 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTLocating: Intent-aware RTL Localization for Hardware Design Iteration
Feb 28, 2026Industrial chip development is inherently iterative, favoring localized, intent-driven updates over rewriting RTL from scratch. Yet most LLM-Aided Hardware Design (LAD) work focuses on one-shot synthesis, leaving this workflow underexplored. To bridge this gap, we for the first time formalize $Δ$Spec-to-RTL localization, a multi-positive problem mapping natural language change requests ($Δ$Spec) to the affected Register Transfer Level (RTL) syntactic blocks. We propose RTLocating, an intent-aware RTL localization framework, featuring a dynamic router that adaptively fuses complementary views from a textual semantic encoder, a local structural encoder, and a global interaction and dependency encoder (GLIDE). To enable scalable supervision, we introduce EvoRTL-Bench, the first industrial-scale benchmark for intent-code alignment derived from OpenTitan's Git history, comprising 1,905 validated requests and 13,583 $Δ$Spec-RTL block pairs. On EvoRTL-Bench, RTLocating achieves 0.568 MRR and 15.08% R@1, outperforming the strongest baseline by +22.9% and +67.0%, respectively, establishing a new state-of-the-art for intent-driven localization in evolving hardware designs.
Unlocking Cognitive Capabilities and Analyzing the Perception-Logic Trade-off
Feb 27, 2026Recent advancements in Multimodal Large Language Models (MLLMs) pursue omni-perception capabilities, yet integrating robust sensory grounding with complex reasoning remains a challenge, particularly for underrepresented regions. In this report, we introduce the research preview of MERaLiON2-Omni (Alpha), a 10B-parameter multilingual omni-perception tailored for Southeast Asia (SEA). We present a progressive training pipeline that explicitly decouples and then integrates "System 1" (Perception) and "System 2" (Reasoning) capabilities. First, we establish a robust Perception Backbone by aligning region-specific audio-visual cues (e.g., Singlish code-switching, local cultural landmarks) with a multilingual LLM through orthogonal modality adaptation. Second, to inject cognitive capabilities without large-scale supervision, we propose a cost-effective Generate-Judge-Refine pipeline. By utilizing a Super-LLM to filter hallucinations and resolve conflicts via a consensus mechanism, we synthesize high-quality silver data that transfers textual Chain-of-Thought reasoning to multimodal scenarios. Comprehensive evaluation on our newly introduced SEA-Omni Benchmark Suite reveals an Efficiency-Stability Paradox: while reasoning acts as a non-linear amplifier for abstract tasks (boosting mathematical and instruction-following performance significantly), it introduces instability in low-level sensory processing. Specifically, we identify Temporal Drift in long-context audio, where extended reasoning desynchronizes the model from acoustic timestamps, and Visual Over-interpretation, where logic overrides pixel-level reality. This report details the architecture, the data-efficient training recipe, and a diagnostic analysis of the trade-offs between robust perception and structured reasoning.
ZFusion: An Effective Fuser of Camera and 4D Radar for 3D Object Perception in Autonomous Driving
Apr 07, 2025



Reliable 3D object perception is essential in autonomous driving. Owing to its sensing capabilities in all weather conditions, 4D radar has recently received much attention. However, compared to LiDAR, 4D radar provides much sparser point cloud. In this paper, we propose a 3D object detection method, termed ZFusion, which fuses 4D radar and vision modality. As the core of ZFusion, our proposed FP-DDCA (Feature Pyramid-Double Deformable Cross Attention) fuser complements the (sparse) radar information and (dense) vision information, effectively. Specifically, with a feature-pyramid structure, the FP-DDCA fuser packs Transformer blocks to interactively fuse multi-modal features at different scales, thus enhancing perception accuracy. In addition, we utilize the Depth-Context-Split view transformation module due to the physical properties of 4D radar. Considering that 4D radar has a much lower cost than LiDAR, ZFusion is an attractive alternative to LiDAR-based methods. In typical traffic scenarios like the VoD (View-of-Delft) dataset, experiments show that with reasonable inference speed, ZFusion achieved the state-of-the-art mAP (mean average precision) in the region of interest, while having competitive mAP in the entire area compared to the baseline methods, which demonstrates performance close to LiDAR and greatly outperforms those camera-only methods.
Cog-GA: A Large Language Models-based Generative Agent for Vision-Language Navigation in Continuous Environments
Sep 04, 2024Vision Language Navigation in Continuous Environments (VLN-CE) represents a frontier in embodied AI, demanding agents to navigate freely in unbounded 3D spaces solely guided by natural language instructions. This task introduces distinct challenges in multimodal comprehension, spatial reasoning, and decision-making. To address these challenges, we introduce Cog-GA, a generative agent founded on large language models (LLMs) tailored for VLN-CE tasks. Cog-GA employs a dual-pronged strategy to emulate human-like cognitive processes. Firstly, it constructs a cognitive map, integrating temporal, spatial, and semantic elements, thereby facilitating the development of spatial memory within LLMs. Secondly, Cog-GA employs a predictive mechanism for waypoints, strategically optimizing the exploration trajectory to maximize navigational efficiency. Each waypoint is accompanied by a dual-channel scene description, categorizing environmental cues into 'what' and 'where' streams as the brain. This segregation enhances the agent's attentional focus, enabling it to discern pertinent spatial information for navigation. A reflective mechanism complements these strategies by capturing feedback from prior navigation experiences, facilitating continual learning and adaptive replanning. Extensive evaluations conducted on VLN-CE benchmarks validate Cog-GA's state-of-the-art performance and ability to simulate human-like navigation behaviors. This research significantly contributes to the development of strategic and interpretable VLN-CE agents.
DAG-Plan: Generating Directed Acyclic Dependency Graphs for Dual-Arm Cooperative Planning
Jun 14, 2024Dual-arm robots offer enhanced versatility and efficiency over single-arm counterparts by enabling concurrent manipulation of multiple objects or cooperative execution of tasks using both arms. However, effectively coordinating the two arms for complex long-horizon tasks remains a significant challenge. Existing task planning methods predominantly focus on single-arm robots or rely on predefined bimanual operations, failing to fully leverage the capabilities of dual-arm systems. To address this limitation, we introduce DAG-Plan, a structured task planning framework tailored for dual-arm robots. DAG-Plan harnesses large language models (LLMs) to decompose intricate tasks into actionable sub-tasks represented as nodes within a directed acyclic graph (DAG). Critically, DAG-Plan dynamically assigns these sub-tasks to the appropriate arm based on real-time environmental observations, enabling parallel and adaptive execution. We evaluate DAG-Plan on the novel Dual-Arm Kitchen Benchmark, comprising 9 sequential tasks with 78 sub-tasks and 26 objects. Extensive experiments demonstrate the superiority of DAG-Plan over directly using LLM to generate plans, achieving nearly 50% higher efficiency compared to the single-arm task planning baseline and nearly double the success rate of the dual-arm task planning baseline.
Spiking Neural Network for Ultra-low-latency and High-accurate Object Detection
Jun 27, 2023



