 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Context Aware Upcycling: A New Frontier for Hybrid LLM Scaling
Apr 27, 2026Hybrid sequence models that combine efficient Transformer components with linear sequence modeling blocks are a promising alternative to pure Transformers, but most are still pretrained from scratch and therefore fail to reuse existing Transformer checkpoints. We study upcycling as a practical path to convert pretrained Transformer LLMs into hybrid architectures while preserving short-context quality and improving long-context capability. We call our solution \emph{HyLo} (HYbrid LOng-context): a long-context upcycling recipe that combines architectural adaptation with efficient Transformer blocks, Multi-Head Latent Attention (MLA), and linear blocks (Mamba2 or Gated DeltaNet), together with staged long-context training and teacher-guided distillation for stable optimization. HyLo extends usable context length by up to $32\times$ through efficient post-training and reduces KV-cache memory by more than $90\%$, enabling up to 2M-token prefill and decoding in our \texttt{vLLM} inference stack, while comparable Llama baselines run out of memory beyond 64K context. Across 1B- and 3B-scale settings (Llama- and Qwen-based variants), HyLo delivers consistently strong short- and long-context performance and significantly outperforms state-of-the-art upcycled hybrid baselines on long-context evaluations such as RULER. Notably, at similar scale, HyLo-Qwen-1.7B trained on only 10B tokens significantly outperforms JetNemotron (trained on 400B tokens) on GSM8K, Lm-Harness common sense reasoning and RULER-64K.
Zebra-Llama: Towards Extremely Efficient Hybrid Models
May 22, 2025With the growing demand for deploying large language models (LLMs) across diverse applications, improving their inference efficiency is crucial for sustainable and democratized access. However, retraining LLMs to meet new user-specific requirements is prohibitively expensive and environmentally unsustainable. In this work, we propose a practical and scalable alternative: composing efficient hybrid language models from existing pre-trained models. Our approach, Zebra-Llama, introduces a family of 1B, 3B, and 8B hybrid models by combining State Space Models (SSMs) and Multi-head Latent Attention (MLA) layers, using a refined initialization and post-training pipeline to efficiently transfer knowledge from pre-trained Transformers. Zebra-Llama achieves Transformer-level accuracy with near-SSM efficiency using only 7-11B training tokens (compared to trillions of tokens required for pre-training) and an 8B teacher. Moreover, Zebra-Llama dramatically reduces KV cache size -down to 3.9%, 2%, and 2.73% of the original for the 1B, 3B, and 8B variants, respectively-while preserving 100%, 100%, and >97% of average zero-shot performance on LM Harness tasks. Compared to models like MambaInLLaMA, X-EcoMLA, Minitron, and Llamba, Zebra-Llama consistently delivers competitive or superior accuracy while using significantly fewer tokens, smaller teachers, and vastly reduced KV cache memory. Notably, Zebra-Llama-8B surpasses Minitron-8B in few-shot accuracy by 7% while using 8x fewer training tokens, over 12x smaller KV cache, and a smaller teacher (8B vs. 15B). It also achieves 2.6x-3.8x higher throughput (tokens/s) than MambaInLlama up to a 32k context length. We will release code and model checkpoints upon acceptance.
X-EcoMLA: Upcycling Pre-Trained Attention into MLA for Efficient and Extreme KV Compression
Mar 14, 2025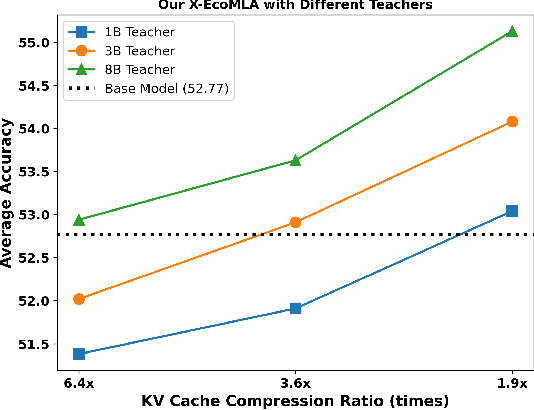
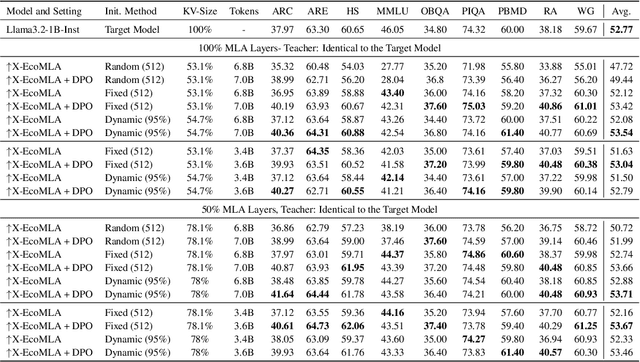
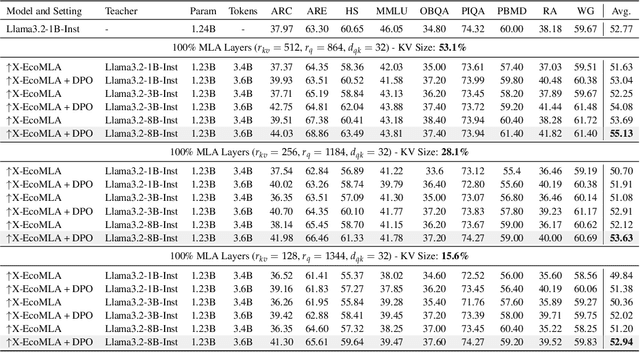
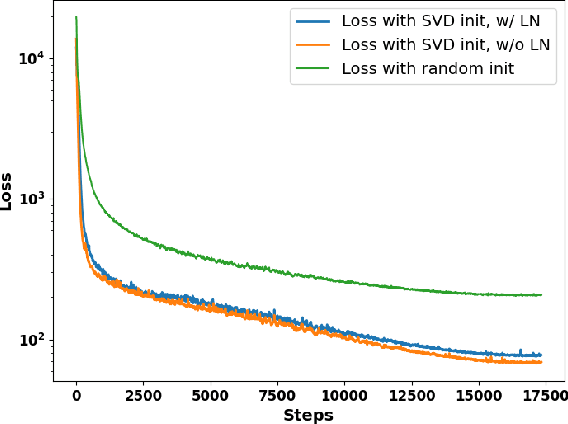
