 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALOcc: Adaptive Lifting-based 3D Semantic Occupancy and Cost Volume-based Flow Prediction
Nov 12, 2024Vision-based semantic occupancy and flow prediction plays a crucial role in providing spatiotemporal cues for real-world tasks, such as autonomous driving. Existing methods prioritize higher accuracy to cater to the demands of these tasks. In this work, we strive to improve performance by introducing a series of targeted improvements for 3D semantic occupancy prediction and flow estimation. First, we introduce an occlusion-aware adaptive lifting mechanism with a depth denoising technique to improve the robustness of 2D-to-3D feature transformation and reduce the reliance on depth priors. Second, we strengthen the semantic consistency between 3D features and their original 2D modalities by utilizing shared semantic prototypes to jointly constrain both 2D and 3D features. This is complemented by confidence- and category-based sampling strategies to tackle long-tail challenges in 3D space. To alleviate the feature encoding burden in the joint prediction of semantics and flow, we propose a BEV cost volume-based prediction method that links flow and semantic features through a cost volume and employs a classification-regression supervision scheme to address the varying flow scales in dynamic scenes. Our purely convolutional architecture framework, named ALOcc, achieves an optimal tradeoff between speed and accuracy achieving state-of-the-art results on multiple benchmarks. On Occ3D and training without the camera visible mask, our ALOcc achieves an absolute gain of 2.5\% in terms of RayIoU while operating at a comparable speed compared to the state-of-the-art, using the same input size (256$\times$704) and ResNet-50 backbone. Our method also achieves 2nd place in the CVPR24 Occupancy and Flow Prediction Competition.
Annotator: A Generic Active Learning Baseline for LiDAR Semantic Segmentation
Oct 31, 2023



Active learning, a label-efficient paradigm, empowers models to interactively query an oracle for labeling new data. In the realm of LiDAR semantic segmentation, the challenges stem from the sheer volume of point clouds, rendering annotation labor-intensive and cost-prohibitive. This paper presents Annotator, a general and efficient active learning baseline, in which a voxel-centric online selection strategy is tailored to efficiently probe and annotate the salient and exemplar voxel girds within each LiDAR scan, even under distribution shift. Concretely, we first execute an in-depth analysis of several common selection strategies such as Random, Entropy, Margin, and then develop voxel confusion degree (VCD) to exploit the local topology relations and structures of point clouds. Annotator excels in diverse settings, with a particular focus on active learning (AL), active source-free domain adaptation (ASFDA), and active domain adaptation (ADA). It consistently delivers exceptional performance across LiDAR semantic segmentation benchmarks, spanning both simulation-to-real and real-to-real scenarios. Surprisingly, Annotator exhibits remarkable efficiency, requiring significantly fewer annotations, e.g., just labeling five voxels per scan in the SynLiDAR-to-SemanticKITTI task. This results in impressive performance, achieving 87.8% fully-supervised performance under AL, 88.5% under ASFDA, and 94.4% under ADA. We envision that Annotator will offer a simple, general, and efficient solution for label-efficient 3D applications. Project page: https://binhuixie.github.io/annotator-web
VBLC: Visibility Boosting and Logit-Constraint Learning for Domain Adaptive Semantic Segmentation under Adverse Conditions
Nov 22, 2022



Generalizing models trained on normal visual conditions to target domains under adverse conditions is demanding in the practical systems. One prevalent solution is to bridge the domain gap between clear- and adverse-condition images to make satisfactory prediction on the target. However, previous methods often reckon on additional reference images of the same scenes taken from normal conditions, which are quite tough to collect in reality. Furthermore, most of them mainly focus on individual adverse condition such as nighttime or foggy, weakening the model versatility when encountering other adverse weathers. To overcome the above limitations, we propose a novel framework, Visibility Boosting and Logit-Constraint learning (VBLC), tailored for superior normal-to-adverse adaptation. VBLC explores the potential of getting rid of reference images and resolving the mixture of adverse conditions simultaneously. In detail, we first propose the visibility boost module to dynamically improve target images via certain priors in the image level. Then, we figure out the overconfident drawback in the conventional cross-entropy loss for self-training method and devise the logit-constraint learning, which enforces a constraint on logit outputs during training to mitigate this pain point. To the best of our knowledge, this is a new perspective for tackling such a challenging task. Extensive experiments on two normal-to-adverse domain adaptation benchmarks, i.e., Cityscapes -> ACDC and Cityscapes -> FoggyCityscapes + RainCityscapes, verify the effectiveness of VBLC, where it establishes the new state of the art. Code is available at https://github.com/BIT-DA/VBLC.
