 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-based Disentanglement with Distant Supervision
Dec 15, 2022Disentangled representation learning remains challenging as ground truth factors of variation do not naturally exist. To address this, we present Vocabulary Disentanglement Retrieval~(VDR), a simple yet effective retrieval-based disentanglement framework that leverages nature language as distant supervision. Our approach is built upon the widely-used bi-encoder architecture with disentanglement heads and is trained on data-text pairs that are readily available on the web or in existing datasets. This makes our approach task- and modality-agnostic with potential for a wide range of downstream applications. We conduct experiments on 16 datasets in both text-to-text and cross-modal scenarios and evaluate VDR in a zero-shot setting. With the incorporation of disentanglement heads and a minor increase in parameters, VDR achieves significant improvements over the base retriever it is built upon, with a 9% higher on NDCG@10 scores in zero-shot text-to-text retrieval and an average of 13% higher recall in cross-modal retrieval. In comparison to other baselines, VDR outperforms them in most tasks, while also improving explainability and efficiency.
G-MAP: General Memory-Augmented Pre-trained Language Model for Domain Tasks
Dec 08, 2022Recently, domain-specific PLMs have been proposed to boost the task performance of specific domains (e.g., biomedical and computer science) by continuing to pre-train general PLMs with domain-specific corpora. However, this Domain-Adaptive Pre-Training (DAPT; Gururangan et al. (2020)) tends to forget the previous general knowledge acquired by general PLMs, which leads to a catastrophic forgetting phenomenon and sub-optimal performance. To alleviate this problem, we propose a new framework of General Memory Augmented Pre-trained Language Model (G-MAP), which augments the domain-specific PLM by a memory representation built from the frozen general PLM without losing any general knowledge. Specifically, we propose a new memory-augmented layer, and based on it, different augmented strategies are explored to build the memory representation and then adaptively fuse it into the domain-specific PLM. We demonstrate the effectiveness of G-MAP on various domains (biomedical and computer science publications, news, and reviews) and different kinds (text classification, QA, NER) of tasks, and the extensive results show that the proposed G-MAP can achieve SOTA results on all tasks.
KPT: Keyword-guided Pre-training for Grounded Dialog Generation
Dec 04, 2022Incorporating external knowledge into the response generation process is essential to building more helpful and reliable dialog agents. However, collecting knowledge-grounded conversations is often costly, calling for a better pre-trained model for grounded dialog generation that generalizes well w.r.t. different types of knowledge. In this work, we propose KPT (Keyword-guided Pre-Training), a novel self-supervised pre-training method for grounded dialog generation without relying on extra knowledge annotation. Specifically, we use a pre-trained language model to extract the most uncertain tokens in the dialog as keywords. With these keywords, we construct two kinds of knowledge and pre-train a knowledge-grounded response generation model, aiming at handling two different scenarios: (1) the knowledge should be faithfully grounded; (2) it can be selectively used. For the former, the grounding knowledge consists of keywords extracted from the response. For the latter, the grounding knowledge is additionally augmented with keywords extracted from other utterances in the same dialog. Since the knowledge is extracted from the dialog itself, KPT can be easily performed on a large volume and variety of dialogue data. We considered three data sources (open-domain, task-oriented, conversational QA) with a total of 2.5M dialogues. We conduct extensive experiments on various few-shot knowledge-grounded generation tasks, including grounding on dialog acts, knowledge graphs, persona descriptions, and Wikipedia passages. Our comprehensive experiments and analyses demonstrate that KPT consistently outperforms state-of-the-art methods on these tasks with diverse grounding knowledge.
SongRewriter: A Chinese Song Rewriting System with Controllable Content and Rhyme Scheme
Nov 28, 2022



Although lyrics generation has achieved significant progress in recent years, it has limited practical applications because the generated lyrics cannot be performed without composing compatible melodies. In this work, we bridge this practical gap by proposing a song rewriting system which rewrites the lyrics of an existing song such that the generated lyrics are compatible with the rhythm of the existing melody and thus singable. In particular, we propose SongRewriter, a controllable Chinese lyric generation and editing system which assists users without prior knowledge of melody composition. The system is trained by a randomized multi-level masking strategy which produces a unified model for generating entirely new lyrics or editing a few fragments. To improve the controllabiliy of the generation process, we further incorporate a keyword prompt to control the lexical choices of the content and propose novel decoding constraints and a vowel modeling task to enable flexible end and internal rhyme schemes. While prior rhyming metrics are mainly for rap lyrics, we propose three novel rhyming evaluation metrics for song lyrics. Both automatic and human evaluations show that the proposed model performs better than the state-of-the-art models in both contents and rhyming quality. Our code and models implemented in MindSpore Lite tool will be available.