Multi-head latent attention (MLA) is designed to optimize KV cache memory through low-rank key-value joint compression. Rather than caching keys and values separately, MLA stores their compressed latent representations, reducing memory overhead while maintaining the performance. While MLA improves memory efficiency without compromising language model accuracy, its major limitation lies in its integration during the pre-training phase, requiring models to be trained from scratch. This raises a key question: can we use MLA's benefits fully or partially in models that have already been pre-trained with different attention mechanisms? In this paper, we propose X-EcoMLA to deploy post training distillation to enable the upcycling of Transformer-based attention into an efficient hybrid (i.e., combination of regular attention and MLA layers) or full MLA variant through lightweight post-training adaptation, bypassing the need for extensive pre-training. We demonstrate that leveraging the dark knowledge of a well-trained model can enhance training accuracy and enable extreme KV cache compression in MLA without compromising model performance. Our results show that using an 8B teacher model allows us to compress the KV cache size of the Llama3.2-1B-Inst baseline by 6.4x while preserving 100% of its average score across multiple tasks on the LM Harness Evaluation benchmark. This is achieved with only 3.6B training tokens and about 70 GPU hours on AMD MI300 GPUs, compared to the 370K GPU hours required for pre-training the Llama3.2-1B model.
Balcony: A Lightweight Approach to Dynamic Inference of Generative Language Models
Mar 06, 2025Deploying large language models (LLMs) in real-world applications is often hindered by strict computational and latency constraints. While dynamic inference offers the flexibility to adjust model behavior based on varying resource budgets, existing methods are frequently limited by hardware inefficiencies or performance degradation. In this paper, we introduce Balcony, a simple yet highly effective framework for depth-based dynamic inference. By freezing the pretrained LLM and inserting additional transformer layers at selected exit points, Balcony maintains the full model's performance while enabling real-time adaptation to different computational budgets. These additional layers are trained using a straightforward self-distillation loss, aligning the sub-model outputs with those of the full model. This approach requires significantly fewer training tokens and tunable parameters, drastically reducing computational costs compared to prior methods. When applied to the LLaMA3-8B model, using only 0.2% of the original pretraining data, Balcony achieves minimal performance degradation while enabling significant speedups. Remarkably, we show that Balcony outperforms state-of-the-art methods such as Flextron and Layerskip as well as other leading compression techniques on multiple models and at various scales, across a variety of benchmarks.
The Order Effect: Investigating Prompt Sensitivity in Closed-Source LLMs
Feb 06, 2025



As large language models (LLMs) become integral to diverse applications, ensuring their reliability under varying input conditions is crucial. One key issue affecting this reliability is order sensitivity, wherein slight variations in input arrangement can lead to inconsistent or biased outputs. Although recent advances have reduced this sensitivity, the problem remains unresolved. This paper investigates the extent of order sensitivity in closed-source LLMs by conducting experiments across multiple tasks, including paraphrasing, relevance judgment, and multiple-choice questions. Our results show that input order significantly affects performance across tasks, with shuffled inputs leading to measurable declines in output accuracy. Few-shot prompting demonstrates mixed effectiveness and offers partial mitigation, however, fails to fully resolve the problem. These findings highlight persistent risks, particularly in high-stakes applications, and point to the need for more robust LLMs or improved input-handling techniques in future development.