Active Learning for Domain Adaptation: An Energy-based Approach
Dec 08, 2021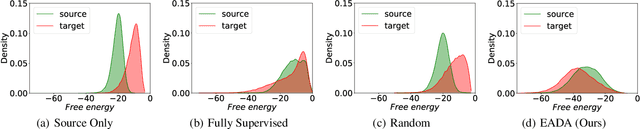
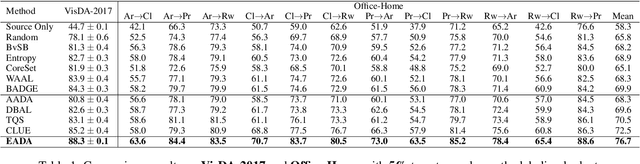
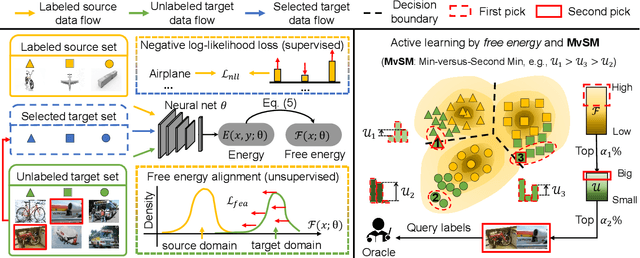
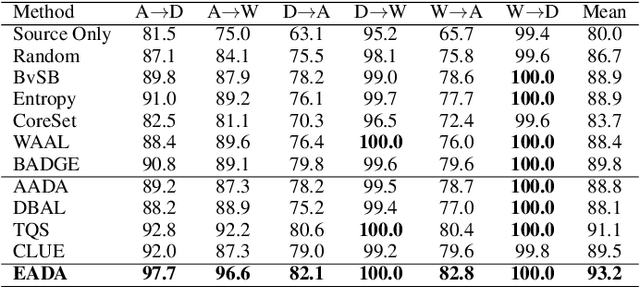
Unsupervised domain adaptation has recently emerged as an effective paradigm for generalizing deep neural networks to new target domains. However, there is still enormous potential to be tapped to reach the fully supervised performance. In this paper, we present a novel active learning strategy to assist knowledge transfer in the target domain, dubbed active domain adaptation. We start from an observation that energy-based models exhibit free energy biases when training (source) and test (target) data come from different distributions. Inspired by this inherent mechanism, we empirically reveal that a simple yet efficient energy-based sampling strategy sheds light on selecting the most valuable target samples than existing approaches requiring particular architectures or computation of the distances. Our algorithm, Energy-based Active Domain Adaptation (EADA), queries groups of targe data that incorporate both domain characteristic and instance uncertainty into every selection round. Meanwhile, by aligning the free energy of target data compact around the source domain via a regularization term, domain gap can be implicitly diminished. Through extensive experiments, we show that EADA surpasses state-of-the-art methods on well-known challenging benchmarks with substantial improvements, making it a useful option in the open world. Code is available at https://github.com/BIT-DA/EADA.
