 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRAI: Prediction and Generation of High-Impact Academic Research
Jun 03, 2026The rapid pace of scientific publishing has made the identification and synthesis of high-impact work an increasingly urgent challenge. We introduce MIRAI (Multi-year Inference of Research trends and Academic Impact), a deep learning framework that predicts paper impact using only it's title, abstract, and publication date. We train MIRAI on the arXiv academic graph to predict 5-year PageRank and citation counts, achieving Spearman's $ρ$ of 0.4686 on PageRank prediction and 0.6192 on citation prediction for papers published in 2021. We propose a research ideation pipeline built on top of MIRAI that produces research ideas oriented towards high impact. These ideas were judged as more impactful than a baseline without MIRAI by an unbiased LLM judge at a 4:3 ratio. We make the 5-year citation prediction model publicly available at https://predict-paper-impact.vercel.app.
OxygenREC: An Instruction-Following Generative Framework for E-commerce Recommendation
Dec 31, 2025Traditional recommendation systems suffer from inconsistency in multi-stage optimization objectives. Generative Recommendation (GR) mitigates them through an end-to-end framework; however, existing methods still rely on matching mechanisms based on inductive patterns. Although responsive, they lack the ability to uncover complex user intents that require deductive reasoning based on world knowledge. Meanwhile, LLMs show strong deep reasoning capabilities, but their latency and computational costs remain challenging for industrial applications. More critically, there are performance bottlenecks in multi-scenario scalability: as shown in Figure 1, existing solutions require independent training and deployment for each scenario, leading to low resource utilization and high maintenance costs-a challenge unaddressed in GR literature. To address these, we present OxygenREC, an industrial recommendation system that leverages Fast-Slow Thinking to deliver deep reasoning with strict latency and multi-scenario requirements of real-world environments. First, we adopt a Fast-Slow Thinking architecture. Slow thinking uses a near-line LLM pipeline to synthesize Contextual Reasoning Instructions, while fast thinking employs a high-efficiency encoder-decoder backbone for real-time generation. Second, to ensure reasoning instructions effectively enhance recommendation generation, we introduce a semantic alignment mechanism with Instruction-Guided Retrieval (IGR) to filter intent-relevant historical behaviors and use a Query-to-Item (Q2I) loss for instruction-item consistency. Finally, to resolve multi-scenario scalability, we transform scenario information into controllable instructions, using unified reward mapping and Soft Adaptive Group Clip Policy Optimization (SA-GCPO) to align policies with diverse business objectives, realizing a train-once-deploy-everywhere paradigm.
Large Scale Retrieval for the LinkedIn Feed using Causal Language Models
Oct 16, 2025



In large scale recommendation systems like the LinkedIn Feed, the retrieval stage is critical for narrowing hundreds of millions of potential candidates to a manageable subset for ranking. LinkedIn's Feed serves suggested content from outside of the member's network (based on the member's topical interests), where 2000 candidates are retrieved from a pool of hundreds of millions candidate with a latency budget of a few milliseconds and inbound QPS of several thousand per second. This paper presents a novel retrieval approach that fine-tunes a large causal language model (Meta's LLaMA 3) as a dual encoder to generate high quality embeddings for both users (members) and content (items), using only textual input. We describe the end to end pipeline, including prompt design for embedding generation, techniques for fine-tuning at LinkedIn's scale, and infrastructure for low latency, cost effective online serving. We share our findings on how quantizing numerical features in the prompt enables the information to get properly encoded in the embedding, facilitating greater alignment between the retrieval and ranking layer. The system was evaluated using offline metrics and an online A/B test, which showed substantial improvements in member engagement. We observed significant gains among newer members, who often lack strong network connections, indicating that high-quality suggested content aids retention. This work demonstrates how generative language models can be effectively adapted for real time, high throughput retrieval in industrial applications.
TransPOS: Transformers for Consolidating Different POS Tagset Datasets
Sep 24, 2022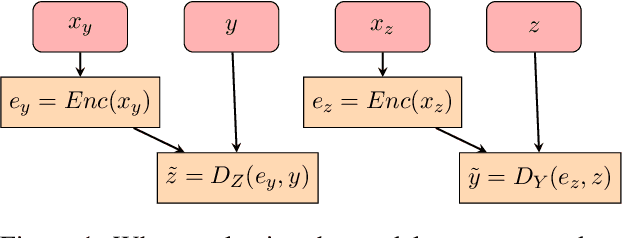
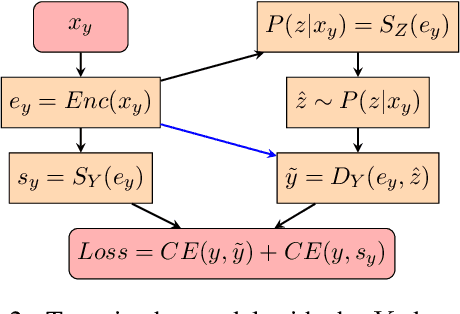
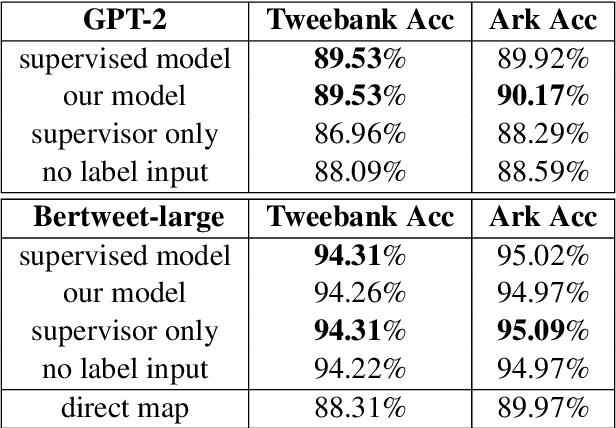
In hope of expanding training data, researchers often want to merge two or more datasets that are created using different labeling schemes. This paper considers two datasets that label part-of-speech (POS) tags under different tagging schemes and leverage the supervised labels of one dataset to help generate labels for the other dataset. This paper further discusses the theoretical difficulties of this approach and proposes a novel supervised architecture employing Transformers to tackle the problem of consolidating two completely disjoint datasets. The results diverge from initial expectations and discourage exploration into the use of disjoint labels to consolidate datasets with different labels.