 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOxygenREC: An Instruction-Following Generative Framework for E-commerce Recommendation
Dec 31, 2025Traditional recommendation systems suffer from inconsistency in multi-stage optimization objectives. Generative Recommendation (GR) mitigates them through an end-to-end framework; however, existing methods still rely on matching mechanisms based on inductive patterns. Although responsive, they lack the ability to uncover complex user intents that require deductive reasoning based on world knowledge. Meanwhile, LLMs show strong deep reasoning capabilities, but their latency and computational costs remain challenging for industrial applications. More critically, there are performance bottlenecks in multi-scenario scalability: as shown in Figure 1, existing solutions require independent training and deployment for each scenario, leading to low resource utilization and high maintenance costs-a challenge unaddressed in GR literature. To address these, we present OxygenREC, an industrial recommendation system that leverages Fast-Slow Thinking to deliver deep reasoning with strict latency and multi-scenario requirements of real-world environments. First, we adopt a Fast-Slow Thinking architecture. Slow thinking uses a near-line LLM pipeline to synthesize Contextual Reasoning Instructions, while fast thinking employs a high-efficiency encoder-decoder backbone for real-time generation. Second, to ensure reasoning instructions effectively enhance recommendation generation, we introduce a semantic alignment mechanism with Instruction-Guided Retrieval (IGR) to filter intent-relevant historical behaviors and use a Query-to-Item (Q2I) loss for instruction-item consistency. Finally, to resolve multi-scenario scalability, we transform scenario information into controllable instructions, using unified reward mapping and Soft Adaptive Group Clip Policy Optimization (SA-GCPO) to align policies with diverse business objectives, realizing a train-once-deploy-everywhere paradigm.
AutoLUT: LUT-Based Image Super-Resolution with Automatic Sampling and Adaptive Residual Learning
Mar 03, 2025In recent years, the increasing popularity of Hi-DPI screens has driven a rising demand for high-resolution images. However, the limited computational power of edge devices poses a challenge in deploying complex super-resolution neural networks, highlighting the need for efficient methods. While prior works have made significant progress, they have not fully exploited pixel-level information. Moreover, their reliance on fixed sampling patterns limits both accuracy and the ability to capture fine details in low-resolution images. To address these challenges, we introduce two plug-and-play modules designed to capture and leverage pixel information effectively in Look-Up Table (LUT) based super-resolution networks. Our method introduces Automatic Sampling (AutoSample), a flexible LUT sampling approach where sampling weights are automatically learned during training to adapt to pixel variations and expand the receptive field without added inference cost. We also incorporate Adaptive Residual Learning (AdaRL) to enhance inter-layer connections, enabling detailed information flow and improving the network's