 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Face Recognition under Different Backbones
Jan 23, 2026Erratum to the paper (Zhang et al., 2025): corrections to Table IV and the data in Page 3, Section A. In the post-pandemic era, a high proportion of civil aviation passengers wear masks during security checks, posing significant challenges to traditional face recognition models. The backbone network serves as the core component of face recognition models. In standard tests, r100 series models excelled (98%+ accuracy at 0.01% FAR in face comparison, high top1/top5 in search). r50 ranked second, r34_mask_v1 lagged. In masked tests, r100_mask_v2 led (90.07% accuracy), r50_mask_v3 performed best among r50 but trailed r100. Vit-Small/Tiny showed strong masked performance with gains in effectiveness. Through extensive comparative experiments, this paper conducts a comprehensive evaluation of several core backbone networks, aiming to reveal the impacts of different models on face recognition with and without masks, and provide specific deployment recommendations.
Can Deep Research Agents Find and Organize? Evaluating the Synthesis Gap with Expert Taxonomies
Jan 18, 2026Deep Research Agents are increasingly used for automated survey generation. However, whether they can write surveys like human experts remains unclear. Existing benchmarks focus on fluency or citation accuracy, but none evaluates the core capabilities: retrieving essential papers and organizing them into coherent knowledge structures. We introduce TaxoBench, a diagnostic benchmark derived from 72 highly-cited computer science surveys. We manually extract expert-authored taxonomy trees containing 3,815 precisely categorized citations as ground truth. Our benchmark supports two evaluation modes: Deep Research mode tests end-to-end retrieval and organization given only a topic, while Bottom-Up mode isolates structuring capability by providing the exact papers human experts used. We evaluate 7 leading Deep Research agents and 12 frontier LLMs. Results reveal a dual bottleneck: the best agent recalls only 20.9% of expert-selected papers, and even with perfect input, the best model achieves only 0.31 ARI in organization. Current deep research agents remain far from expert-level survey writing. Our benchmark is publicly available at https://github.com/KongLongGeFDU/TaxoBench.
Muse: Towards Reproducible Long-Form Song Generation with Fine-Grained Style Control
Jan 08, 2026Recent commercial systems such as Suno demonstrate strong capabilities in long-form song generation, while academic research remains largely non-reproducible due to the lack of publicly available training data, hindering fair comparison and progress. To this end, we release a fully open-source system for long-form song generation with fine-grained style conditioning, including a licensed synthetic dataset, training and evaluation pipelines, and Muse, an easy-to-deploy song generation model. The dataset consists of 116k fully licensed synthetic songs with automatically generated lyrics and style descriptions paired with audio synthesized by SunoV5. We train Muse via single-stage supervised finetuning of a Qwen-based language model extended with discrete audio tokens using MuCodec, without task-specific losses, auxiliary objectives, or additional architectural components. Our evaluations find that although Muse is trained with a modest data scale and model size, it achieves competitive performance on phoneme error rate, text--music style similarity, and audio aesthetic quality, while enabling controllable segment-level generation across different musical structures. All data, model weights, and training and evaluation pipelines will be publicly released, paving the way for continued progress in controllable long-form song generation research. The project repository is available at https://github.com/yuhui1038/Muse.
OpenNovelty: An LLM-powered Agentic System for Verifiable Scholarly Novelty Assessment
Jan 04, 2026Evaluating novelty is critical yet challenging in peer review, as reviewers must assess submissions against a vast, rapidly evolving literature. This report presents OpenNovelty, an LLM-powered agentic system for transparent, evidence-based novelty analysis. The system operates through four phases: (1) extracting the core task and contribution claims to generate retrieval queries; (2) retrieving relevant prior work based on extracted queries via semantic search engine; (3) constructing a hierarchical taxonomy of core-task-related work and performing contribution-level full-text comparisons against each contribution; and (4) synthesizing all analyses into a structured novelty report with explicit citations and evidence snippets. Unlike naive LLM-based approaches, \textsc{OpenNovelty} grounds all assessments in retrieved real papers, ensuring verifiable judgments. We deploy our system on 500+ ICLR 2026 submissions with all reports publicly available on our website, and preliminary analysis suggests it can identify relevant prior work, including closely related papers that authors may overlook. OpenNovelty aims to empower the research community with a scalable tool that promotes fair, consistent, and evidence-backed peer review.
