 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMO-SAE:Multi-Objective Stacked Autoencoders Optimization for Edge Anomaly Detection
Mar 14, 2026Stacked AutoEncoders (SAE) have been widely adopted in edge anomaly detection scenarios. However, the resource-intensive nature of SAE can pose significant challenges for edge devices, which are typically resource-constrained and must adapt rapidly to dynamic and changing conditions. Optimizing SAE to meet the heterogeneous demands of real-world deployment scenarios, including high performance under constrained storage, low power consumption, fast inference, and efficient model updates, remains a substantial challenge. To address this, we propose an integrated optimization framework that jointly considers these critical factors to achieve balanced and adaptive system-level optimization. Specifically, we formulate SAE optimization for edge anomaly detection as a multi-objective optimization problem and propose MO-SAE (Multi-Objective Stacked AutoEncoders). The multiple objectives are addressed by integrating model clipping, multi-branch exit design, and a matrix approximation technique. In addition, a multi-objective heuristic algorithm is employed to effectively balance the competing objectives in SAE optimization. Our results demonstrate that the proposed MO-SAE delivers substantial improvements over the original approach. On the x86 architecture, it reduces storage space and power consumption by at least 50%, improves runtime efficiency by no less than 28%, and achieves an 11.8% compression rate, all while maintaining application performance. Furthermore, MO-SAE runs efficiently on edge devices with ARM architecture. Experimental results show a 15% improvement in inference speed, facilitating efficient deployment in cloud-edge collaborative anomaly detection systems.
Enhancing Knowledge Graph Completion with GNN Distillation and Probabilistic Interaction Modeling
May 18, 2025Knowledge graphs (KGs) serve as fundamental structures for organizing interconnected data across diverse domains. However, most KGs remain incomplete, limiting their effectiveness in downstream applications. Knowledge graph completion (KGC) aims to address this issue by inferring missing links, but existing methods face critical challenges: deep graph neural networks (GNNs) suffer from over-smoothing, while embedding-based models fail to capture abstract relational features. This study aims to overcome these limitations by proposing a unified framework that integrates GNN distillation and abstract probabilistic interaction modeling (APIM). GNN distillation approach introduces an iterative message-feature filtering process to mitigate over-smoothing, preserving the discriminative power of node representations. APIM module complements this by learning structured, abstract interaction patterns through probabilistic signatures and transition matrices, allowing for a richer, more flexible representation of entity and relation interactions. We apply these methods to GNN-based models and the APIM to embedding-based KGC models, conducting extensive evaluations on the widely used WN18RR and FB15K-237 datasets. Our results demonstrate significant performance gains over baseline models, showcasing the effectiveness of the proposed techniques. The findings highlight the importance of both controlling information propagation and leveraging structured probabilistic modeling, offering new avenues for advancing knowledge graph completion. And our codes are available at https://anonymous.4open.science/r/APIM_and_GNN-Distillation-461C.