Towards Fewer Annotations: Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation
Nov 25, 2021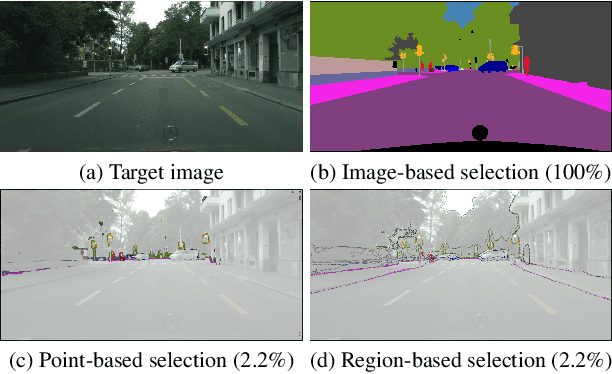
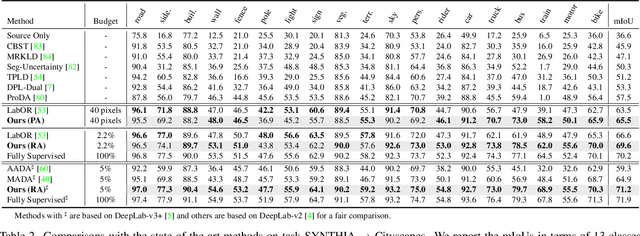
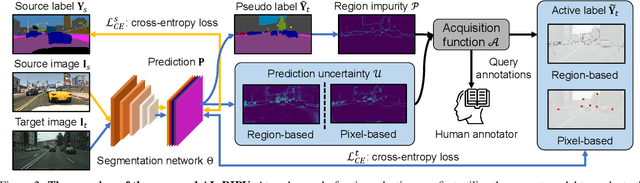
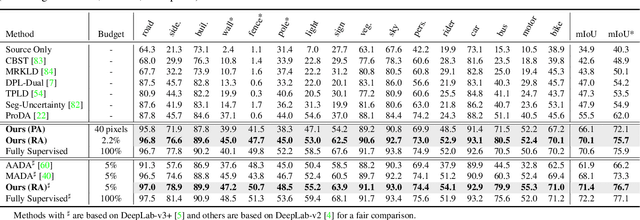
Self-training has greatly facilitated domain adaptive semantic segmentation, which iteratively generates pseudo labels on the target domain and retrains the network. However, since the realistic segmentation datasets are highly imbalanced, target pseudo labels are typically biased to the majority classes and basically noisy, leading to an error-prone and sub-optimal model. To address this issue, we propose a region-based active learning approach for semantic segmentation under a domain shift, aiming to automatically query a small partition of image regions to be labeled while maximizing segmentation performance. Our algorithm, Active Learning via Region Impurity and Prediction Uncertainty (AL-RIPU), introduces a novel acquisition strategy characterizing the spatial adjacency of image regions along with the prediction confidence. We show that the proposed region-based selection strategy makes more efficient use of a limited budget than image-based or point-based counterparts. Meanwhile, we enforce local prediction consistency between a pixel and its nearest neighbor on a source image. Further, we develop a negative learning loss to enhance the discriminative representation learning on the target domain. Extensive experiments demonstrate that our method only requires very few annotations to almost reach the supervised performance and substantially outperforms state-of-the-art methods.