ReGLA: Refining Gated Linear Attention
Feb 03, 2025Recent advancements in Large Language Models (LLMs) have set themselves apart with their exceptional performance in complex language modelling tasks. However, these models are also known for their significant computational and storage requirements, primarily due to the quadratic computation complexity of softmax attention. To mitigate this issue, linear attention has been designed to reduce the quadratic space-time complexity that is inherent in standard transformers. In this work, we embarked on a comprehensive exploration of three key components that substantially impact the performance of the Gated Linear Attention module: feature maps, normalization, and the gating mechanism. We developed a feature mapping function to address some crucial issues that previous suggestions overlooked. Then we offered further rationale for the integration of normalization layers to stabilize the training process. Moreover, we explored the saturation phenomenon of the gating mechanism and augmented it with a refining module. We conducted extensive experiments and showed our architecture outperforms previous Gated Linear Attention mechanisms in extensive tasks including training from scratch and post-linearization with continual pre-training.
Batch-Max: Higher LLM Throughput using Larger Batch Sizes and KV Cache Compression
Dec 07, 2024Several works have developed eviction policies to remove key-value (KV) pairs from the KV cache for more efficient inference. The focus has been on compressing the KV cache after the input prompt has been processed for faster token generation. In settings with limited GPU memory, and when the input context is longer than the generation length, we show that by also compressing the KV cache during the input processing phase, larger batch sizes can be used resulting in significantly higher throughput while still maintaining the original model's accuracy.
Do Robot Snakes Dream like Electric Sheep? Investigating the Effects of Architectural Inductive Biases on Hallucination
Oct 22, 2024



The growth in prominence of large language models (LLMs) in everyday life can be largely attributed to their generative abilities, yet some of this is also owed to the risks and costs associated with their use. On one front is their tendency to \textit{hallucinate} false or misleading information, limiting their reliability. On another is the increasing focus on the computational limitations associated with traditional self-attention based LLMs, which has brought about new alternatives, in particular recurrent models, meant to overcome them. Yet it remains uncommon to consider these two concerns simultaneously. Do changes in architecture exacerbate/alleviate existing concerns about hallucinations? Do they affect how and where they occur? Through an extensive evaluation, we study how these architecture-based inductive biases affect the propensity to hallucinate. While hallucination remains a general phenomenon not limited to specific architectures, the situations in which they occur and the ease with which specific types of hallucinations can be induced can significantly differ based on the model architecture. These findings highlight the need for better understanding both these problems in conjunction with each other, as well as consider how to design more universal techniques for handling hallucinations.
Draft on the Fly: Adaptive Self-Speculative Decoding using Cosine Similarity
Oct 01, 2024We present a simple on the fly method for faster inference of large language models. Unlike other (self-)speculative decoding techniques, our method does not require fine-tuning or black-box optimization to generate a fixed draft model, relying instead on simple rules to generate varying draft models adapted to the input context. We show empirically that our light-weight algorithm is competitive with the current SOTA for self-speculative decoding, while being a truly plug-and-play method.
EchoAtt: Attend, Copy, then Adjust for More Efficient Large Language Models
Sep 22, 2024



Large Language Models (LLMs), with their increasing depth and number of parameters, have demonstrated outstanding performance across a variety of natural language processing tasks. However, this growth in scale leads to increased computational demands, particularly during inference and fine-tuning. To address these challenges, we introduce EchoAtt, a novel framework aimed at optimizing transformer-based models by analyzing and leveraging the similarity of attention patterns across layers. Our analysis reveals that many inner layers in LLMs, especially larger ones, exhibit highly similar attention matrices. By exploiting this similarity, EchoAtt enables the sharing of attention matrices in less critical layers, significantly reducing computational requirements without compromising performance. We incorporate this approach within a knowledge distillation setup, where a pre-trained teacher model guides the training of a smaller student model. The student model selectively shares attention matrices in layers with high similarity while inheriting key parameters from the teacher. Our best results with TinyLLaMA-1.1B demonstrate that EchoAtt improves inference speed by 15\%, training speed by 25\%, and reduces the number of parameters by approximately 4\%, all while improving zero-shot performance. These findings highlight the potential of attention matrix sharing to enhance the efficiency of LLMs, making them more practical for real-time and resource-limited applications.