 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEWEK-QA: Enhanced Web and Efficient Knowledge Graph Retrieval for Citation-based Question Answering Systems
Jun 14, 2024



The emerging citation-based QA systems are gaining more attention especially in generative AI search applications. The importance of extracted knowledge provided to these systems is vital from both accuracy (completeness of information) and efficiency (extracting the information in a timely manner). In this regard, citation-based QA systems are suffering from two shortcomings. First, they usually rely only on web as a source of extracted knowledge and adding other external knowledge sources can hamper the efficiency of the system. Second, web-retrieved contents are usually obtained by some simple heuristics such as fixed length or breakpoints which might lead to splitting information into pieces. To mitigate these issues, we propose our enhanced web and efficient knowledge graph (KG) retrieval solution (EWEK-QA) to enrich the content of the extracted knowledge fed to the system. This has been done through designing an adaptive web retriever and incorporating KGs triples in an efficient manner. We demonstrate the effectiveness of EWEK-QA over the open-source state-of-the-art (SoTA) web-based and KG baseline models using a comprehensive set of quantitative and human evaluation experiments. Our model is able to: first, improve the web-retriever baseline in terms of extracting more relevant passages (>20\%), the coverage of answer span (>25\%) and self containment (>35\%); second, obtain and integrate KG triples into its pipeline very efficiently (by avoiding any LLM calls) to outperform the web-only and KG-only SoTA baselines significantly in 7 quantitative QA tasks and our human evaluation.
CHARP: Conversation History AwaReness Probing for Knowledge-grounded Dialogue Systems
May 24, 2024



In this work, we dive deep into one of the popular knowledge-grounded dialogue benchmarks that focus on faithfulness, FaithDial. We show that a significant portion of the FaithDial data contains annotation artifacts, which may bias models towards completely ignoring the conversation history. We therefore introduce CHARP, a diagnostic test set, designed for an improved evaluation of hallucinations in conversational model. CHARP not only measures hallucination but also the compliance of the models to the conversation task. Our extensive analysis reveals that models primarily exhibit poor performance on CHARP due to their inability to effectively attend to and reason over the conversation history. Furthermore, the evaluation methods of FaithDial fail to capture these shortcomings, neglecting the conversational history. Our findings indicate that there is substantial room for contribution in both dataset creation and hallucination evaluation for knowledge-grounded dialogue, and that CHARP can serve as a tool for monitoring the progress in this particular research area. CHARP is publicly available at https://huggingface.co/datasets/huawei-noah/CHARP
NoMIRACL: Knowing When You Don't Know for Robust Multilingual Retrieval-Augmented Generation
Dec 18, 2023



Retrieval-augmented generation (RAG) grounds large language model (LLM) output by leveraging external knowledge sources to reduce factual hallucinations. However, prior works lack a comprehensive evaluation of different language families, making it challenging to evaluate LLM robustness against errors in external retrieved knowledge. To overcome this, we establish NoMIRACL, a human-annotated dataset for evaluating LLM robustness in RAG across 18 typologically diverse languages. NoMIRACL includes both a non-relevant and a relevant subset. Queries in the non-relevant subset contain passages manually judged as non-relevant or noisy, whereas queries in the relevant subset include at least a single judged relevant passage. We measure LLM robustness using two metrics: (i) hallucination rate, measuring model tendency to hallucinate an answer, when the answer is not present in passages in the non-relevant subset, and (ii) error rate, measuring model inaccuracy to recognize relevant passages in the relevant subset. We build a GPT-4 baseline which achieves a 33.2% hallucination rate on the non-relevant and a 14.9% error rate on the relevant subset on average. Our evaluation reveals that GPT-4 hallucinates frequently in high-resource languages, such as French or English. This work highlights an important avenue for future research to improve LLM robustness to learn how to better reject non-relevant information in RAG.