Lexicon-injected Semantic Parsing for Task-Oriented Dialog
Nov 26, 2022Recently, semantic parsing using hierarchical representations for dialog systems has captured substantial attention. Task-Oriented Parse (TOP), a tree representation with intents and slots as labels of nested tree nodes, has been proposed for parsing user utterances. Previous TOP parsing methods are limited on tackling unseen dynamic slot values (e.g., new songs and locations added), which is an urgent matter for real dialog systems. To mitigate this issue, we first propose a novel span-splitting representation for span-based parser that outperforms existing methods. Then we present a novel lexicon-injected semantic parser, which collects slot labels of tree representation as a lexicon, and injects lexical features to the span representation of parser. An additional slot disambiguation technique is involved to remove inappropriate span match occurrences from the lexicon. Our best parser produces a new state-of-the-art result (87.62%) on the TOP dataset, and demonstrates its adaptability to frequently updated slot lexicon entries in real task-oriented dialog, with no need of retraining.
FPT: Improving Prompt Tuning Efficiency via Progressive Training
Nov 13, 2022Recently, prompt tuning (PT) has gained increasing attention as a parameter-efficient way of tuning pre-trained language models (PLMs). Despite extensively reducing the number of tunable parameters and achieving satisfying performance, PT is training-inefficient due to its slow convergence. To improve PT's training efficiency, we first make some novel observations about the prompt transferability of "partial PLMs", which are defined by compressing a PLM in depth or width. We observe that the soft prompts learned by different partial PLMs of various sizes are similar in the parameter space, implying that these soft prompts could potentially be transferred among partial PLMs. Inspired by these observations, we propose Fast Prompt Tuning (FPT), which starts by conducting PT using a small-scale partial PLM, and then progressively expands its depth and width until the full-model size. After each expansion, we recycle the previously learned soft prompts as initialization for the enlarged partial PLM and then proceed PT. We demonstrate the feasibility of FPT on 5 tasks and show that FPT could save over 30% training computations while achieving comparable performance.
COPEN: Probing Conceptual Knowledge in Pre-trained Language Models
Nov 08, 2022



Conceptual knowledge is fundamental to human cognition and knowledge bases. However, existing knowledge probing works only focus on evaluating factual knowledge of pre-trained language models (PLMs) and ignore conceptual knowledge. Since conceptual knowledge often appears as implicit commonsense behind texts, designing probes for conceptual knowledge is hard. Inspired by knowledge representation schemata, we comprehensively evaluate conceptual knowledge of PLMs by designing three tasks to probe whether PLMs organize entities by conceptual similarities, learn conceptual properties, and conceptualize entities in contexts, respectively. For the tasks, we collect and annotate 24k data instances covering 393 concepts, which is COPEN, a COnceptual knowledge Probing bENchmark. Extensive experiments on different sizes and types of PLMs show that existing PLMs systematically lack conceptual knowledge and suffer from various spurious correlations. We believe this is a critical bottleneck for realizing human-like cognition in PLMs. COPEN and our codes are publicly released at https://github.com/THU-KEG/COPEN.
Pre-training Language Models with Deterministic Factual Knowledge
Oct 20, 2022
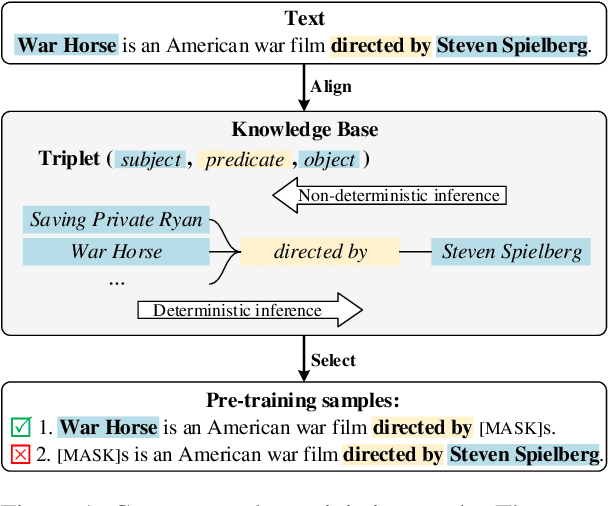

Previous works show that Pre-trained Language Models (PLMs) can capture factual knowledge. However, some analyses reveal that PLMs fail to perform it robustly, e.g., being sensitive to the changes of prompts when extracting factual knowledge. To mitigate this issue, we propose to let PLMs learn the deterministic relationship between the remaining context and the masked content. The deterministic relationship ensures that the masked factual content can be deterministically inferable based on the existing clues in the context. That would provide more stable patterns for PLMs to capture factual knowledge than randomly masking. Two pre-training tasks are further introduced to motivate PLMs to rely on the deterministic relationship when filling masks. Specifically, we use an external Knowledge Base (KB) to identify deterministic relationships and continuously pre-train PLMs with the proposed methods. The factual knowledge probing experiments indicate that the continuously pre-trained PLMs achieve better robustness in factual knowledge capturing. Further experiments on question-answering datasets show that trying to learn a deterministic relationship with the proposed methods can also help other knowledge-intensive tasks.
