 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndependently Keypoint Learning for Small Object Semantic Correspondence
Apr 03, 2024Semantic correspondence remains a challenging task for establishing correspondences between a pair of images with the same category or similar scenes due to the large intra-class appearance. In this paper, we introduce a novel problem called 'Small Object Semantic Correspondence (SOSC).' This problem is challenging due to the close proximity of keypoints associated with small objects, which results in the fusion of these respective features. It is difficult to identify the corresponding key points of the fused features, and it is also difficult to be recognized. To address this challenge, we propose the Keypoint Bounding box-centered Cropping (KBC) method, which aims to increase the spatial separation between keypoints of small objects, thereby facilitating independent learning of these keypoints. The KBC method is seamlessly integrated into our proposed inference pipeline and can be easily incorporated into other methodologies, resulting in significant performance enhancements. Additionally, we introduce a novel framework, named KBCNet, which serves as our baseline model. KBCNet comprises a Cross-Scale Feature Alignment (CSFA) module and an efficient 4D convolutional decoder. The CSFA module is designed to align multi-scale features, enriching keypoint representations by integrating fine-grained features and deep semantic features. Meanwhile, the 4D convolutional decoder, based on efficient 4D convolution, ensures efficiency and rapid convergence. To empirically validate the effectiveness of our proposed methodology, extensive experiments are conducted on three widely used benchmarks: PF-PASCAL, PF-WILLOW, and SPair-71k. Our KBC method demonstrates a substantial performance improvement of 7.5\% on the SPair-71K dataset, providing compelling evidence of its efficacy.
VisKoP: Visual Knowledge oriented Programming for Interactive Knowledge Base Question Answering
Jul 06, 2023We present Visual Knowledge oriented Programming platform (VisKoP), a knowledge base question answering (KBQA) system that integrates human into the loop to edit and debug the knowledge base (KB) queries. VisKoP not only provides a neural program induction module, which converts natural language questions into knowledge oriented program language (KoPL), but also maps KoPL programs into graphical elements. KoPL programs can be edited with simple graphical operators, such as dragging to add knowledge operators and slot filling to designate operator arguments. Moreover, VisKoP provides auto-completion for its knowledge base schema and users can easily debug the KoPL program by checking its intermediate results. To facilitate the practical KBQA on a million-entity-level KB, we design a highly efficient KoPL execution engine for the back-end. Experiment results show that VisKoP is highly efficient and user interaction can fix a large portion of wrong KoPL programs to acquire the correct answer. The VisKoP online demo https://demoviskop.xlore.cn (Stable release of this paper) and https://viskop.xlore.cn (Beta release with new features), highly efficient KoPL engine https://pypi.org/project/kopl-engine, and screencast video https://youtu.be/zAbJtxFPTXo are now publicly available.
KoLA: Carefully Benchmarking World Knowledge of Large Language Models
Jun 15, 2023



The unprecedented performance of large language models (LLMs) necessitates improvements in evaluations. Rather than merely exploring the breadth of LLM abilities, we believe meticulous and thoughtful designs are essential to thorough, unbiased, and applicable evaluations. Given the importance of world knowledge to LLMs, we construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) For ability modeling, we mimic human cognition to form a four-level taxonomy of knowledge-related abilities, covering $19$ tasks. (2) For data, to ensure fair comparisons, we use both Wikipedia, a corpus prevalently pre-trained by LLMs, along with continuously collected emerging corpora, aiming to evaluate the capacity to handle unseen data and evolving knowledge. (3) For evaluation criteria, we adopt a contrastive system, including overall standard scores for better numerical comparability across tasks and models and a unique self-contrast metric for automatically evaluating knowledge hallucination. We evaluate $21$ open-source and commercial LLMs and obtain some intriguing findings. The KoLA dataset and open-participation leaderboard are publicly released at https://kola.xlore.cn and will be continuously updated to provide references for developing LLMs and knowledge-related systems.
Learn to Not Link: Exploring NIL Prediction in Entity Linking
May 25, 2023



