 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Latency Privacy-Preserving Deep Learning Design via Secure MPC
Jul 24, 2024Secure multi-party computation (MPC) facilitates privacy-preserving computation between multiple parties without leaking private information. While most secure deep learning techniques utilize MPC operations to achieve feasible privacy-preserving machine learning on downstream tasks, the overhead of the computation and communication still hampers their practical application. This work proposes a low-latency secret-sharing-based MPC design that reduces unnecessary communication rounds during the execution of MPC protocols. We also present a method for improving the computation of commonly used nonlinear functions in deep learning by integrating multivariate multiplication and coalescing different packets into one to maximize network utilization. Our experimental results indicate that our method is effective in a variety of settings, with a speedup in communication latency of $10\sim20\%$.
Diffree: Text-Guided Shape Free Object Inpainting with Diffusion Model
Jul 24, 2024



This paper addresses an important problem of object addition for images with only text guidance. It is challenging because the new object must be integrated seamlessly into the image with consistent visual context, such as lighting, texture, and spatial location. While existing text-guided image inpainting methods can add objects, they either fail to preserve the background consistency or involve cumbersome human intervention in specifying bounding boxes or user-scribbled masks. To tackle this challenge, we introduce Diffree, a Text-to-Image (T2I) model that facilitates text-guided object addition with only text control. To this end, we curate OABench, an exquisite synthetic dataset by removing objects with advanced image inpainting techniques. OABench comprises 74K real-world tuples of an original image, an inpainted image with the object removed, an object mask, and object descriptions. Trained on OABench using the Stable Diffusion model with an additional mask prediction module, Diffree uniquely predicts the position of the new object and achieves object addition with guidance from only text. Extensive experiments demonstrate that Diffree excels in adding new objects with a high success rate while maintaining background consistency, spatial appropriateness, and object relevance and quality.
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
Jul 18, 2024Research on scaling large language models (LLMs) has primarily focused on model parameters and training data size, overlooking the role of vocabulary size. % Intuitively, larger vocabularies enable more efficient tokenization by representing sentences with fewer tokens, but they also increase the risk of under-fitting representations for rare tokens. We investigate how vocabulary size impacts LLM scaling laws by training models ranging from 33M to 3B parameters on up to 500B characters with various vocabulary configurations. We propose three complementary approaches for predicting the compute-optimal vocabulary size: IsoFLOPs analysis, derivative estimation, and parametric fit of the loss function. Our approaches converge on the same result that the optimal vocabulary size depends on the available compute budget and that larger models deserve larger vocabularies. However, most LLMs use too small vocabulary sizes. For example, we predict that the optimal vocabulary size of Llama2-70B should have been at least 216K, 7 times larger than its vocabulary of 32K. We validate our predictions empirically by training models with 3B parameters across different FLOPs budgets. Adopting our predicted optimal vocabulary size consistently improves downstream performance over commonly used vocabulary sizes. By increasing the vocabulary size from the conventional 32K to 43K, we improve performance on ARC-Challenge from 29.1 to 32.0 with the same 2.3e21 FLOPs. Our work emphasizes the necessity of jointly considering model parameters and vocabulary size for efficient scaling.
TCFormer: Visual Recognition via Token Clustering Transformer
Jul 16, 2024



Transformers are widely used in computer vision areas and have achieved remarkable success. Most state-of-the-art approaches split images into regular grids and represent each grid region with a vision token. However, fixed token distribution disregards the semantic meaning of different image regions, resulting in sub-optimal performance. To address this issue, we propose the Token Clustering Transformer (TCFormer), which generates dynamic vision tokens based on semantic meaning. Our dynamic tokens possess two crucial characteristics: (1) Representing image regions with similar semantic meanings using the same vision token, even if those regions are not adjacent, and (2) concentrating on regions with valuable details and represent them using fine tokens. Through extensive experimentation across various applications, including image classification, human pose estimation, semantic segmentation, and object detection, we demonstrate the effectiveness of our TCFormer. The code and models for this work are available at https://github.com/zengwang430521/TCFormer.
Segment, Lift and Fit: Automatic 3D Shape Labeling from 2D Prompts
Jul 16, 2024

