 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMO-SAE:Multi-Objective Stacked Autoencoders Optimization for Edge Anomaly Detection
Mar 14, 2026Stacked AutoEncoders (SAE) have been widely adopted in edge anomaly detection scenarios. However, the resource-intensive nature of SAE can pose significant challenges for edge devices, which are typically resource-constrained and must adapt rapidly to dynamic and changing conditions. Optimizing SAE to meet the heterogeneous demands of real-world deployment scenarios, including high performance under constrained storage, low power consumption, fast inference, and efficient model updates, remains a substantial challenge. To address this, we propose an integrated optimization framework that jointly considers these critical factors to achieve balanced and adaptive system-level optimization. Specifically, we formulate SAE optimization for edge anomaly detection as a multi-objective optimization problem and propose MO-SAE (Multi-Objective Stacked AutoEncoders). The multiple objectives are addressed by integrating model clipping, multi-branch exit design, and a matrix approximation technique. In addition, a multi-objective heuristic algorithm is employed to effectively balance the competing objectives in SAE optimization. Our results demonstrate that the proposed MO-SAE delivers substantial improvements over the original approach. On the x86 architecture, it reduces storage space and power consumption by at least 50%, improves runtime efficiency by no less than 28%, and achieves an 11.8% compression rate, all while maintaining application performance. Furthermore, MO-SAE runs efficiently on edge devices with ARM architecture. Experimental results show a 15% improvement in inference speed, facilitating efficient deployment in cloud-edge collaborative anomaly detection systems.
RAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems
Mar 11, 2026We present the design and implementation of a RAG-based AI system benchmarking (RAGPerf) framework for characterizing the system behaviors of RAG pipelines. To facilitate detailed profiling and fine-grained performance analysis, RAGPerf decouples the RAG workflow into several modular components - embedding, indexing, retrieval, reranking, and generation. RAGPerf offers the flexibility for users to configure the core parameters of each component and examine their impact on the end-to-end query performance and quality. RAGPerf has a workload generator to model real-world scenarios by supporting diverse datasets (e.g., text, pdf, code, and audio), different retrieval and update ratios, and query distributions. RAGPerf also supports different embedding models, major vector databases such as LanceDB, Milvus, Qdrant, Chroma, and Elasticsearch, as well as different LLMs for content generation. It automates the collection of performance metrics (i.e., end-to-end query throughput, host/GPU memory footprint, and CPU/GPU utilization) and accuracy metrics (i.e., context recall, query accuracy, and factual consistency). We demonstrate the capabilities of RAGPerf through a comprehensive set of experiments and open source its codebase at GitHub. Our evaluation shows that RAGPerf incurs negligible performance overhead.
CDW-CoT: Clustered Distance-Weighted Chain-of-Thoughts Reasoning
Jan 21, 2025



Large Language Models (LLMs) have recently achieved impressive results in complex reasoning tasks through Chain of Thought (CoT) prompting. However, most existing CoT methods rely on using the same prompts, whether manually designed or automatically generated, to handle the entire dataset. This one-size-fits-all approach may fail to meet the specific needs arising from the diversities within a single dataset. To solve this problem, we propose the Clustered Distance-Weighted Chain of Thought (CDW-CoT) method, which dynamically constructs prompts tailored to the characteristics of each data instance by integrating clustering and prompt optimization techniques. Our method employs clustering algorithms to categorize the dataset into distinct groups, from which a candidate pool of prompts is selected to reflect the inherent diversity within the dataset. For each cluster, CDW-CoT trains the optimal prompt probability distribution tailored to their specific characteristics. Finally, it dynamically constructs a unique prompt probability distribution for each test instance, based on its proximity to cluster centers, from which prompts are selected for reasoning. CDW-CoT consistently outperforms traditional CoT methods across six datasets, including commonsense, symbolic, and mathematical reasoning tasks. Specifically, when compared to manual CoT, CDW-CoT achieves an average accuracy improvement of 25.34% on LLaMA2 (13B) and 15.72% on LLaMA3 (8B).