OxygenREC: An Instruction-Following Generative Framework for E-commerce Recommendation
Dec 31, 2025Traditional recommendation systems suffer from inconsistency in multi-stage optimization objectives. Generative Recommendation (GR) mitigates them through an end-to-end framework; however, existing methods still rely on matching mechanisms based on inductive patterns. Although responsive, they lack the ability to uncover complex user intents that require deductive reasoning based on world knowledge. Meanwhile, LLMs show strong deep reasoning capabilities, but their latency and computational costs remain challenging for industrial applications. More critically, there are performance bottlenecks in multi-scenario scalability: as shown in Figure 1, existing solutions require independent training and deployment for each scenario, leading to low resource utilization and high maintenance costs-a challenge unaddressed in GR literature. To address these, we present OxygenREC, an industrial recommendation system that leverages Fast-Slow Thinking to deliver deep reasoning with strict latency and multi-scenario requirements of real-world environments. First, we adopt a Fast-Slow Thinking architecture. Slow thinking uses a near-line LLM pipeline to synthesize Contextual Reasoning Instructions, while fast thinking employs a high-efficiency encoder-decoder backbone for real-time generation. Second, to ensure reasoning instructions effectively enhance recommendation generation, we introduce a semantic alignment mechanism with Instruction-Guided Retrieval (IGR) to filter intent-relevant historical behaviors and use a Query-to-Item (Q2I) loss for instruction-item consistency. Finally, to resolve multi-scenario scalability, we transform scenario information into controllable instructions, using unified reward mapping and Soft Adaptive Group Clip Policy Optimization (SA-GCPO) to align policies with diverse business objectives, realizing a train-once-deploy-everywhere paradigm.
VSA:Visual-Structural Alignment for UI-to-Code
Dec 23, 2025


The automation of user interface development has the potential to accelerate software delivery by mitigating intensive manual implementation. Despite the advancements in Large Multimodal Models for design-to-code translation, existing methodologies predominantly yield unstructured, flat codebases that lack compatibility with component-oriented libraries such as React or Angular. Such outputs typically exhibit low cohesion and high coupling, complicating long-term maintenance. In this paper, we propose \textbf{VSA (VSA)}, a multi-stage paradigm designed to synthesize organized frontend assets through visual-structural alignment. Our approach first employs a spatial-aware transformer to reconstruct the visual input into a hierarchical tree representation. Moving beyond basic layout extraction, we integrate an algorithmic pattern-matching layer to identify recurring UI motifs and encapsulate them into modular templates. These templates are then processed via a schema-driven synthesis engine, ensuring the Large Language Model generates type-safe, prop-drilled components suitable for production environments. Experimental results indicate that our framework yields a substantial improvement in code modularity and architectural consistency over state-of-the-art benchmarks, effectively bridging the gap between raw pixels and scalable software engineering.