This paper proposes an algorithm for automatically labeling 3D objects from 2D point or box prompts, especially focusing on applications in autonomous driving. Unlike previous arts, our auto-labeler predicts 3D shapes instead of bounding boxes and does not require training on a specific dataset. We propose a Segment, Lift, and Fit (SLF) paradigm to achieve this goal. Firstly, we segment high-quality instance masks from the prompts using the Segment Anything Model (SAM) and transform the remaining problem into predicting 3D shapes from given 2D masks. Due to the ill-posed nature of this problem, it presents a significant challenge as multiple 3D shapes can project into an identical mask. To tackle this issue, we then lift 2D masks to 3D forms and employ gradient descent to adjust their poses and shapes until the projections fit the masks and the surfaces conform to surrounding LiDAR points. Notably, since we do not train on a specific dataset, the SLF auto-labeler does not overfit to biased annotation patterns in the training set as other methods do. Thus, the generalization ability across different datasets improves. Experimental results on the KITTI dataset demonstrate that the SLF auto-labeler produces high-quality bounding box annotations, achieving an AP@0.5 IoU of nearly 90\%. Detectors trained with the generated pseudo-labels perform nearly as well as those trained with actual ground-truth annotations. Furthermore, the SLF auto-labeler shows promising results in detailed shape predictions, providing a potential alternative for the occupancy annotation of dynamic objects.
When Pedestrian Detection Meets Multi-Modal Learning: Generalist Model and Benchmark Dataset
Jul 14, 2024Recent years have witnessed increasing research attention towards pedestrian detection by taking the advantages of different sensor modalities (e.g. RGB, IR, Depth, LiDAR and Event). However, designing a unified generalist model that can effectively process diverse sensor modalities remains a challenge. This paper introduces MMPedestron, a novel generalist model for multimodal perception. Unlike previous specialist models that only process one or a pair of specific modality inputs, MMPedestron is able to process multiple modal inputs and their dynamic combinations. The proposed approach comprises a unified encoder for modal representation and fusion and a general head for pedestrian detection. We introduce two extra learnable tokens, i.e. MAA and MAF, for adaptive multi-modal feature fusion. In addition, we construct the MMPD dataset, the first large-scale benchmark for multi-modal pedestrian detection. This benchmark incorporates existing public datasets and a newly collected dataset called EventPed, covering a wide range of sensor modalities including RGB, IR, Depth, LiDAR, and Event data. With multi-modal joint training, our model achieves state-of-the-art performance on a wide range of pedestrian detection benchmarks, surpassing leading models tailored for specific sensor modality. For example, it achieves 71.1 AP on COCO-Persons and 72.6 AP on LLVIP. Notably, our model achieves comparable performance to the InternImage-H model on CrowdHuman with 30x smaller parameters. Codes and data are available at https://github.com/BubblyYi/MMPedestron.
IDA-VLM: Towards Movie Understanding via ID-Aware Large Vision-Language Model
Jul 10, 2024



The rapid advancement of Large Vision-Language models (LVLMs) has demonstrated a spectrum of emergent capabilities. Nevertheless, current models only focus on the visual content of a single scenario, while their ability to associate instances across different scenes has not yet been explored, which is essential for understanding complex visual content, such as movies with multiple characters and intricate plots. Towards movie understanding, a critical initial step for LVLMs is to unleash the potential of character identities memory and recognition across multiple visual scenarios. To achieve the goal, we propose visual instruction tuning with ID reference and develop an ID-Aware Large Vision-Language Model, IDA-VLM. Furthermore, our research introduces a novel benchmark MM-ID, to examine LVLMs on instance IDs memory and recognition across four dimensions: matching, location, question-answering, and captioning. Our findings highlight the limitations of existing LVLMs in recognizing and associating instance identities with ID reference. This paper paves the way for future artificial intelligence systems to possess multi-identity visual inputs, thereby facilitating the comprehension of complex visual narratives like movies.
PhyBench: A Physical Commonsense Benchmark for Evaluating Text-to-Image Models
Jun 17, 2024
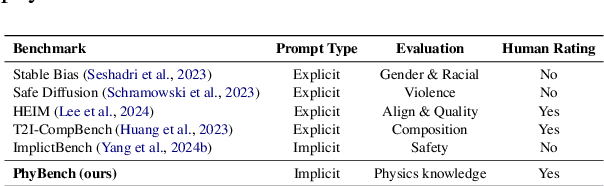

