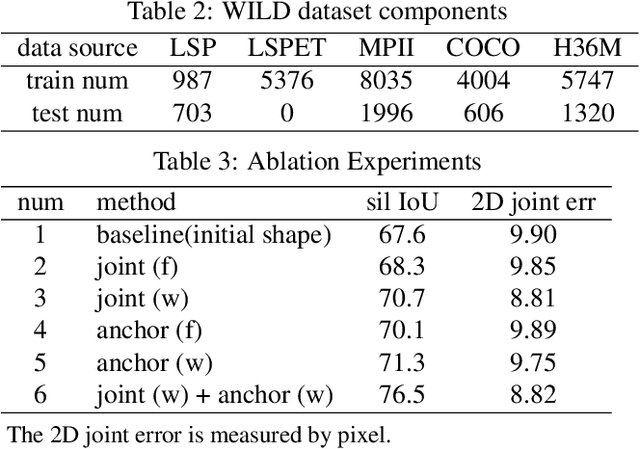
This paper presents a novel framework to recover detailed human body shapes from a single image. It is a challenging task due to factors such as variations in human shapes, body poses, and viewpoints. Prior methods typically attempt to recover the human body shape using a parametric based template that lacks the surface details. As such the resulting body shape appears to be without clothing. In this paper, we propose a novel learning-based framework that combines the robustness of parametric model with the flexibility of free-form 3D deformation. We use the deep neural networks to refine the 3D shape in a Hierarchical Mesh Deformation (HMD) framework, utilizing the constraints from body joints, silhouettes, and per-pixel shading information. We are able to restore detailed human body shapes beyond skinned models. Experiments demonstrate that our method has outperformed previous state-of-the-art approaches, achieving better accuracy in terms of both 2D IoU number and 3D metric distance. The code is available in https://github.com/zhuhao-nju/hmd.git
GA-Net: Guided Aggregation Net for End-to-end Stereo Matching
Apr 13, 2019
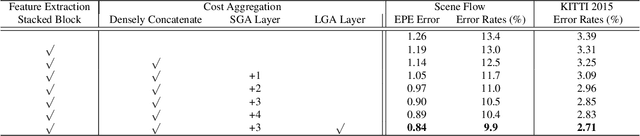
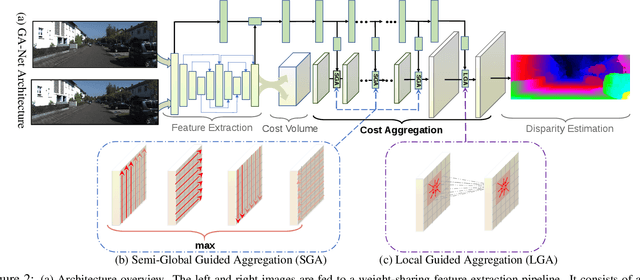
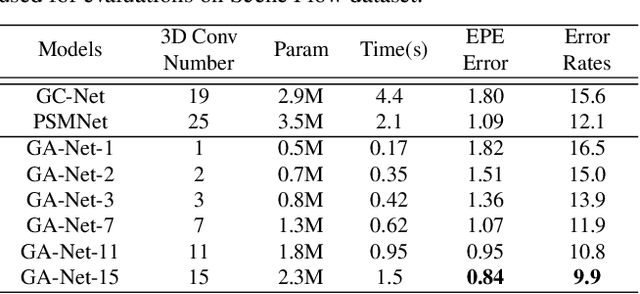
In the stereo matching task, matching cost aggregation is crucial in both traditional methods and deep neural network models in order to accurately estimate disparities. We propose two novel neural net layers, aimed at capturing local and the whole-image cost dependencies respectively. The first is a semi-global aggregation layer which is a differentiable approximation of the semi-global matching, the second is the local guided aggregation layer which follows a traditional cost filtering strategy to refine thin structures. These two layers can be used to replace the widely used 3D convolutional layer which is computationally costly and memory-consuming as it has cubic computational/memory complexity. In the experiments, we show that nets with a two-layer guided aggregation block easily outperform the state-of-the-art GC-Net which has nineteen 3D convolutional layers. We also train a deep guided aggregation network (GA-Net) which gets better accuracies than state-of-the-art methods on both Scene Flow dataset and KITTI benchmarks.
