 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Layout Synthesis (MLS): Front-end Code via Structure Normalization and Constrained Generation
Dec 22, 2025Automated front-end engineering drastically reduces development cycles and minimizes manual coding overhead. While Generative AI has shown promise in translating designs to code, current solutions often produce monolithic scripts, failing to natively support modern ecosystems like React, Vue, or Angular. Furthermore, the generated code frequently suffers from poor modularity, making it difficult to maintain. To bridge this gap, we introduce Modular Layout Synthesis (MLS), a hierarchical framework that merges visual understanding with structural normalization. Initially, a visual-semantic encoder maps the screen capture into a serialized tree topology, capturing the essential layout hierarchy. Instead of simple parsing, we apply heuristic deduplication and pattern recognition to isolate reusable blocks, creating a framework-agnostic schema. Finally, a constraint-based generation protocol guides the LLM to synthesize production-ready code with strict typing and component props. Evaluations show that MLS significantly outperforms existing baselines, ensuring superior code reusability and structural integrity across multiple frameworks
xMTF: A Formula-Free Model for Reinforcement-Learning-Based Multi-Task Fusion in Recommender Systems
Apr 08, 2025



Recommender systems need to optimize various types of user feedback, e.g., clicks, likes, and shares. A typical recommender system handling multiple types of feedback has two components: a multi-task learning (MTL) module, predicting feedback such as click-through rate and like rate; and a multi-task fusion (MTF) module, integrating these predictions into a single score for item ranking. MTF is essential for ensuring user satisfaction, as it directly influences recommendation outcomes. Recently, reinforcement learning (RL) has been applied to MTF tasks to improve long-term user satisfaction. However, existing RL-based MTF methods are formula-based methods, which only adjust limited coefficients within pre-defined formulas. The pre-defined formulas restrict the RL search space and become a bottleneck for MTF. To overcome this, we propose a formula-free MTF framework. We demonstrate that any suitable fusion function can be expressed as a composition of single-variable monotonic functions, as per the Sprecher Representation Theorem. Leveraging this, we introduce a novel learnable monotonic fusion cell (MFC) to replace pre-defined formulas. We call this new MFC-based model eXtreme MTF (xMTF). Furthermore, we employ a two-stage hybrid (TSH) learning strategy to train xMTF effectively. By expanding the MTF search space, xMTF outperforms existing methods in extensive offline and online experiments.
Creator-Side Recommender System: Challenges, Designs, and Applications
Feb 25, 2025Users and creators are two crucial components of recommender systems. Typical recommender systems focus on the user side, providing the most suitable items based on each user's request. In such scenarios, a few items receive a majority of exposures, while many items receive very few. This imbalance leads to poorer experiences and decreased activity among the creators receiving less feedback, harming the recommender system in the long term. To this end, we develop a creator-side recommender system, called DualRec, to answer the following question: how to find the most suitable users for each item to enhance the creators' experience? We show that typical user-side recommendation algorithms, such as retrieval and ranking algorithms, can be adapted into the creator-side versions with just a few modifications. This greatly simplifies algorithm design in DualRec. Moreover, we discuss a unique challenge in DualRec: the user availability issue, which is not present in user-side recommender systems. To tackle this issue, we incorporate a user availability calculation (UAC) module to effectively enhance DualRec's performance. DualRec has already been implemented in Kwai, a short video recommendation system with over 100 millions user and over 10 million creators, significantly improving the experience for creators.
