 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHE-TKG: Collaborative Historical Evidence and Evolutionary Dynamics Learning for Temporal Knowledge Graph Reasoning
May 06, 2026Temporal knowledge graph (TKG) reasoning aims to predict future events from historical facts. A key challenge lies in jointly capturing two sources of predictive information in TKGs: historical evidence and evolutionary dynamics. However, existing methods typically focus on only one of these sources, which limits the ability to fully exploit the complementary predictive signals in TKGs. To address this, we propose CHE-TKG, a novel collaborative dual-view learning framework for TKG reasoning. CHE-TKG explicitly separates and jointly models historical evidence and evolutionary dynamics, aiming to learn and exploit their complementary predictive signals. Specifically, CHE-TKG constructs a historical evidence graph to capture long-term structural regularities and stable relational constraints, alongside an evolutionary dynamics graph to model temporal transitions and recent changes, with dedicated encoders for each view. We further employ relation decomposition and a contrastive alignment objective to better capture the predictive signals across the two views. Extensive experiments demonstrate that CHE-TKG achieves state-of-the-art performance on multiple benchmarks.
VSA:Visual-Structural Alignment for UI-to-Code
Dec 23, 2025


The automation of user interface development has the potential to accelerate software delivery by mitigating intensive manual implementation. Despite the advancements in Large Multimodal Models for design-to-code translation, existing methodologies predominantly yield unstructured, flat codebases that lack compatibility with component-oriented libraries such as React or Angular. Such outputs typically exhibit low cohesion and high coupling, complicating long-term maintenance. In this paper, we propose \textbf{VSA (VSA)}, a multi-stage paradigm designed to synthesize organized frontend assets through visual-structural alignment. Our approach first employs a spatial-aware transformer to reconstruct the visual input into a hierarchical tree representation. Moving beyond basic layout extraction, we integrate an algorithmic pattern-matching layer to identify recurring UI motifs and encapsulate them into modular templates. These templates are then processed via a schema-driven synthesis engine, ensuring the Large Language Model generates type-safe, prop-drilled components suitable for production environments. Experimental results indicate that our framework yields a substantial improvement in code modularity and architectural consistency over state-of-the-art benchmarks, effectively bridging the gap between raw pixels and scalable software engineering.
FFAM: Feature Factorization Activation Map for Explanation of 3D Detectors
May 21, 2024LiDAR-based 3D object detection has made impressive progress recently, yet most existing models are black-box, lacking interpretability. Previous explanation approaches primarily focus on analyzing image-based models and are not readily applicable to LiDAR-based 3D detectors. In this paper, we propose a feature factorization activation map (FFAM) to generate high-quality visual explanations for 3D detectors. FFAM employs non-negative matrix factorization to generate concept activation maps and subsequently aggregates these maps to obtain a global visual explanation. To achieve object-specific visual explanations, we refine the global visual explanation using the feature gradient of a target object. Additionally, we introduce a voxel upsampling strategy to align the scale between the activation map and input point cloud. We qualitatively and quantitatively analyze FFAM with multiple detectors on several datasets. Experimental results validate the high-quality visual explanations produced by FFAM. The Code will be available at \url{https://github.com/Say2L/FFAM.git}.
Transformer-based Reasoning for Learning Evolutionary Chain of Events on Temporal Knowledge Graph
May 01, 2024Temporal Knowledge Graph (TKG) reasoning often involves completing missing factual elements along the timeline. Although existing methods can learn good embeddings for each factual element in quadruples by integrating temporal information, they often fail to infer the evolution of temporal facts. This is mainly because of (1) insufficiently exploring the internal structure and semantic relationships within individual quadruples and (2) inadequately learning a unified representation of the contextual and temporal correlations among different quadruples. To overcome these limitations, we propose a novel Transformer-based reasoning model (dubbed ECEformer) for TKG to learn the Evolutionary Chain of Events (ECE). Specifically, we unfold the neighborhood subgraph of an entity node in chronological order, forming an evolutionary chain of events as the input for our model. Subsequently, we utilize a Transformer encoder to learn the embeddings of intra-quadruples for ECE. We then craft a mixed-context reasoning module based on the multi-layer perceptron (MLP) to learn the unified representations of inter-quadruples for ECE while accomplishing temporal knowledge reasoning. In addition, to enhance the timeliness of the events, we devise an additional time prediction task to complete effective temporal information within the learned unified representation. Extensive experiments on six benchmark datasets verify the state-of-the-art performance and the effectiveness of our method.
Arbitrary Time Information Modeling via Polynomial Approximation for Temporal Knowledge Graph Embedding
May 01, 2024