Spiking Neural Networks (SNNs) have garnered widespread interest for their energy efficiency and brain-inspired event-driven properties. While recent methods like Spiking-YOLO have expanded the SNNs to more challenging object detection tasks, they often suffer from high latency and low detection accuracy, making them difficult to deploy on latency sensitive mobile platforms. Furthermore, the conversion method from Artificial Neural Networks (ANNs) to SNNs is hard to maintain the complete structure of the ANNs, resulting in poor feature representation and high conversion errors. To address these challenges, we propose two methods: timesteps compression and spike-time-dependent integrated (STDI) coding. The former reduces the timesteps required in ANN-SNN conversion by compressing information, while the latter sets a time-varying threshold to expand the information holding capacity. We also present a SNN-based ultra-low latency and high accurate object detection model (SUHD) that achieves state-of-the-art performance on nontrivial datasets like PASCAL VOC and MS COCO, with about remarkable 750x fewer timesteps and 30% mean average precision (mAP) improvement, compared to the Spiking-YOLO on MS COCO datasets. To the best of our knowledge, SUHD is the deepest spike-based object detection model to date that achieves ultra low timesteps to complete the lossless conversion.
Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model
Oct 08, 2022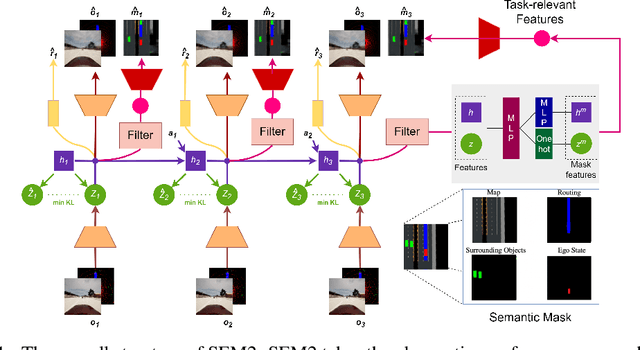

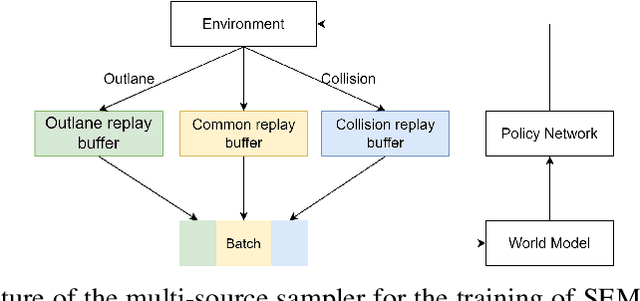
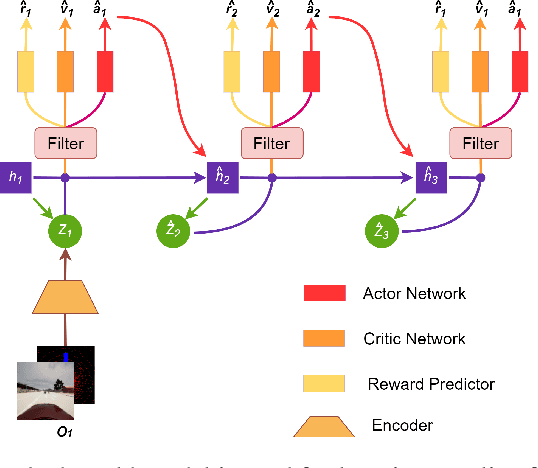
End-to-end autonomous driving provides a feasible way to automatically maximize overall driving system performance by directly mapping the raw pixels from a front-facing camera to control signals. Recent advanced methods construct a latent world model to map the high dimensional observations into compact latent space. However, the latent states embedded by the world model proposed in previous works may contain a large amount of task-irrelevant information, resulting in low sampling efficiency and poor robustness to input perturbations. Meanwhile, the training data distribution is usually unbalanced, and the learned policy is hard to cope with the corner cases during the driving process. To solve the above challenges, we present a semantic masked recurrent world model (SEM2), which introduces a latent filter to extract key task-relevant features and reconstruct a semantic mask via the filtered features, and is trained with a multi-source data sampler, which aggregates common data and multiple corner case data in a single batch, to balance the data distribution. Extensive experiments on CARLA show that our method outperforms the state-of-the-art approaches in terms of sample efficiency and robustness to input permutations.