Cache-Aware Reinforcement Learning in Large-Scale Recommender Systems
Apr 23, 2024Modern large-scale recommender systems are built upon computation-intensive infrastructure and usually suffer from a huge difference in traffic between peak and off-peak periods. In peak periods, it is challenging to perform real-time computation for each request due to the limited budget of computational resources. The recommendation with a cache is a solution to this problem, where a user-wise result cache is used to provide recommendations when the recommender system cannot afford a real-time computation. However, the cached recommendations are usually suboptimal compared to real-time computation, and it is challenging to determine the items in the cache for each user. In this paper, we provide a cache-aware reinforcement learning (CARL) method to jointly optimize the recommendation by real-time computation and by the cache. We formulate the problem as a Markov decision process with user states and a cache state, where the cache state represents whether the recommender system performs recommendations by real-time computation or by the cache. The computational load of the recommender system determines the cache state. We perform reinforcement learning based on such a model to improve user engagement over multiple requests. Moreover, we show that the cache will introduce a challenge called critic dependency, which deteriorates the performance of reinforcement learning. To tackle this challenge, we propose an eigenfunction learning (EL) method to learn independent critics for CARL. Experiments show that CARL can significantly improve the users' engagement when considering the result cache. CARL has been fully launched in Kwai app, serving over 100 million users.
CREAD: A Classification-Restoration Framework with Error Adaptive Discretization for Watch Time Prediction in Video Recommender Systems
Jan 15, 2024The watch time is a significant indicator of user satisfaction in video recommender systems. However, the prediction of watch time as a target variable is often hindered by its highly imbalanced distribution with a scarcity of observations for larger target values and over-populated samples for small values. State-of-the-art watch time prediction models discretize the continuous watch time into a set of buckets in order to consider the distribution of watch time. However, it is highly uninvestigated how these discrete buckets should be created from the continuous watch time distribution, and existing discretization approaches suffer from either a large learning error or a large restoration error. To address this challenge, we propose a Classification-Restoration framework with Error-Adaptive-Discretization (CREAD) to accurately predict the watch time. The proposed framework contains a discretization module, a classification module, and a restoration module. It predicts the watch time through multiple classification problems. The discretization process is a key contribution of the CREAD framework. We theoretically analyze the impacts of the discretization on the learning error and the restoration error, and then propose the error-adaptive discretization (EAD) technique to better balance the two errors, which achieves better performance over traditional discretization approaches. We conduct detailed offline evaluations on a public dataset and an industrial dataset, both showing performance gains through the proposed approach. Moreover, We have fully launched our framework to Kwai App, an online video platform, which resulted in a significant increase in users' video watch time by 0.29% through A/B testing. These results highlight the effectiveness of the CREAD framework in watch time prediction in video recommender systems.
UNEX-RL: Reinforcing Long-Term Rewards in Multi-Stage Recommender Systems with UNidirectional EXecution
Jan 12, 2024In recent years, there has been a growing interest in utilizing reinforcement learning (RL) to optimize long-term rewards in recommender systems. Since industrial recommender systems are typically designed as multi-stage systems, RL methods with a single agent face challenges when optimizing multiple stages simultaneously. The reason is that different stages have different observation spaces, and thus cannot be modeled by a single agent. To address this issue, we propose a novel UNidirectional-EXecution-based multi-agent Reinforcement Learning (UNEX-RL) framework to reinforce the long-term rewards in multi-stage recommender systems. We show that the unidirectional execution is a key feature of multi-stage recommender systems, bringing new challenges to the applications of multi-agent reinforcement learning (MARL), namely the observation dependency and the cascading effect. To tackle these challenges, we provide a cascading information chain (CIC) method to separate the independent observations from action-dependent observations and use CIC to train UNEX-RL effectively. We also discuss practical variance reduction techniques for UNEX-RL. Finally, we show the effectiveness of UNEX-RL on both public datasets and an online recommender system with over 100 million users. Specifically, UNEX-RL reveals a 0.558% increase in users' usage time compared with single-agent RL algorithms in online A/B experiments, highlighting the effectiveness of UNEX-RL in industrial recommender systems.