Distinguished from traditional knowledge graphs (KGs), temporal knowledge graphs (TKGs) must explore and reason over temporally evolving facts adequately. However, existing TKG approaches still face two main challenges, i.e., the limited capability to model arbitrary timestamps continuously and the lack of rich inference patterns under temporal constraints. In this paper, we propose an innovative TKGE method (PTBox) via polynomial decomposition-based temporal representation and box embedding-based entity representation to tackle the above-mentioned problems. Specifically, we decompose time information by polynomials and then enhance the model's capability to represent arbitrary timestamps flexibly by incorporating the learnable temporal basis tensor. In addition, we model every entity as a hyperrectangle box and define each relation as a transformation on the head and tail entity boxes. The entity boxes can capture complex geometric structures and learn robust representations, improving the model's inductive capability for rich inference patterns. Theoretically, our PTBox can encode arbitrary time information or even unseen timestamps while capturing rich inference patterns and higher-arity relations of the knowledge base. Extensive experiments on real-world datasets demonstrate the effectiveness of our method.
DCDet: Dynamic Cross-based 3D Object Detector
Jan 14, 2024



Recently, significant progress has been made in the research of 3D object detection. However, most prior studies have focused on the utilization of center-based or anchor-based label assignment schemes. Alternative label assignment strategies remain unexplored in 3D object detection. We find that the center-based label assignment often fails to generate sufficient positive samples for training, while the anchor-based label assignment tends to encounter an imbalanced issue when handling objects of varying scales. To solve these issues, we introduce a dynamic cross label assignment (DCLA) scheme, which dynamically assigns positive samples for each object from a cross-shaped region, thus providing sufficient and balanced positive samples for training. Furthermore, to address the challenge of accurately regressing objects with varying scales, we put forth a rotation-weighted Intersection over Union (RWIoU) metric to replace the widely used L1 metric in regression loss. Extensive experiments demonstrate the generality and effectiveness of our DCLA and RWIoU-based regression loss. The Code will be available at https://github.com/Say2L/DCDet.git.
Learning Aligned Cross-Modal Representation for Generalized Zero-Shot Classification
Dec 24, 2021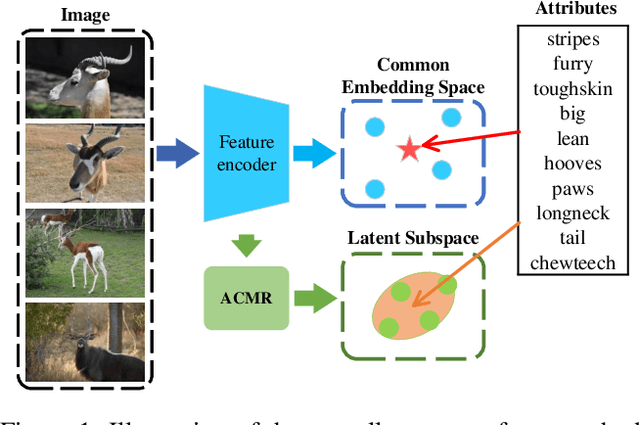
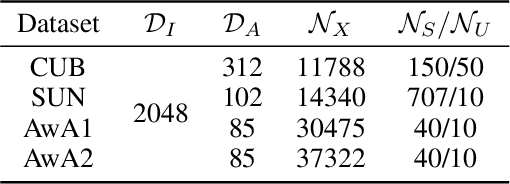
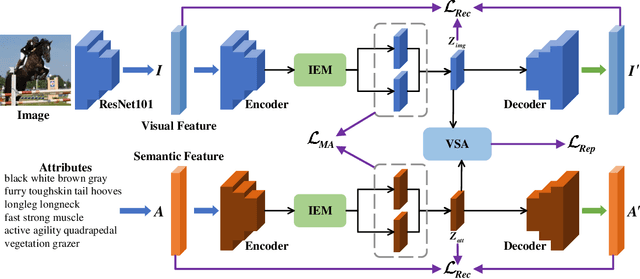
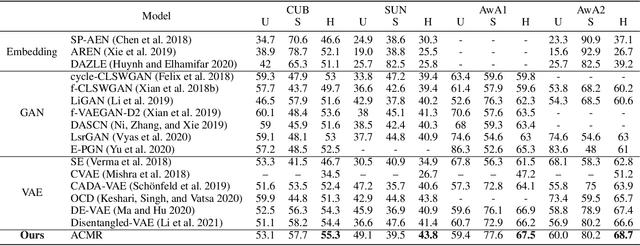
Learning a common latent embedding by aligning the latent spaces of cross-modal autoencoders is an effective strategy for Generalized Zero-Shot Classification (GZSC). However, due to the lack of fine-grained instance-wise annotations, it still easily suffer from the domain shift problem for the discrepancy between the visual representation of diversified images and the semantic representation of fixed attributes. In this paper, we propose an innovative autoencoder network by learning Aligned Cross-Modal Representations (dubbed ACMR) for GZSC. Specifically, we propose a novel Vision-Semantic Alignment (VSA) method to strengthen the alignment of cross-modal latent features on the latent subspaces guided by a learned classifier. In addition, we propose a novel Information Enhancement Module (IEM) to reduce the possibility of latent variables collapse meanwhile encouraging the discriminative ability of latent variables. Extensive experiments on publicly available datasets demonstrate the state-of-the-art performance of our method.