Evaluating Embedding APIs for Information Retrieval
May 10, 2023


The ever-increasing size of language models curtails their widespread access to the community, thereby galvanizing many companies and startups into offering access to large language models through APIs. One particular API, suitable for dense retrieval, is the semantic embedding API that builds vector representations of a given text. With a growing number of APIs at our disposal, in this paper, our goal is to analyze semantic embedding APIs in realistic retrieval scenarios in order to assist practitioners and researchers in finding suitable services according to their needs. Specifically, we wish to investigate the capabilities of existing APIs on domain generalization and multilingual retrieval. For this purpose, we evaluate the embedding APIs on two standard benchmarks, BEIR, and MIRACL. We find that re-ranking BM25 results using the APIs is a budget-friendly approach and is most effective on English, in contrast to the standard practice, i.e., employing them as first-stage retrievers. For non-English retrieval, re-ranking still improves the results, but a hybrid model with BM25 works best albeit at a higher cost. We hope our work lays the groundwork for thoroughly evaluating APIs that are critical in search and more broadly, in information retrieval.
Simple Yet Effective Neural Ranking and Reranking Baselines for Cross-Lingual Information Retrieval
Apr 03, 2023The advent of multilingual language models has generated a resurgence of interest in cross-lingual information retrieval (CLIR), which is the task of searching documents in one language with queries from another. However, the rapid pace of progress has led to a confusing panoply of methods and reproducibility has lagged behind the state of the art. In this context, our work makes two important contributions: First, we provide a conceptual framework for organizing different approaches to cross-lingual retrieval using multi-stage architectures for mono-lingual retrieval as a scaffold. Second, we implement simple yet effective reproducible baselines in the Anserini and Pyserini IR toolkits for test collections from the TREC 2022 NeuCLIR Track, in Persian, Russian, and Chinese. Our efforts are built on a collaboration of the two teams that submitted the most effective runs to the TREC evaluation. These contributions provide a firm foundation for future advances.
Making a MIRACL: Multilingual Information Retrieval Across a Continuum of Languages
Oct 18, 2022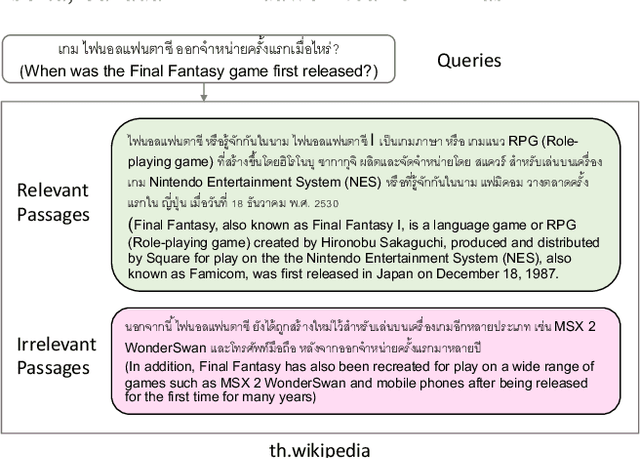
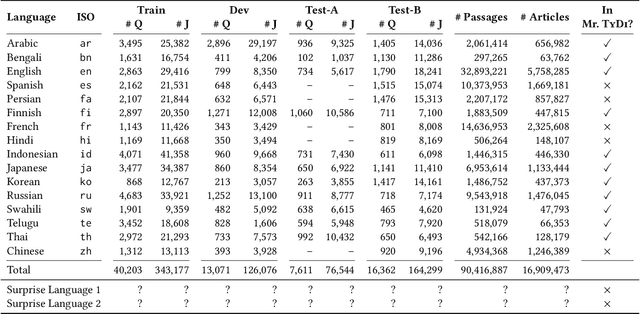
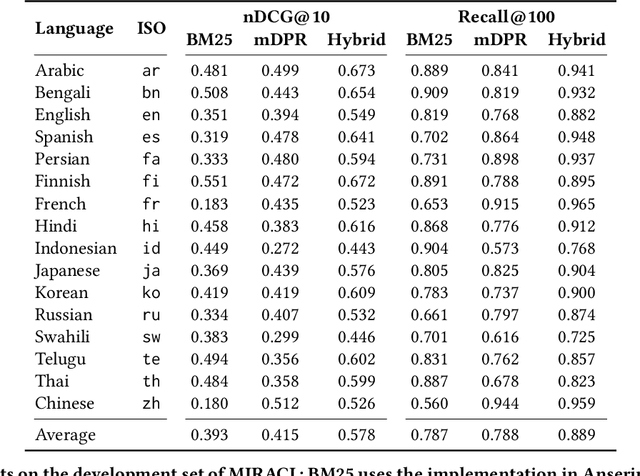
MIRACL (Multilingual Information Retrieval Across a Continuum of Languages) is a multilingual dataset we have built for the WSDM 2023 Cup challenge that focuses on ad hoc retrieval across 18 different languages, which collectively encompass over three billion native speakers around the world. These languages have diverse typologies, originate from many different language families, and are associated with varying amounts of available resources -- including what researchers typically characterize as high-resource as well as low-resource languages. Our dataset is designed to support the creation and evaluation of models for monolingual retrieval, where the queries and the corpora are in the same language. In total, we have gathered over 700k high-quality relevance judgments for around 77k queries over Wikipedia in these 18 languages, where all assessments have been performed by native speakers hired by our team. Our goal is to spur research that will improve retrieval across a continuum of languages, thus enhancing information access capabilities for diverse populations around the world, particularly those that have been traditionally underserved. This overview paper describes the dataset and baselines that we share with the community. The MIRACL website is live at http://miracl.ai/.