Making a MIRACL: Multilingual Information Retrieval Across a Continuum of Languages
Oct 18, 2022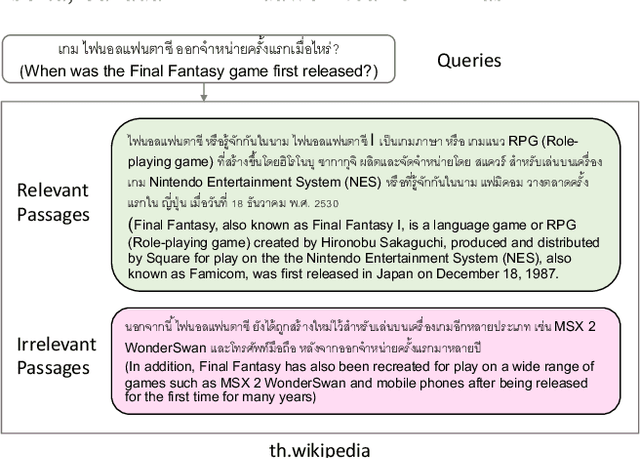
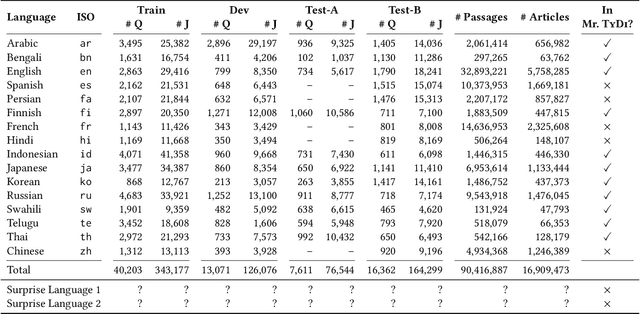
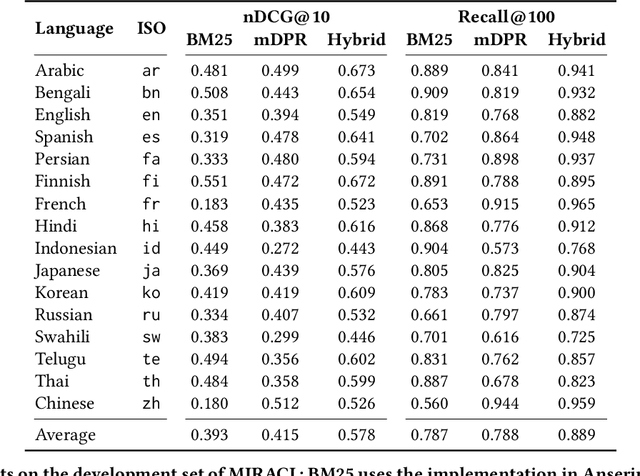
MIRACL (Multilingual Information Retrieval Across a Continuum of Languages) is a multilingual dataset we have built for the WSDM 2023 Cup challenge that focuses on ad hoc retrieval across 18 different languages, which collectively encompass over three billion native speakers around the world. These languages have diverse typologies, originate from many different language families, and are associated with varying amounts of available resources -- including what researchers typically characterize as high-resource as well as low-resource languages. Our dataset is designed to support the creation and evaluation of models for monolingual retrieval, where the queries and the corpora are in the same language. In total, we have gathered over 700k high-quality relevance judgments for around 77k queries over Wikipedia in these 18 languages, where all assessments have been performed by native speakers hired by our team. Our goal is to spur research that will improve retrieval across a continuum of languages, thus enhancing information access capabilities for diverse populations around the world, particularly those that have been traditionally underserved. This overview paper describes the dataset and baselines that we share with the community. The MIRACL website is live at http://miracl.ai/.