TrafficPredict: Trajectory Prediction for Heterogeneous Traffic-Agents
Apr 09, 2019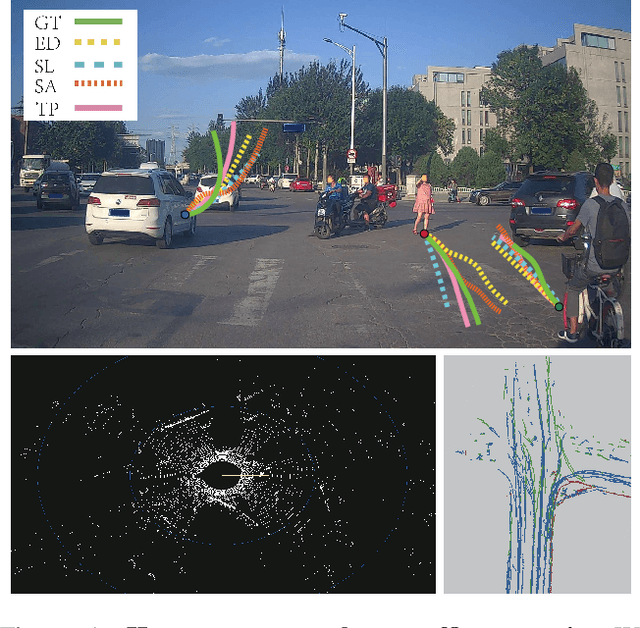
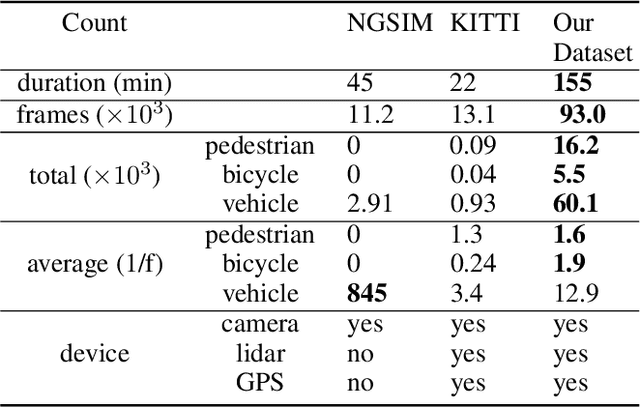
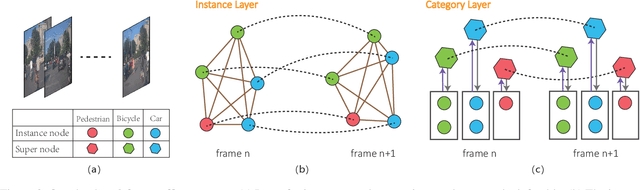
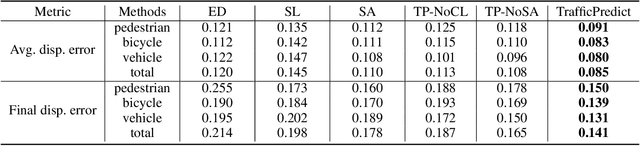
To safely and efficiently navigate in complex urban traffic, autonomous vehicles must make responsible predictions in relation to surrounding traffic-agents (vehicles, bicycles, pedestrians, etc.). A challenging and critical task is to explore the movement patterns of different traffic-agents and predict their future trajectories accurately to help the autonomous vehicle make reasonable navigation decision. To solve this problem, we propose a long short-term memory-based (LSTM-based) realtime traffic prediction algorithm, TrafficPredict. Our approach uses an instance layer to learn instances' movements and interactions and has a category layer to learn the similarities of instances belonging to the same type to refine the prediction. In order to evaluate its performance, we collected trajectory datasets in a large city consisting of varying conditions and traffic densities. The dataset includes many challenging scenarios where vehicles, bicycles, and pedestrians move among one another. We evaluate the performance of TrafficPredict on our new dataset and highlight its higher accuracy for trajectory prediction by comparing with prior prediction methods.
AADS: Augmented Autonomous Driving Simulation using Data-driven Algorithms
Jan 23, 2019



Simulation systems have become an essential component in the development and validation of autonomous driving technologies. The prevailing state-of-the-art approach for simulation is to use game engines or high-fidelity computer graphics (CG) models to create driving scenarios. However, creating CG models and vehicle movements (e.g., the assets for simulation) remains a manual task that can be costly and time-consuming. In addition, the fidelity of CG images still lacks the richness and authenticity of real-world images and using these images for training leads to degraded performance. In this paper we present a novel approach to address these issues: Augmented Autonomous Driving Simulation (AADS). Our formulation augments real-world pictures with a simulated traffic flow to create photo-realistic simulation images and renderings. More specifically, we use LiDAR and cameras to scan street scenes. From the acquired trajectory data, we generate highly plausible traffic flows for cars and pedestrians and compose them into the background. The composite images can be re-synthesized with different viewpoints and sensor models. The resulting images are photo-realistic, fully annotated, and ready for end-to-end training and testing of autonomous driving systems from perception to planning. We explain our system design and validate our algorithms with a number of autonomous driving tasks from detection to segmentation and predictions. Compared to traditional approaches, our method offers unmatched scalability and realism. Scalability is particularly important for AD simulation and we believe the complexity and diversity of the real world cannot be realistically captured in a virtual environment. Our augmented approach combines the flexibility in a virtual environment (e.g., vehicle movements) with the richness of the real world to allow effective simulation of anywhere on earth.