Semantic Distribution-aware Contrastive Adaptation for Semantic Segmentation
May 11, 2021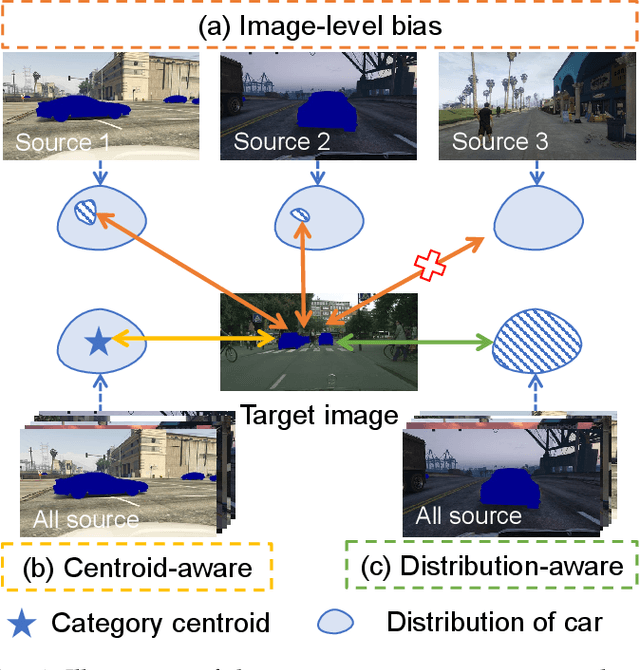
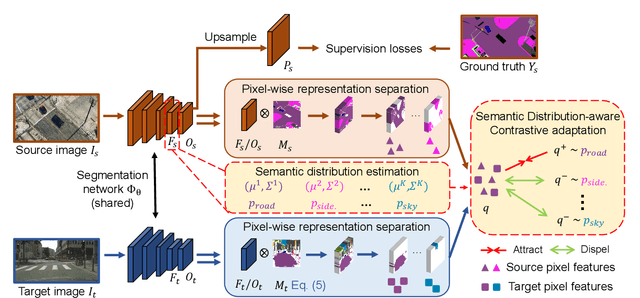
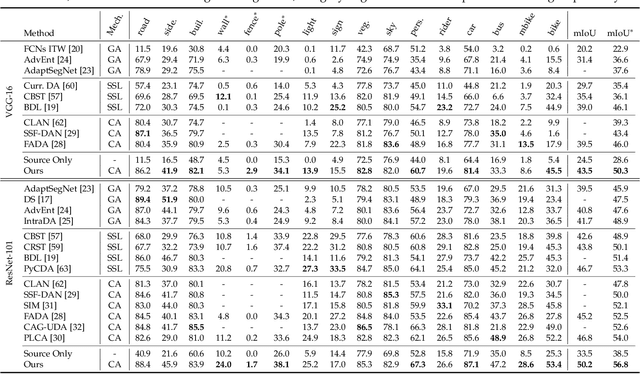
Domain adaptive semantic segmentation refers to making predictions on a certain target domain with only annotations of a specific source domain. Current state-of-the-art works suggest that performing category alignment can alleviate domain shift reasonably. However, they are mainly based on image-to-image adversarial training and little consideration is given to semantic variations of an object among images, failing to capture a comprehensive picture of different categories. This motivates us to explore a holistic representative, the semantic distribution from each category in source domain, to mitigate the problem above. In this paper, we present semantic distribution-aware contrastive adaptation algorithm that enables pixel-wise representation alignment under the guidance of semantic distributions. Specifically, we first design a pixel-wise contrastive loss by considering the correspondences between semantic distributions and pixel-wise representations from both domains. Essentially, clusters of pixel representations from the same category should cluster together and those from different categories should spread out. Next, an upper bound on this formulation is derived by involving the learning of an infinite number of (dis)similar pairs, making it efficient. Finally, we verify that SDCA can further improve segmentation accuracy when integrated with the self-supervised learning. We evaluate SDCA on multiple benchmarks, achieving considerable improvements over existing algorithms.The code is publicly available at https://github.com/BIT-DA/SDCA
MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition
Apr 07, 2021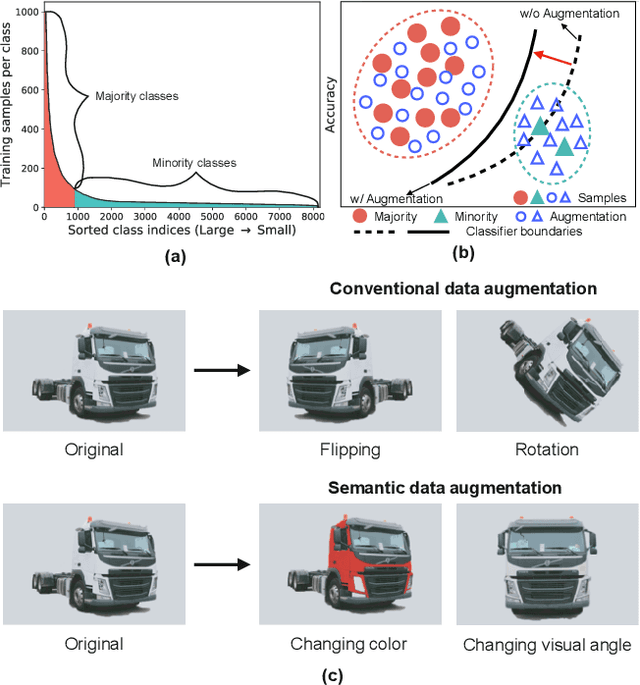
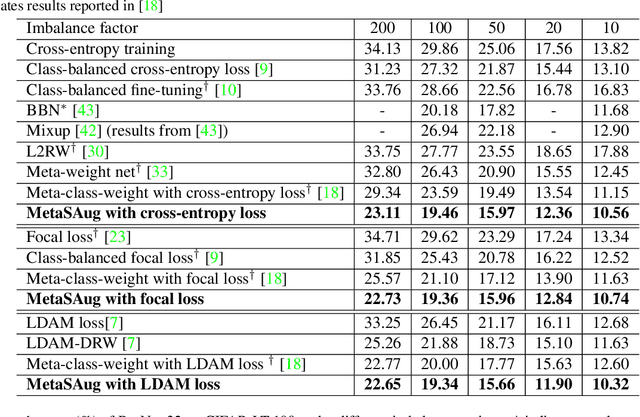
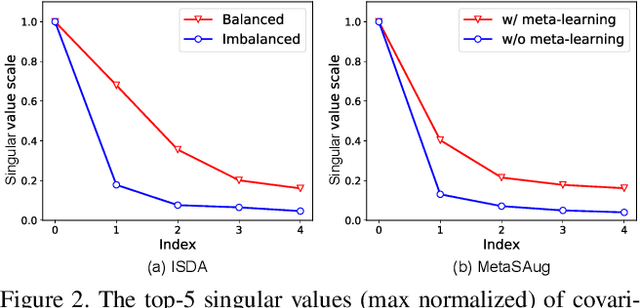
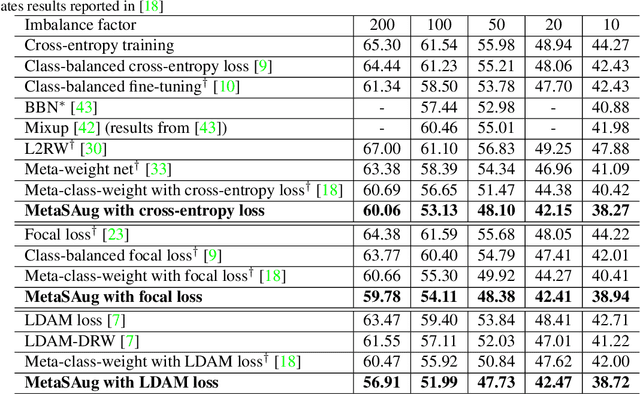
Real-world training data usually exhibits long-tailed distribution, where several majority classes have a significantly larger number of samples than the remaining minority classes. This imbalance degrades the performance of typical supervised learning algorithms designed for balanced training sets. In this paper, we address this issue by augmenting minority classes with a recently proposed implicit semantic data augmentation (ISDA) algorithm, which produces diversified augmented samples by translating deep features along many semantically meaningful directions. Importantly, given that ISDA estimates the class-conditional statistics to obtain semantic directions, we find it ineffective to do this on minority classes due to the insufficient training data. To this end, we propose a novel approach to learn transformed semantic directions with meta-learning automatically. In specific, the augmentation strategy during training is dynamically optimized, aiming to minimize the loss on a small balanced validation set, which is approximated via a meta update step. Extensive empirical results on CIFAR-LT-10/100, ImageNet-LT, and iNaturalist 2017/2018 validate the effectiveness of our method.