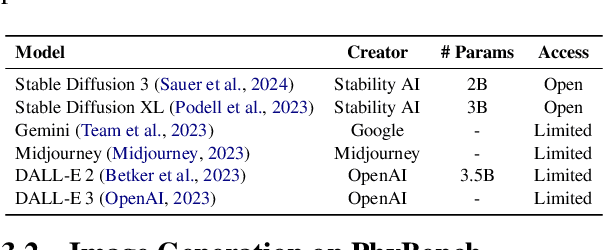
Text-to-image (T2I) models have made substantial progress in generating images from textual prompts. However, they frequently fail to produce images consistent with physical commonsense, a vital capability for applications in world simulation and everyday tasks. Current T2I evaluation benchmarks focus on metrics such as accuracy, bias, and safety, neglecting the evaluation of models' internal knowledge, particularly physical commonsense. To address this issue, we introduce PhyBench, a comprehensive T2I evaluation dataset comprising 700 prompts across 4 primary categories: mechanics, optics, thermodynamics, and material properties, encompassing 31 distinct physical scenarios. We assess 6 prominent T2I models, including proprietary models DALLE3 and Gemini, and demonstrate that incorporating physical principles into prompts enhances the models' ability to generate physically accurate images. Our findings reveal that: (1) even advanced models frequently err in various physical scenarios, except for optics; (2) GPT-4o, with item-specific scoring instructions, effectively evaluates the models' understanding of physical commonsense, closely aligning with human assessments; and (3) current T2I models are primarily focused on text-to-image translation, lacking profound reasoning regarding physical commonsense. We advocate for increased attention to the inherent knowledge within T2I models, beyond their utility as mere image generation tools. The code and data are available at https://github.com/OpenGVLab/PhyBench.
DAG-Plan: Generating Directed Acyclic Dependency Graphs for Dual-Arm Cooperative Planning
Jun 14, 2024Dual-arm robots offer enhanced versatility and efficiency over single-arm counterparts by enabling concurrent manipulation of multiple objects or cooperative execution of tasks using both arms. However, effectively coordinating the two arms for complex long-horizon tasks remains a significant challenge. Existing task planning methods predominantly focus on single-arm robots or rely on predefined bimanual operations, failing to fully leverage the capabilities of dual-arm systems. To address this limitation, we introduce DAG-Plan, a structured task planning framework tailored for dual-arm robots. DAG-Plan harnesses large language models (LLMs) to decompose intricate tasks into actionable sub-tasks represented as nodes within a directed acyclic graph (DAG). Critically, DAG-Plan dynamically assigns these sub-tasks to the appropriate arm based on real-time environmental observations, enabling parallel and adaptive execution. We evaluate DAG-Plan on the novel Dual-Arm Kitchen Benchmark, comprising 9 sequential tasks with 78 sub-tasks and 26 objects. Extensive experiments demonstrate the superiority of DAG-Plan over directly using LLM to generate plans, achieving nearly 50% higher efficiency compared to the single-arm task planning baseline and nearly double the success rate of the dual-arm task planning baseline.
Rethinking Human Evaluation Protocol for Text-to-Video Models: Enhancing Reliability,Reproducibility, and Practicality
Jun 13, 2024



Recent text-to-video (T2V) technology advancements, as demonstrated by models such as Gen2, Pika, and Sora, have significantly broadened its applicability and popularity. Despite these strides, evaluating these models poses substantial challenges. Primarily, due to the limitations inherent in automatic metrics, manual evaluation is often considered a superior method for assessing T2V generation. However, existing manual evaluation protocols face reproducibility, reliability, and practicality issues. To address these challenges, this paper introduces the Text-to-Video Human Evaluation (T2VHE) protocol, a comprehensive and standardized protocol for T2V models. The T2VHE protocol includes well-defined metrics, thorough annotator training, and an effective dynamic evaluation module. Experimental results demonstrate that this protocol not only ensures high-quality annotations but can also reduce evaluation costs by nearly 50%. We will open-source the entire setup of the T2VHE protocol, including the complete protocol workflow, the dynamic evaluation component details, and the annotation interface code. This will help communities establish more sophisticated human assessment protocols.