A Codesign of Scheduling and Parallelization for Large Model Training in Heterogeneous Clusters
Mar 24, 2024Joint consideration of scheduling and adaptive parallelism offers great opportunities for improving the training efficiency of large models on heterogeneous GPU clusters. However, integrating adaptive parallelism into a cluster scheduler expands the cluster scheduling space. The new space is the product of the original scheduling space and the parallelism exploration space of adaptive parallelism (also a product of pipeline, data, and tensor parallelism). The exponentially enlarged scheduling space and ever-changing optimal parallelism plan from adaptive parallelism together result in the contradiction between low-overhead and accurate performance data acquisition for efficient cluster scheduling. This paper presents Crius, a training system for efficiently scheduling multiple large models with adaptive parallelism in a heterogeneous cluster. Crius proposes a novel scheduling granularity called Cell. It represents a job with deterministic resources and pipeline stages. The exploration space of Cell is shrunk to the product of only data and tensor parallelism, thus exposing the potential for accurate and low-overhead performance estimation. Crius then accurately estimates Cells and efficiently schedules training jobs. When a Cell is selected as a scheduling choice, its represented job runs with the optimal parallelism plan explored. Experimental results show that Crius reduces job completion time by up to 48.9% and schedules large models with up to 1.49x cluster throughput improvement.
Group Equivariant BEV for 3D Object Detection
Apr 26, 2023



Recently, 3D object detection has attracted significant attention and achieved continuous improvement in real road scenarios. The environmental information is collected from a single sensor or multi-sensor fusion to detect interested objects. However, most of the current 3D object detection approaches focus on developing advanced network architectures to improve the detection precision of the object rather than considering the dynamic driving scenes, where data collected from sensors equipped in the vehicle contain various perturbation features. As a result, existing work cannot still tackle the perturbation issue. In order to solve this problem, we propose a group equivariant bird's eye view network (GeqBevNet) based on the group equivariant theory, which introduces the concept of group equivariant into the BEV fusion object detection network. The group equivariant network is embedded into the fused BEV feature map to facilitate the BEV-level rotational equivariant feature extraction, thus leading to lower average orientation error. In order to demonstrate the effectiveness of the GeqBevNet, the network is verified on the nuScenes validation dataset in which mAOE can be decreased to 0.325. Experimental results demonstrate that GeqBevNet can extract more rotational equivariant features in the 3D object detection of the actual road scene and improve the performance of object orientation prediction.
Determinate Node Selection for Semi-supervised Classification Oriented Graph Convolutional Networks
Jan 11, 2023Graph Convolutional Networks (GCNs) have been proved successful in the field of semi-supervised node classification by extracting structural information from graph data. However, the random selection of labeled nodes used by GCNs may lead to unstable generalization performance of GCNs. In this paper, we propose an efficient method for the deterministic selection of labeled nodes: the Determinate Node Selection (DNS) algorithm. The DNS algorithm identifies two categories of representative nodes in the graph: typical nodes and divergent nodes. These labeled nodes are selected by exploring the structure of the graph and determining the ability of the nodes to represent the distribution of data within the graph. The DNS algorithm can be applied quite simply on a wide range of semi-supervised graph neural network models for node classification tasks. Through extensive experimentation, we have demonstrated that the incorporation of the DNS algorithm leads to a remarkable improvement in the average accuracy of the model and a significant decrease in the standard deviation, as compared to the original method.
Pre-training Language Models with Deterministic Factual Knowledge
Oct 20, 2022
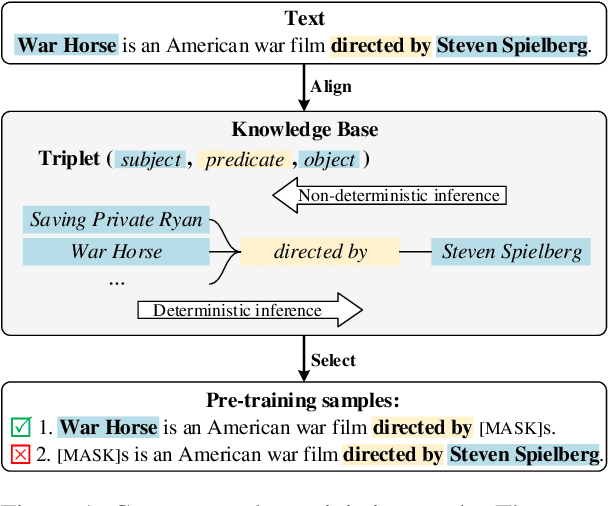

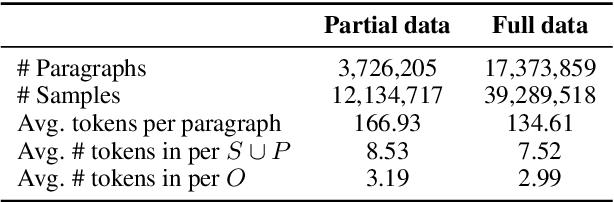
Previous works show that Pre-trained Language Models (PLMs) can capture factual knowledge. However, some analyses reveal that PLMs fail to perform it robustly, e.g., being sensitive to the changes of prompts when extracting factual knowledge. To mitigate this issue, we propose to let PLMs learn the deterministic relationship between the remaining context and the masked content. The deterministic relationship ensures that the masked factual content can be deterministically inferable based on the existing clues in the context. That would provide more stable patterns for PLMs to capture factual knowledge than randomly masking. Two pre-training tasks are further introduced to motivate PLMs to rely on the deterministic relationship when filling masks. Specifically, we use an external Knowledge Base (KB) to identify deterministic relationships and continuously pre-train PLMs with the proposed methods. The factual knowledge probing experiments indicate that the continuously pre-trained PLMs achieve better robustness in factual knowledge capturing. Further experiments on question-answering datasets show that trying to learn a deterministic relationship with the proposed methods can also help other knowledge-intensive tasks.