Pre-training Language Models with Deterministic Factual Knowledge
Oct 20, 2022
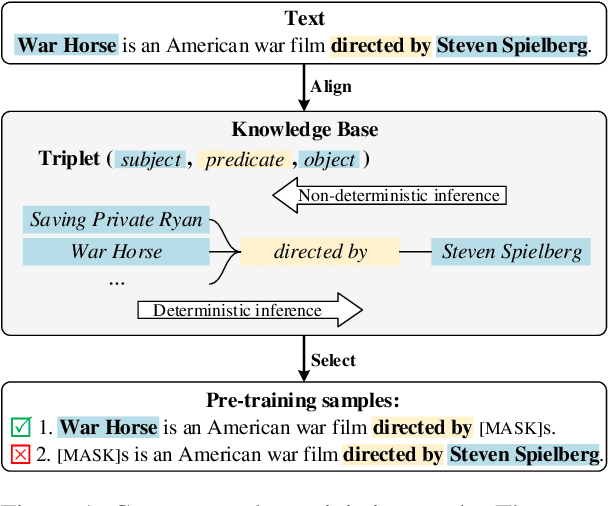

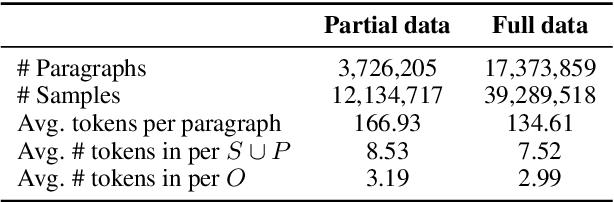
Previous works show that Pre-trained Language Models (PLMs) can capture factual knowledge. However, some analyses reveal that PLMs fail to perform it robustly, e.g., being sensitive to the changes of prompts when extracting factual knowledge. To mitigate this issue, we propose to let PLMs learn the deterministic relationship between the remaining context and the masked content. The deterministic relationship ensures that the masked factual content can be deterministically inferable based on the existing clues in the context. That would provide more stable patterns for PLMs to capture factual knowledge than randomly masking. Two pre-training tasks are further introduced to motivate PLMs to rely on the deterministic relationship when filling masks. Specifically, we use an external Knowledge Base (KB) to identify deterministic relationships and continuously pre-train PLMs with the proposed methods. The factual knowledge probing experiments indicate that the continuously pre-trained PLMs achieve better robustness in factual knowledge capturing. Further experiments on question-answering datasets show that trying to learn a deterministic relationship with the proposed methods can also help other knowledge-intensive tasks.
How Pre-trained Language Models Capture Factual Knowledge? A Causal-Inspired Analysis
Mar 31, 2022
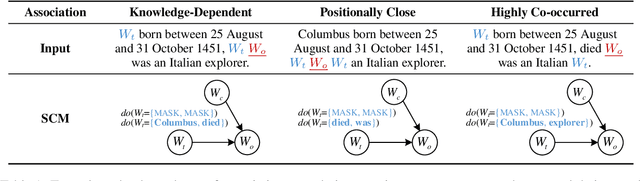
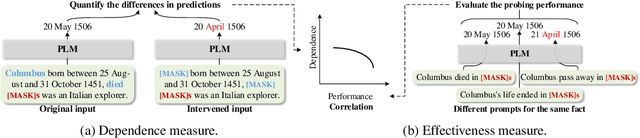
Recently, there has been a trend to investigate the factual knowledge captured by Pre-trained Language Models (PLMs). Many works show the PLMs' ability to fill in the missing factual words in cloze-style prompts such as "Dante was born in [MASK]." However, it is still a mystery how PLMs generate the results correctly: relying on effective clues or shortcut patterns? We try to answer this question by a causal-inspired analysis that quantitatively measures and evaluates the word-level patterns that PLMs depend on to generate the missing words. We check the words that have three typical associations with the missing words: knowledge-dependent, positionally close, and highly co-occurred. Our analysis shows: (1) PLMs generate the missing factual words more by the positionally close and highly co-occurred words than the knowledge-dependent words; (2) the dependence on the knowledge-dependent words is more effective than the positionally close and highly co-occurred words. Accordingly, we conclude that the PLMs capture the factual knowledge ineffectively because of depending on the inadequate associations.