Entity linking models have achieved significant success via utilizing pretrained language models to capture semantic features. However, the NIL prediction problem, which aims to identify mentions without a corresponding entity in the knowledge base, has received insufficient attention. We categorize mentions linking to NIL into Missing Entity and Non-Entity Phrase, and propose an entity linking dataset NEL that focuses on the NIL prediction problem. NEL takes ambiguous entities as seeds, collects relevant mention context in the Wikipedia corpus, and ensures the presence of mentions linking to NIL by human annotation and entity masking. We conduct a series of experiments with the widely used bi-encoder and cross-encoder entity linking models, results show that both types of NIL mentions in training data have a significant influence on the accuracy of NIL prediction. Our code and dataset can be accessed at https://github.com/solitaryzero/NIL_EL
COPEN: Probing Conceptual Knowledge in Pre-trained Language Models
Nov 08, 2022



Conceptual knowledge is fundamental to human cognition and knowledge bases. However, existing knowledge probing works only focus on evaluating factual knowledge of pre-trained language models (PLMs) and ignore conceptual knowledge. Since conceptual knowledge often appears as implicit commonsense behind texts, designing probes for conceptual knowledge is hard. Inspired by knowledge representation schemata, we comprehensively evaluate conceptual knowledge of PLMs by designing three tasks to probe whether PLMs organize entities by conceptual similarities, learn conceptual properties, and conceptualize entities in contexts, respectively. For the tasks, we collect and annotate 24k data instances covering 393 concepts, which is COPEN, a COnceptual knowledge Probing bENchmark. Extensive experiments on different sizes and types of PLMs show that existing PLMs systematically lack conceptual knowledge and suffer from various spurious correlations. We believe this is a critical bottleneck for realizing human-like cognition in PLMs. COPEN and our codes are publicly released at https://github.com/THU-KEG/COPEN.
Feature Engineering and Ensemble Modeling for Paper Acceptance Rank Prediction
Nov 14, 2016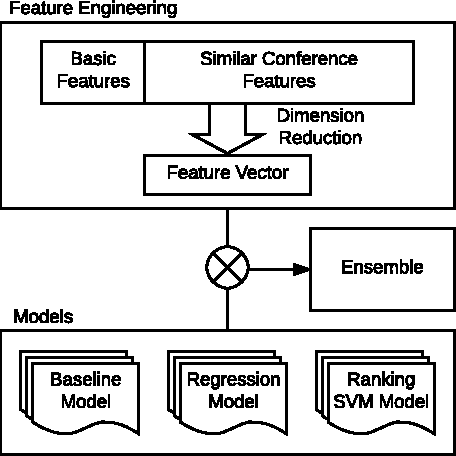
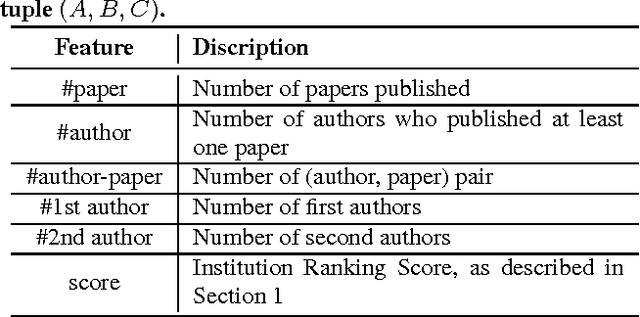
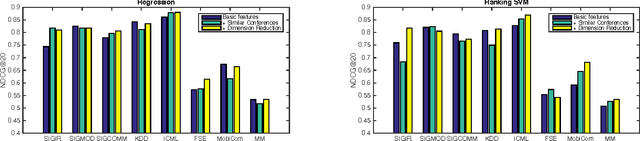
Measuring research impact and ranking academic achievement are important and challenging problems. Having an objective picture of research institution is particularly valuable for students, parents and funding agencies, and also attracts attention from government and industry. KDD Cup 2016 proposes the paper acceptance rank prediction task, in which the participants are asked to rank the importance of institutions based on predicting how many of their papers will be accepted at the 8 top conferences in computer science. In our work, we adopt a three-step feature engineering method, including basic features definition, finding similar conferences to enhance the feature set, and dimension reduction using PCA. We propose three ranking models and the ensemble methods for combining such models. Our experiment verifies the effectiveness of our approach. In KDD Cup 2016, we achieved the overall rank of the 2nd place.