Combining Past, Present and Future: A Self-Supervised Approach for Class Incremental Learning
Nov 15, 2023Class Incremental Learning (CIL) aims to handle the scenario where data of novel classes occur continuously and sequentially. The model should recognize the sequential novel classes while alleviating the catastrophic forgetting. In the self-supervised manner, it becomes more challenging to avoid the conflict between the feature embedding spaces of novel classes and old ones without any class labels. To address the problem, we propose a self-supervised CIL framework CPPF, meaning Combining Past, Present and Future. In detail, CPPF consists of a prototype clustering module (PC), an embedding space reserving module (ESR) and a multi-teacher distillation module (MTD). 1) The PC and the ESR modules reserve embedding space for subsequent phases at the prototype level and the feature level respectively to prepare for knowledge learned in the future. 2) The MTD module maintains the representations of the current phase without the interference of past knowledge. One of the teacher networks retains the representations of the past phases, and the other teacher network distills relation information of the current phase to the student network. Extensive experiments on CIFAR100 and ImageNet100 datasets demonstrate that our proposed method boosts the performance of self-supervised class incremental learning. We will release code in the near future.
Reinforcing Local Feature Representation for Weakly-Supervised Dense Crowd Counting
Feb 22, 2022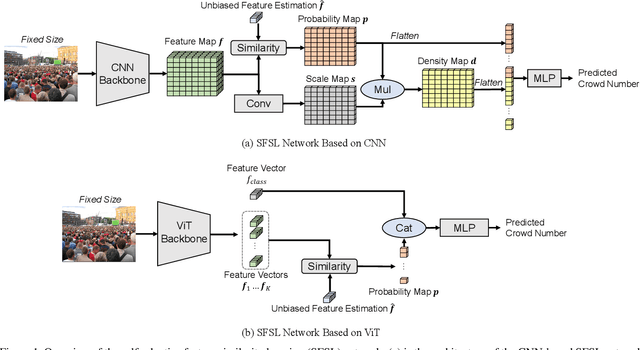

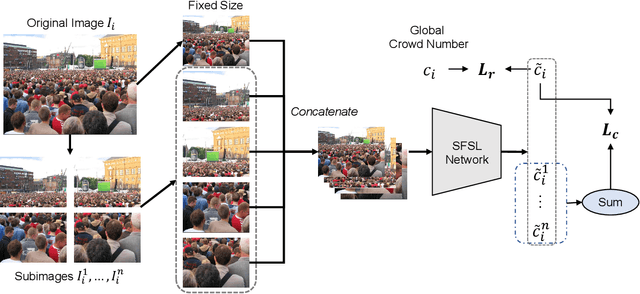

Fully-supervised crowd counting is a laborious task due to the large amounts of annotations. Few works focus on weekly-supervised crowd counting, where only the global crowd numbers are available for training. The main challenge of weekly-supervised crowd counting is the lack of local supervision information. To address this problem, we propose a self-adaptive feature similarity learning (SFSL) network and a global-local consistency (GLC) loss to reinforce local feature representation. We introduce a feature vector which represents the unbiased feature estimation of persons. The network updates the feature vector self-adaptively and utilizes the feature similarity for the regression of crowd numbers. Besides, the proposed GLC loss leverages the consistency between the network estimations from global and local areas. The experimental results demonstrate that our proposed method based on different backbones narrows the gap between weakly-supervised and fully-supervised dense crowd counting.