Modular Layout Synthesis (MLS): Front-end Code via Structure Normalization and Constrained Generation
Dec 22, 2025Automated front-end engineering drastically reduces development cycles and minimizes manual coding overhead. While Generative AI has shown promise in translating designs to code, current solutions often produce monolithic scripts, failing to natively support modern ecosystems like React, Vue, or Angular. Furthermore, the generated code frequently suffers from poor modularity, making it difficult to maintain. To bridge this gap, we introduce Modular Layout Synthesis (MLS), a hierarchical framework that merges visual understanding with structural normalization. Initially, a visual-semantic encoder maps the screen capture into a serialized tree topology, capturing the essential layout hierarchy. Instead of simple parsing, we apply heuristic deduplication and pattern recognition to isolate reusable blocks, creating a framework-agnostic schema. Finally, a constraint-based generation protocol guides the LLM to synthesize production-ready code with strict typing and component props. Evaluations show that MLS significantly outperforms existing baselines, ensuring superior code reusability and structural integrity across multiple frameworks
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025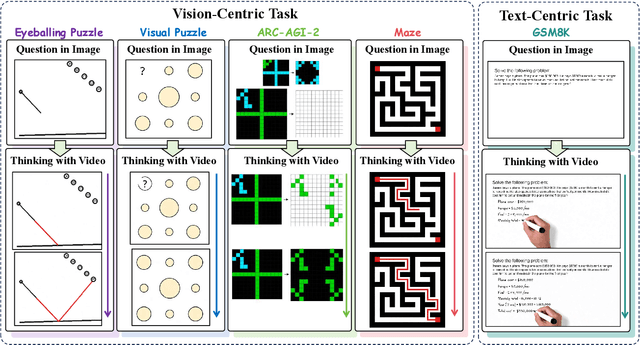
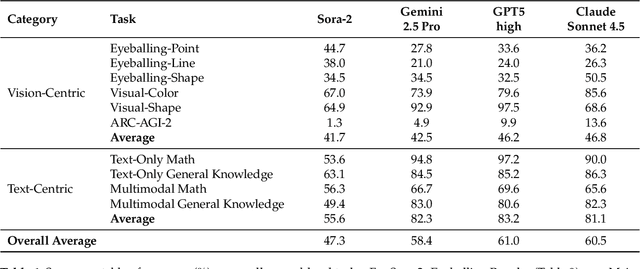
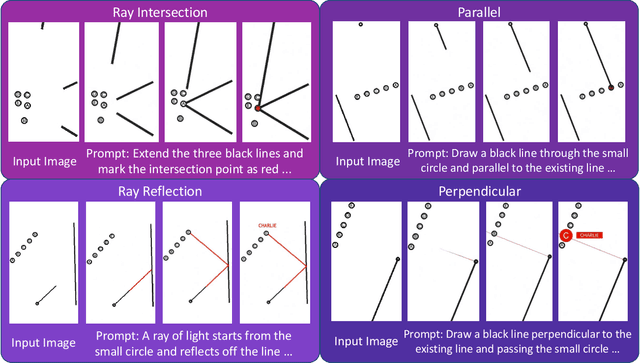

"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.
A Survey on Efficient Large Language Model Training: From Data-centric Perspectives
Oct 29, 2025Post-training of Large Language Models (LLMs) is crucial for unlocking their task generalization potential and domain-specific capabilities. However, the current LLM post-training paradigm faces significant data challenges, including the high costs of manual annotation and diminishing marginal returns on data scales. Therefore, achieving data-efficient post-training has become a key research question. In this paper, we present the first systematic survey of data-efficient LLM post-training from a data-centric perspective. We propose a taxonomy of data-efficient LLM post-training methods, covering data selection, data quality enhancement, synthetic data generation, data distillation and compression, and self-evolving data ecosystems. We summarize representative approaches in each category and outline future research directions. By examining the challenges in data-efficient LLM post-training, we highlight open problems and propose potential research avenues. We hope our work inspires further exploration into maximizing the potential of data utilization in large-scale model training. Paper List: https://github.com/luo-junyu/Awesome-Data-Efficient-LLM
Automated Genomic Interpretation via Concept Bottleneck Models for Medical Robotics
Oct 02, 2025We propose an automated genomic interpretation module that transforms raw DNA sequences into actionable, interpretable decisions suitable for integration into medical automation and robotic systems. Our framework combines Chaos Game Representation (CGR) with a Concept Bottleneck Model (CBM), enforcing predictions to flow through biologically meaningful concepts such as GC content, CpG density, and k mer motifs. To enhance reliability, we incorporate concept fidelity supervision, prior consistency alignment, KL distribution matching, and uncertainty calibration. Beyond accurate classification of HIV subtypes across both in-house and LANL datasets, our module delivers interpretable evidence that can be directly validated against biological priors. A cost aware recommendation layer further translates predictive outputs into decision policies that balance accuracy, calibration, and clinical utility, reducing unnecessary retests and improving efficiency. Extensive experiments demonstrate that the proposed system achieves state of the art classification performance, superior concept prediction fidelity, and more favorable cost benefit trade-offs compared to existing baselines. By bridging the gap between interpretable genomic modeling and automated decision-making, this work establishes a reliable foundation for robotic and clinical automation in genomic medicine.