NATURE: Natural Auxiliary Text Utterances for Realistic Spoken Language Evaluation
Nov 09, 2021
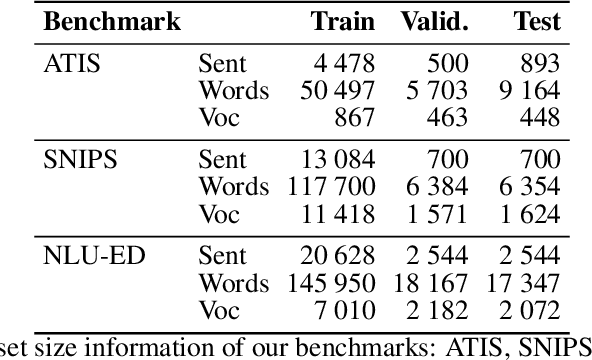
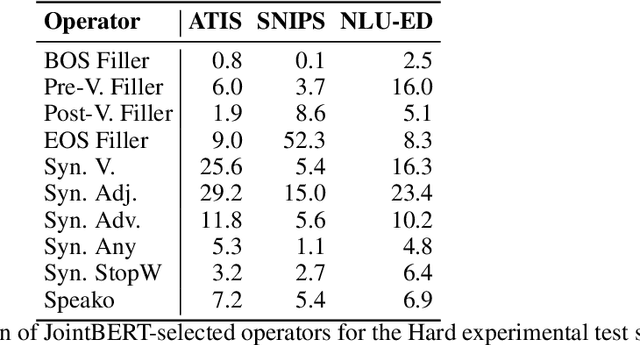
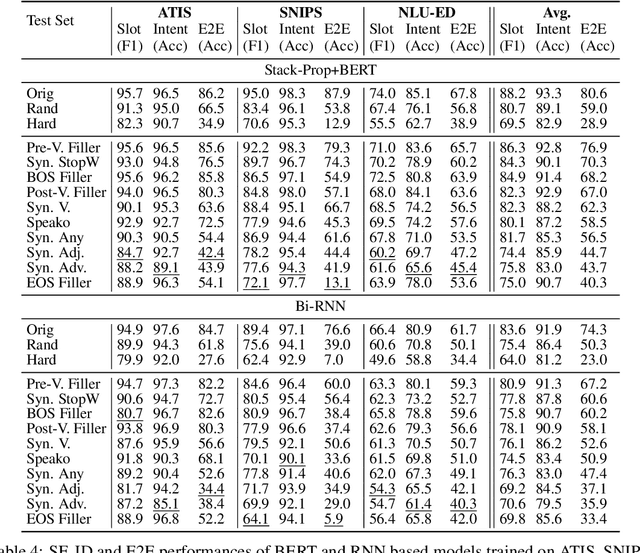
Slot-filling and intent detection are the backbone of conversational agents such as voice assistants, and are active areas of research. Even though state-of-the-art techniques on publicly available benchmarks show impressive performance, their ability to generalize to realistic scenarios is yet to be demonstrated. In this work, we present NATURE, a set of simple spoken-language oriented transformations, applied to the evaluation set of datasets, to introduce human spoken language variations while preserving the semantics of an utterance. We apply NATURE to common slot-filling and intent detection benchmarks and demonstrate that simple perturbations from the standard evaluation set by NATURE can deteriorate model performance significantly. Through our experiments we demonstrate that when NATURE operators are applied to evaluation set of popular benchmarks the model accuracy can drop by up to 40%.