Integrating Regular Expressions with Neural Networks via DFA
Sep 07, 2021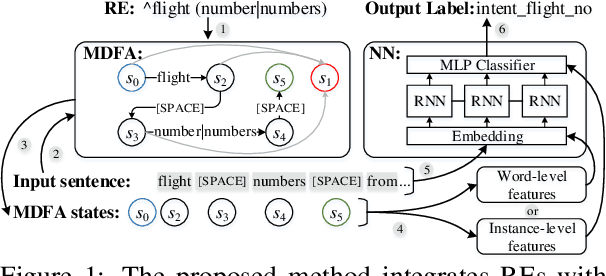
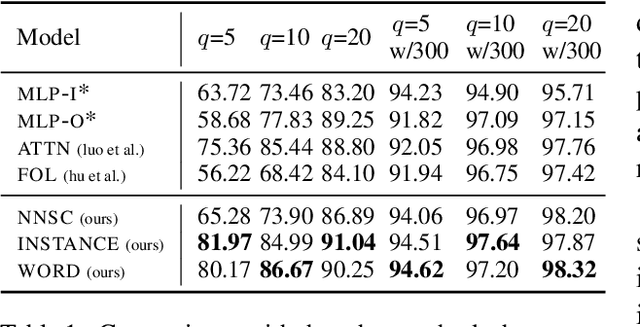
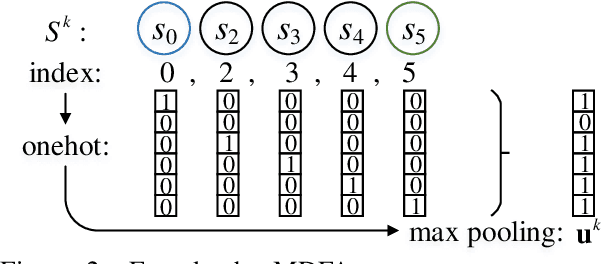
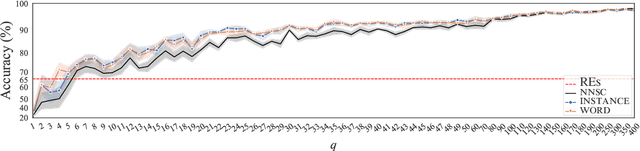
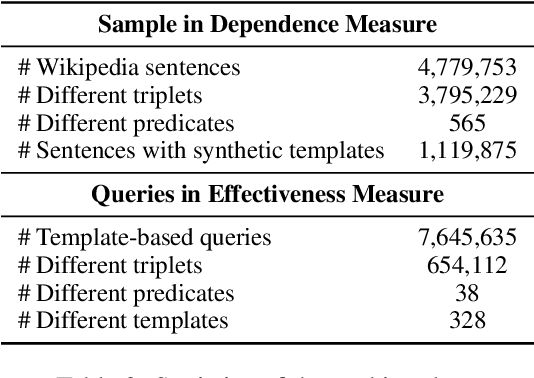
Human-designed rules are widely used to build industry applications. However, it is infeasible to maintain thousands of such hand-crafted rules. So it is very important to integrate the rule knowledge into neural networks to build a hybrid model that achieves better performance. Specifically, the human-designed rules are formulated as Regular Expressions (REs), from which the equivalent Minimal Deterministic Finite Automatons (MDFAs) are constructed. We propose to use the MDFA as an intermediate model to capture the matched RE patterns as rule-based features for each input sentence and introduce these additional features into neural networks. We evaluate the proposed method on the ATIS intent classification task. The experiment results show that the proposed method achieves the best performance compared to neural networks and four other methods that combine REs and neural networks when the training dataset is relatively small.