AutoTrajectory: Label-free Trajectory Extraction and Prediction from Videos using Dynamic Points
Jul 11, 2020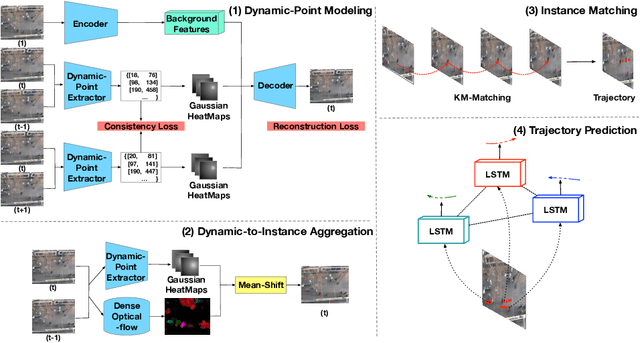
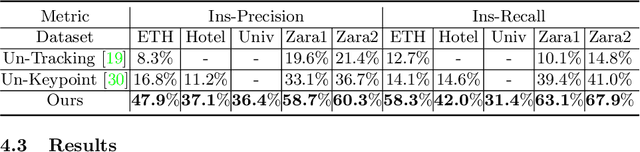
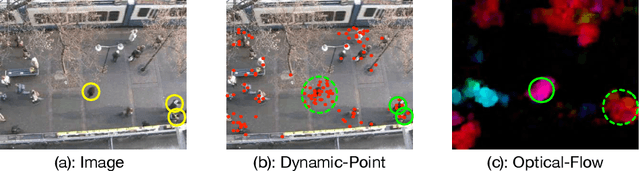
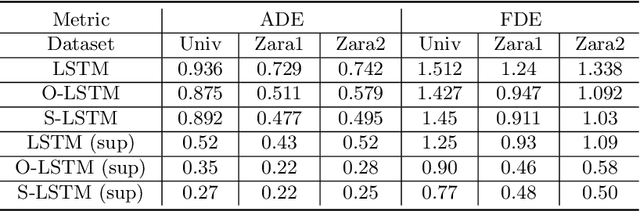
Current methods for trajectory prediction operate in supervised manners, and therefore require vast quantities of corresponding ground truth data for training. In this paper, we present a novel, label-free algorithm, AutoTrajectory, for trajectory extraction and prediction to use raw videos directly. To better capture the moving objects in videos, we introduce dynamic points. We use them to model dynamic motions by using a forward-backward extractor to keep temporal consistency and using image reconstruction to keep spatial consistency in an unsupervised manner. Then we aggregate dynamic points to instance points, which stand for moving objects such as pedestrians in videos. Finally, we extract trajectories by matching instance points for prediction training. To the best of our knowledge, our method is the first to achieve unsupervised learning of trajectory extraction and prediction. We evaluate the performance on well-known trajectory datasets and show that our method is effective for real-world videos and can use raw videos to further improve the performance of existing models.
ODE-CNN: Omnidirectional Depth Extension Networks
Jul 03, 2020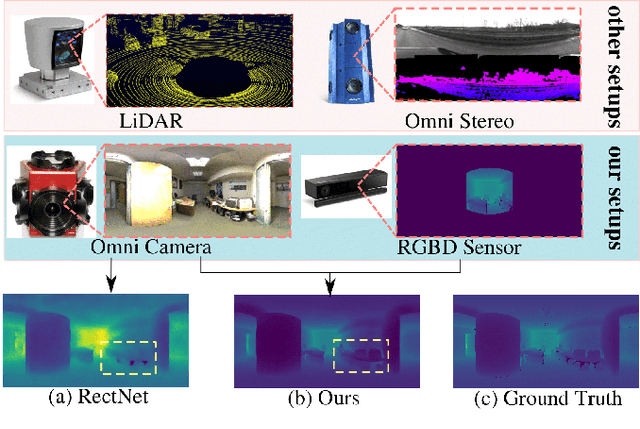
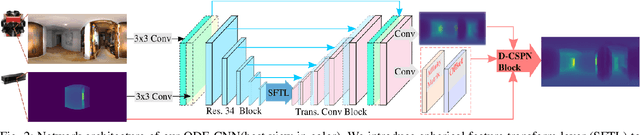

Omnidirectional 360{\deg} camera proliferates rapidly for autonomous robots since it significantly enhances the perception ability by widening the field of view(FoV). However, corresponding 360{\deg} depth sensors, which are also critical for the perception system, are still difficult or expensive to have. In this paper, we propose a low-cost 3D sensing system that combines an omnidirectional camera with a calibrated projective depth camera, where the depth from the limited FoV can be automatically extended to the rest of the recorded omnidirectional image. To accurately recover the missing depths, we design an omnidirectional depth extension convolutional neural network(ODE-CNN), in which a spherical feature transform layer(SFTL) is embedded at the end of feature encoding layers, and a deformable convolutional spatial propagation network(D-CSPN) is appended at the end of feature decoding layers. The former resamples the neighborhood of each pixel in the omnidirectional coordination to the projective coordination, which reduces the difficulty of feature learning, and the later automatically finds a proper context to well align the structures in the estimated depths via CNN w.r.t. the reference image, which significantly improves the visual quality. Finally, we demonstrate the effectiveness of proposed ODE-CNN over the popular 360D dataset and show that ODE-CNN significantly outperforms (relatively 33% reduction in-depth error) other state-of-the-art (SoTA) methods.