Semi-supervised Learning with Deterministic Labeling and Large Margin Projection
Aug 17, 2022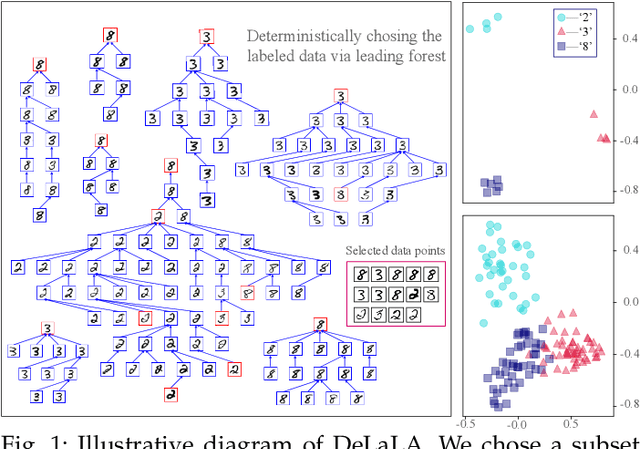
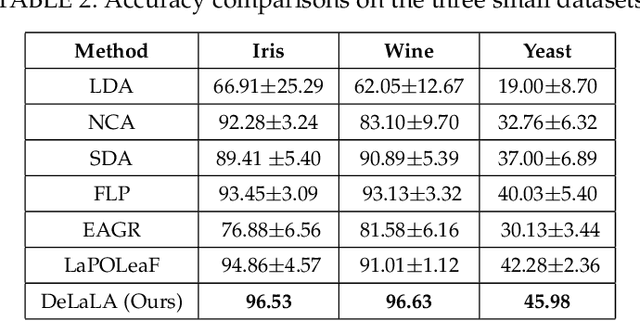
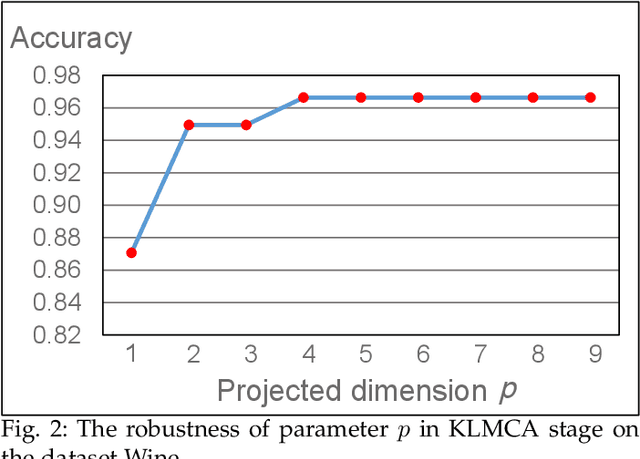
The centrality and diversity of the labeled data are very influential to the performance of semi-supervised learning (SSL), but most SSL models select the labeled data randomly. How to guarantee the centrality and diversity of the labeled data has so far received little research attention. Optimal leading forest (OLF) has been observed to have the advantage of revealing the difference evolution within a class when it was utilized to develop an SSL model. Our key intuition of this study is to learn a kernelized large margin metric for a small amount of most stable and most divergent data that are recognized based on the OLF structure. An optimization problem is formulated to achieve this goal. Also with OLF the multiple local metrics learning is facilitated to address multi-modal and mix-modal problem in SSL. Attribute to this novel design, the accuracy and performance stableness of the SSL model based on OLF is significantly improved compared with its baseline methods without sacrificing much efficiency. The experimental studies have shown that the proposed method achieved encouraging accuracy and running time when compared to the state-of-the-art graph SSL methods. Code has been made available at https://github.com/alanxuji/DeLaLA.