PANet: Perspective-Aware Network with Dynamic Receptive Fields and Self-Distilling Supervision for Crowd Counting
Oct 31, 2021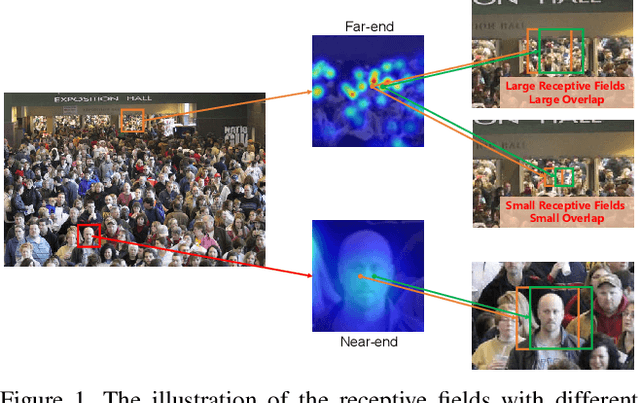
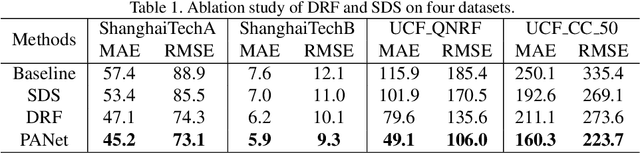
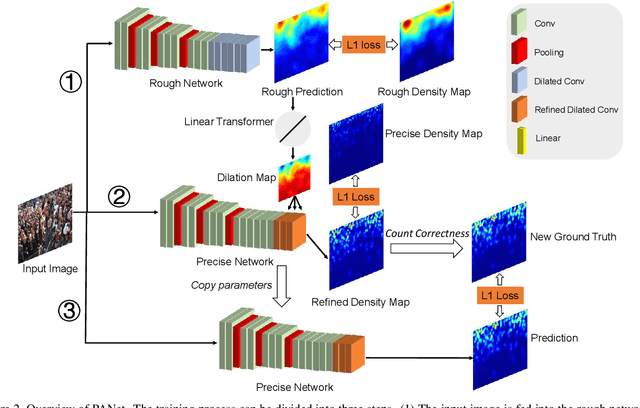

Crowd counting aims to learn the crowd density distributions and estimate the number of objects (e.g. persons) in images. The perspective effect, which significantly influences the distribution of data points, plays an important role in crowd counting. In this paper, we propose a novel perspective-aware approach called PANet to address the perspective problem. Based on the observation that the size of the objects varies greatly in one image due to the perspective effect, we propose the dynamic receptive fields (DRF) framework. The framework is able to adjust the receptive field by the dilated convolution parameters according to the input image, which helps the model to extract more discriminative features for each local region. Different from most previous works which use Gaussian kernels to generate the density map as the supervised information, we propose the self-distilling supervision (SDS) training method. The ground-truth density maps are refined from the first training stage and the perspective information is distilled to the model in the second stage. The experimental results on ShanghaiTech Part_A and Part_B, UCF_QNRF, and UCF_CC_50 datasets demonstrate that our proposed PANet outperforms the state-of-the-art methods by a large margin.
Semi-supervised Learning with Contrastive Predicative Coding
May 25, 2019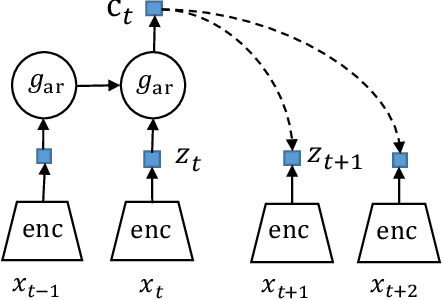

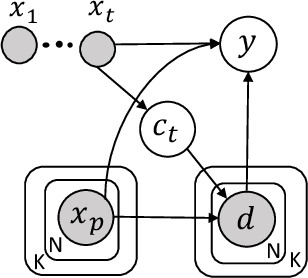
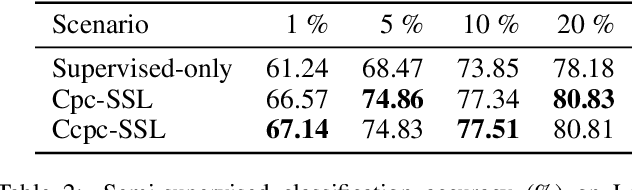
Semi-supervised learning (SSL) provides a powerful framework for leveraging unlabeled data when labels are limited or expensive to obtain. SSL algorithms based on deep neural networks have recently proven successful on standard benchmark tasks. However, many of them have thus far been either inflexible, inefficient or non-scalable. This paper explores recently developed contrastive predictive coding technique to improve discriminative power of deep learning models when a large portion of labels are absent. Two models, cpc-SSL and a class conditional variant~(ccpc-SSL) are presented. They effectively exploit the unlabeled data by extracting shared information between different parts of the (high-dimensional) data. The proposed approaches are inductive, and scale well to very large datasets like ImageNet, making them good candidates in real-world large scale applications.