ShortcutLens: A Visual Analytics Approach for Exploring Shortcuts in Natural Language Understanding Dataset
Aug 17, 2022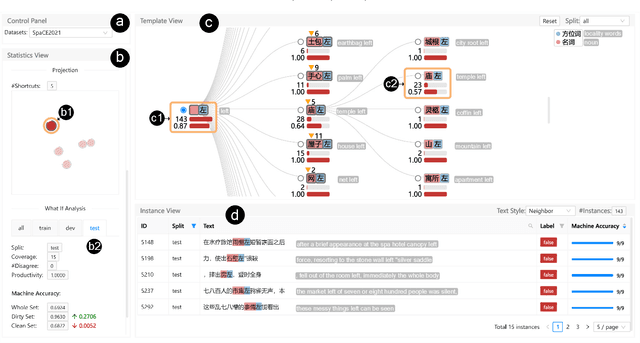
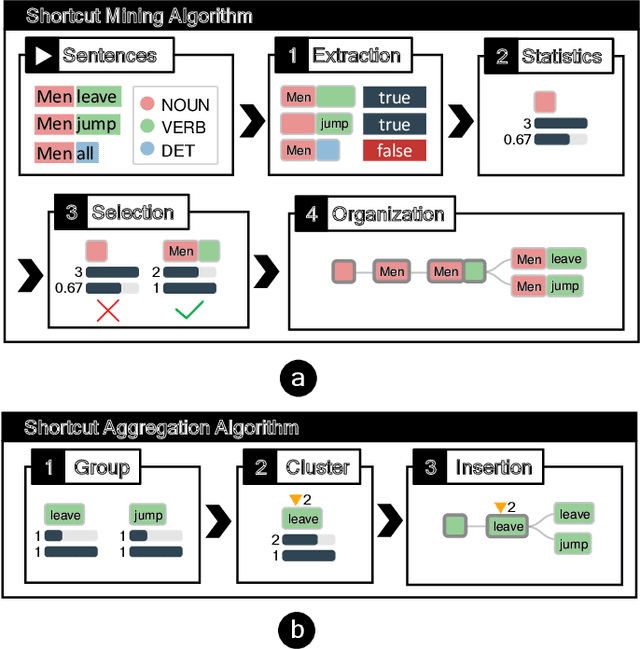
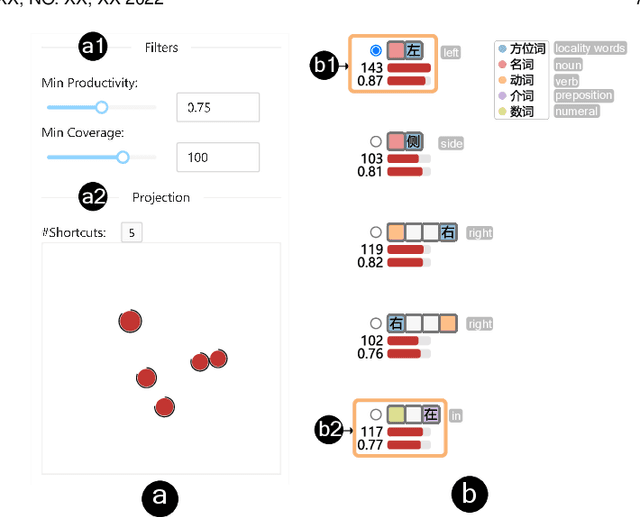
Benchmark datasets play an important role in evaluating Natural Language Understanding (NLU) models. However, shortcuts -- unwanted biases in the benchmark datasets -- can damage the effectiveness of benchmark datasets in revealing models' real capabilities. Since shortcuts vary in coverage, productivity, and semantic meaning, it is challenging for NLU experts to systematically understand and avoid them when creating benchmark datasets. In this paper, we develop a visual analytics system, ShortcutLens, to help NLU experts explore shortcuts in NLU benchmark datasets. The system allows users to conduct multi-level exploration of shortcuts. Specifically, Statistics View helps users grasp the statistics such as coverage and productivity of shortcuts in the benchmark dataset. Template View employs hierarchical and interpretable templates to summarize different types of shortcuts. Instance View allows users to check the corresponding instances covered by the shortcuts. We conduct case studies and expert interviews to evaluate the effectiveness and usability of the system. The results demonstrate that ShortcutLens supports users in gaining a better understanding of benchmark dataset issues through shortcuts, inspiring them to create challenging and pertinent benchmark datasets.