HopRetriever: Retrieve Hops over Wikipedia to Answer Complex Questions
Dec 31, 2020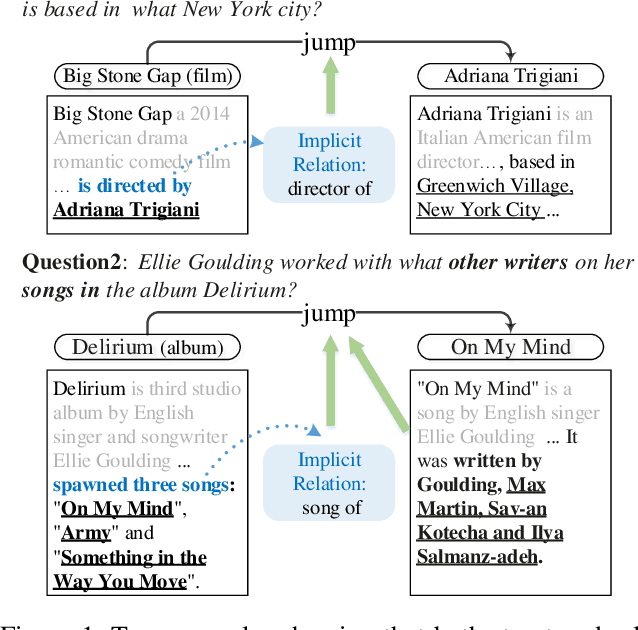

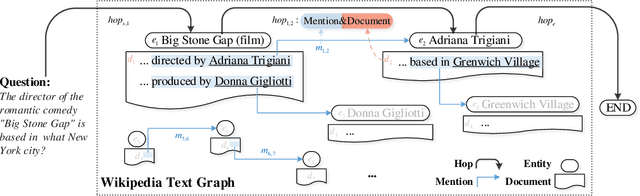

Collecting supporting evidence from large corpora of text (e.g., Wikipedia) is of great challenge for open-domain Question Answering (QA). Especially, for multi-hop open-domain QA, scattered evidence pieces are required to be gathered together to support the answer extraction. In this paper, we propose a new retrieval target, hop, to collect the hidden reasoning evidence from Wikipedia for complex question answering. Specifically, the hop in this paper is defined as the combination of a hyperlink and the corresponding outbound link document. The hyperlink is encoded as the mention embedding which models the structured knowledge of how the outbound link entity is mentioned in the textual context, and the corresponding outbound link document is encoded as the document embedding representing the unstructured knowledge within it. Accordingly, we build HopRetriever which retrieves hops over Wikipedia to answer complex questions. Experiments on the HotpotQA dataset demonstrate that HopRetriever outperforms previously published evidence retrieval methods by large margins. Moreover, our approach also yields quantifiable interpretations of the evidence collection process.
Radical-Enhanced Chinese Character Embedding
Apr 18, 2014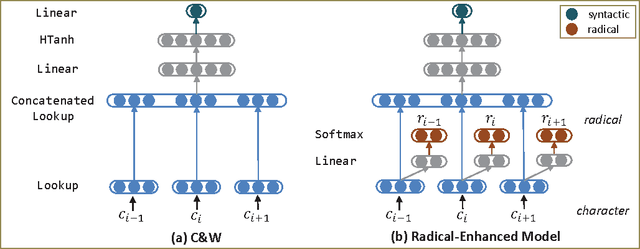

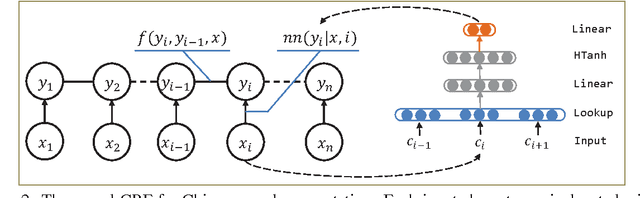
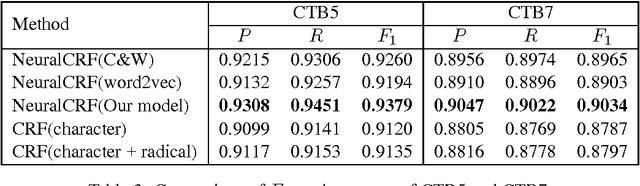
We present a method to leverage radical for learning Chinese character embedding. Radical is a semantic and phonetic component of Chinese character. It plays an important role as characters with the same radical usually have similar semantic meaning and grammatical usage. However, existing Chinese processing algorithms typically regard word or character as the basic unit but ignore the crucial radical information. In this paper, we fill this gap by leveraging radical for learning continuous representation of Chinese character. We develop a dedicated neural architecture to effectively learn character embedding and apply it on Chinese character similarity judgement and Chinese word segmentation. Experiment results show that our radical-enhanced method outperforms existing embedding learning algorithms on both tasks.