How Pre-trained Language Models Capture Factual Knowledge? A Causal-Inspired Analysis
Mar 31, 2022
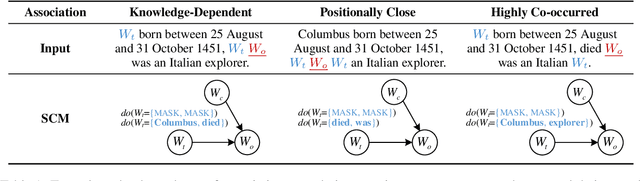
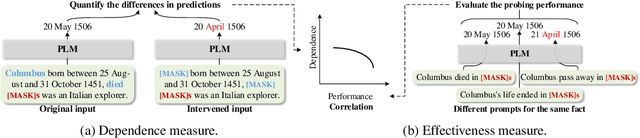
Recently, there has been a trend to investigate the factual knowledge captured by Pre-trained Language Models (PLMs). Many works show the PLMs' ability to fill in the missing factual words in cloze-style prompts such as "Dante was born in [MASK]." However, it is still a mystery how PLMs generate the results correctly: relying on effective clues or shortcut patterns? We try to answer this question by a causal-inspired analysis that quantitatively measures and evaluates the word-level patterns that PLMs depend on to generate the missing words. We check the words that have three typical associations with the missing words: knowledge-dependent, positionally close, and highly co-occurred. Our analysis shows: (1) PLMs generate the missing factual words more by the positionally close and highly co-occurred words than the knowledge-dependent words; (2) the dependence on the knowledge-dependent words is more effective than the positionally close and highly co-occurred words. Accordingly, we conclude that the PLMs capture the factual knowledge ineffectively because of depending on the inadequate associations.
Integrating Regular Expressions with Neural Networks via DFA
Sep 07, 2021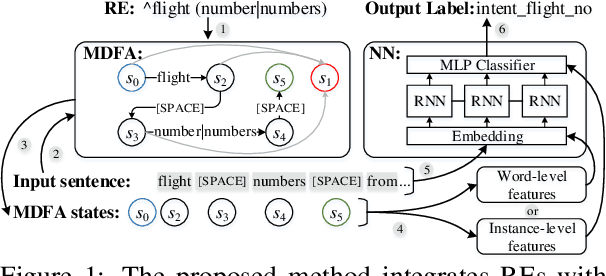
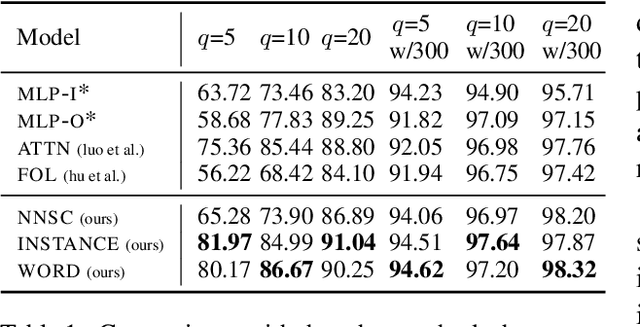
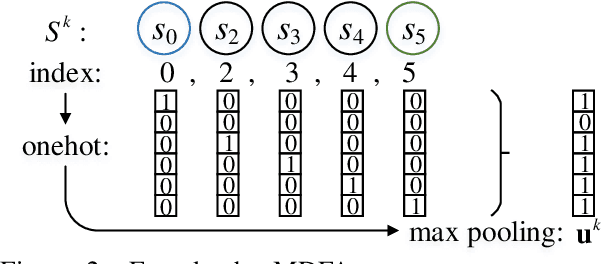
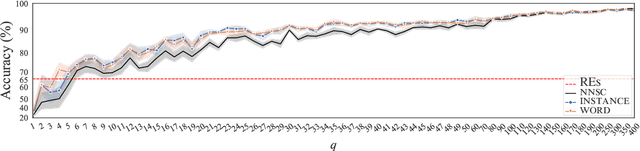
Human-designed rules are widely used to build industry applications. However, it is infeasible to maintain thousands of such hand-crafted rules. So it is very important to integrate the rule knowledge into neural networks to build a hybrid model that achieves better performance. Specifically, the human-designed rules are formulated as Regular Expressions (REs), from which the equivalent Minimal Deterministic Finite Automatons (MDFAs) are constructed. We propose to use the MDFA as an intermediate model to capture the matched RE patterns as rule-based features for each input sentence and introduce these additional features into neural networks. We evaluate the proposed method on the ATIS intent classification task. The experiment results show that the proposed method achieves the best performance compared to neural networks and four other methods that combine REs and neural networks when the training dataset is relatively small.