ability to reconstruct fine details. Our method achieves significant performance improvements on both MuLUT and SPF-LUT while maintaining similar storage sizes. Specifically, for MuLUT, we achieve a PSNR improvement of approximately +0.20 dB improvement on average across five datasets. For SPF-LUT, with more than a 50% reduction in storage space and about a 2/3 reduction in inference time, our method still maintains performance comparable to the original. The code is available at https://github.com/SuperKenVery/AutoLUT.
Parsing-based View-aware Embedding Network for Vehicle Re-Identification
Apr 10, 2020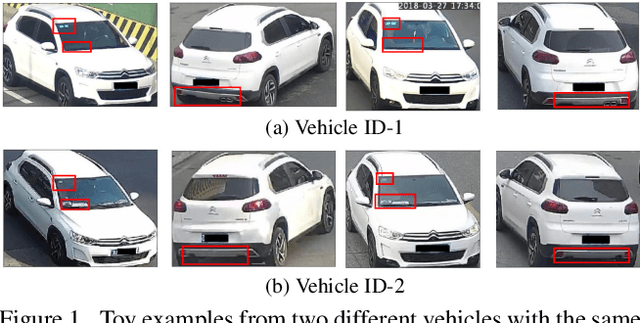
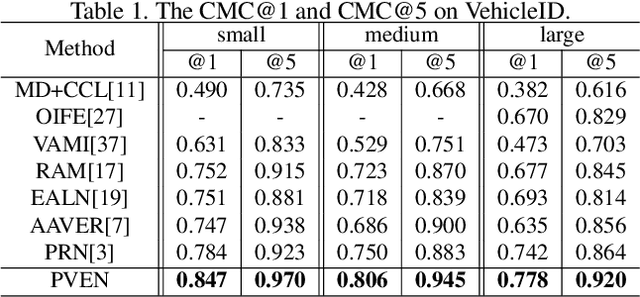
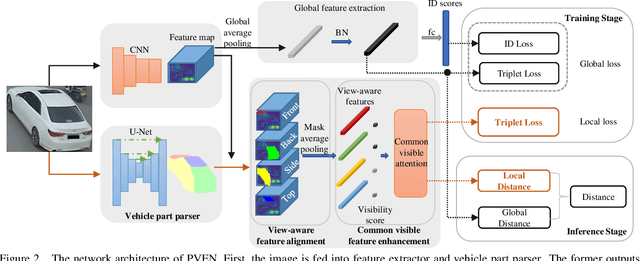
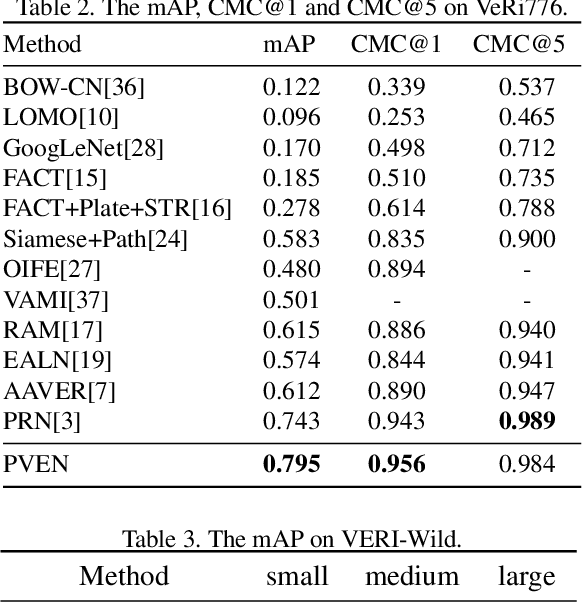
Vehicle Re-Identification is to find images of the same vehicle from various views in the cross-camera scenario. The main challenges of this task are the large intra-instance distance caused by different views and the subtle inter-instance discrepancy caused by similar vehicles. In this paper, we propose a parsing-based view-aware embedding network (PVEN) to achieve the view-aware feature alignment and enhancement for vehicle ReID. First, we introduce a parsing network to parse a vehicle into four different views, and then align the features by mask average pooling. Such alignment provides a fine-grained representation of the vehicle. Second, in order to enhance the view-aware features, we design a common-visible attention to focus on the common visible views, which not only shortens the distance among intra-instances, but also enlarges the discrepancy of inter-instances. The PVEN helps capture the stable discriminative information of vehicle under different views. The experiments conducted on three datasets show that our model outperforms state-of-the-art methods by a large margin.
State-Relabeling Adversarial Active Learning
Apr 10, 2020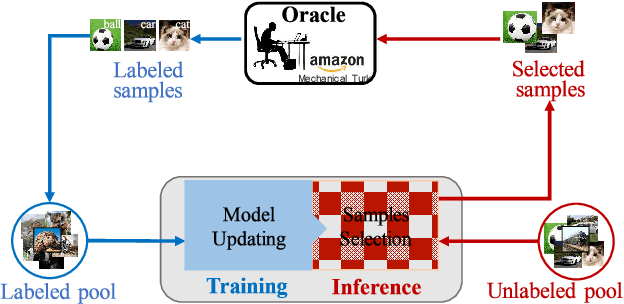
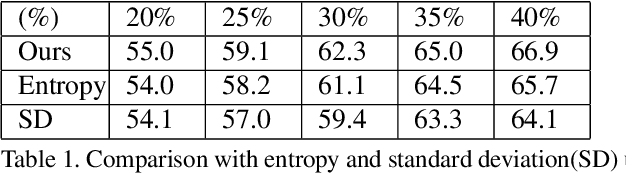
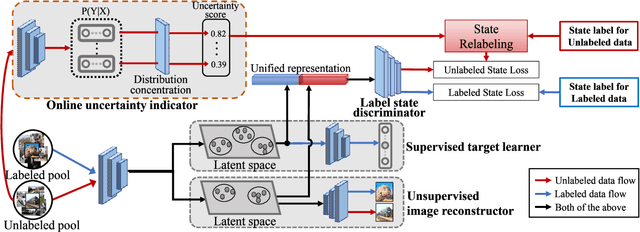
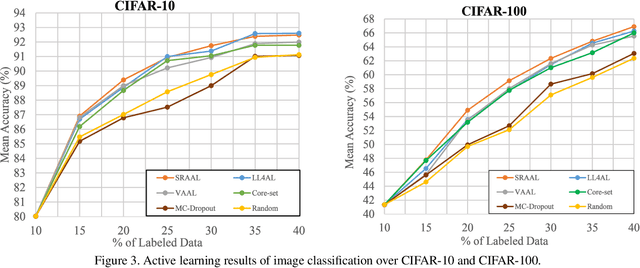
Active learning is to design label-efficient algorithms by sampling the most representative samples to be labeled by an oracle. In this paper, we propose a state relabeling adversarial active learning model (SRAAL), that leverages both the annotation and the labeled/unlabeled state information for deriving the most informative unlabeled samples. The SRAAL consists of a representation generator and a state discriminator. The generator uses the complementary annotation information with traditional reconstruction information to generate the unified representation of samples, which embeds the semantic into the whole data representation. Then, we design an online uncertainty indicator in the discriminator, which endues unlabeled samples with different importance. As a result, we can select the most informative samples based on the discriminator's predicted state. We also design an algorithm to initialize the labeled pool, which makes subsequent sampling more efficient. The experiments conducted on various datasets show that our model outperforms the previous state-of-art active learning methods and our initially sampling algorithm achieves better performance.