CSPN++: Learning Context and Resource Aware Convolutional Spatial Propagation Networks for Depth Completion
Nov 22, 2019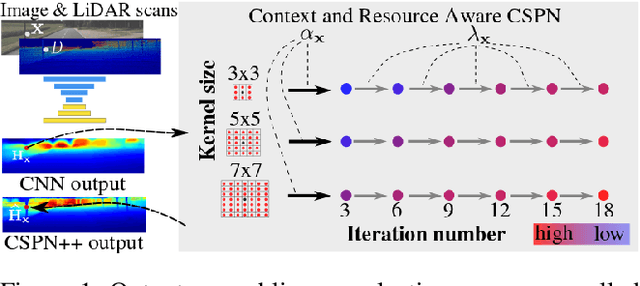

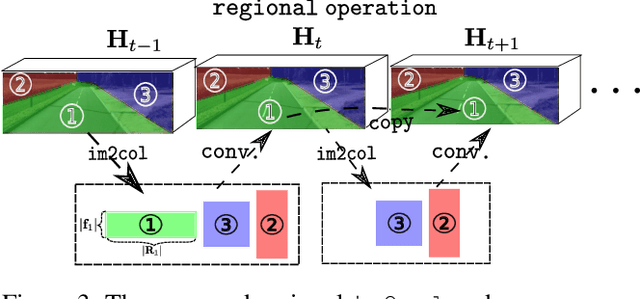
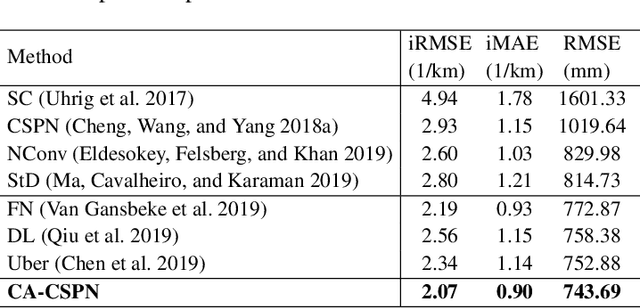
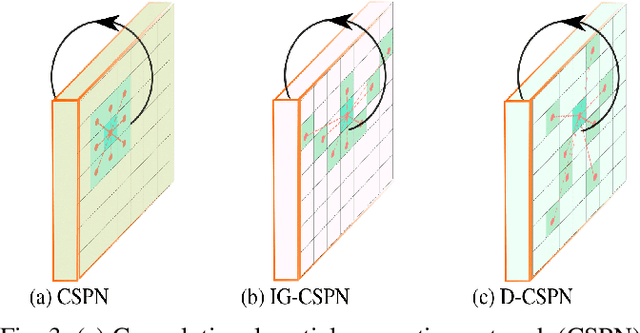
Depth Completion deals with the problem of converting a sparse depth map to a dense one, given the corresponding color image. Convolutional spatial propagation network (CSPN) is one of the state-of-the-art (SoTA) methods of depth completion, which recovers structural details of the scene. In this paper, we propose CSPN++, which further improves its effectiveness and efficiency by learning adaptive convolutional kernel sizes and the number of iterations for the propagation, thus the context and computational resources needed at each pixel could be dynamically assigned upon requests. Specifically, we formulate the learning of the two hyper-parameters as an architecture selection problem where various configurations of kernel sizes and numbers of iterations are first defined, and then a set of soft weighting parameters are trained to either properly assemble or select from the pre-defined configurations at each pixel. In our experiments, we find weighted assembling can lead to significant accuracy improvements, which we referred to as "context-aware CSPN", while weighted selection, "resource-aware CSPN" can reduce the computational resource significantly with similar or better accuracy. Besides, the resource needed for CSPN++ can be adjusted w.r.t. the computational budget automatically. Finally, to avoid the side effects of noise or inaccurate sparse depths, we embed a gated network inside CSPN++, which further improves the performance. We demonstrate the effectiveness of CSPN++on the KITTI depth completion benchmark, where it significantly improves over CSPN and other SoTA methods.