 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Clues: Bridging Vision and Language Foundations for Image Paragraph Captioning
Jun 03, 2022

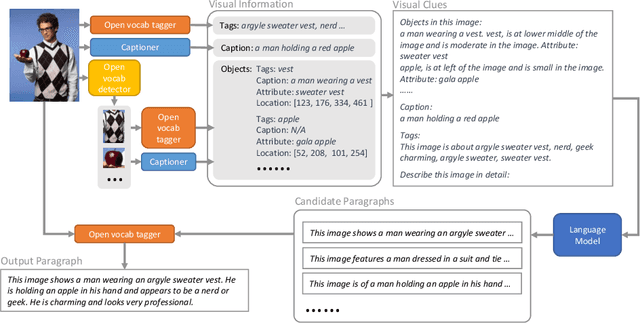
People say, "A picture is worth a thousand words". Then how can we get the rich information out of the image? We argue that by using visual clues to bridge large pretrained vision foundation models and language models, we can do so without any extra cross-modal training. Thanks to the strong zero-shot capability of foundation models, we start by constructing a rich semantic representation of the image (e.g., image tags, object attributes / locations, captions) as a structured textual prompt, called visual clues, using a vision foundation model. Based on visual clues, we use large language model to produce a series of comprehensive descriptions for the visual content, which is then verified by the vision model again to select the candidate that aligns best with the image. We evaluate the quality of generated descriptions by quantitative and qualitative measurement. The results demonstrate the effectiveness of such a structured semantic representation.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 29, 2022
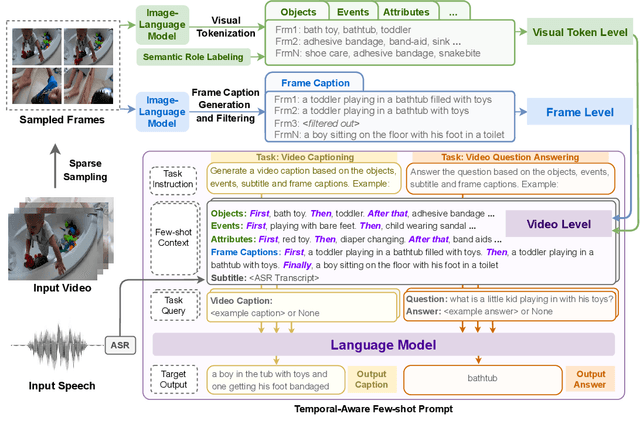
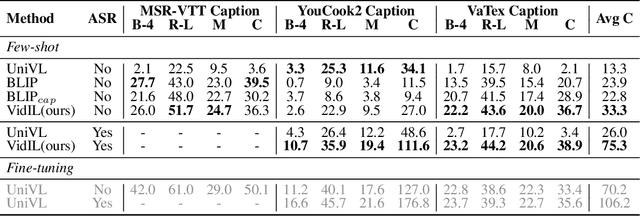

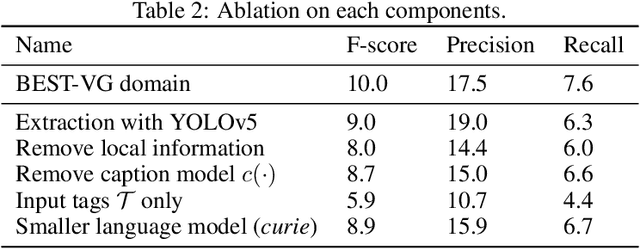
The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .
Multimodal Adaptive Distillation for Leveraging Unimodal Encoders for Vision-Language Tasks
Apr 28, 2022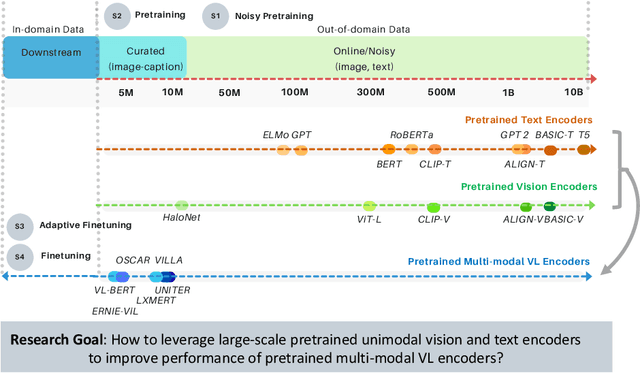
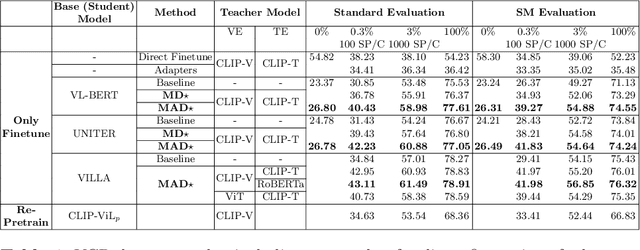
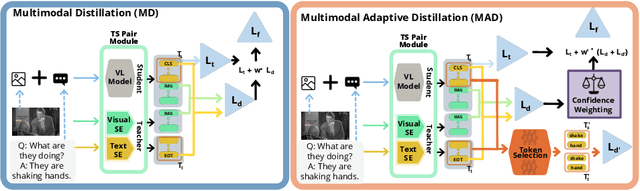
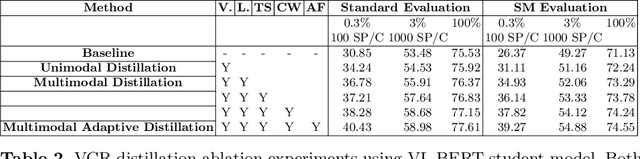
Cross-modal encoders for vision-language (VL) tasks are often pretrained with carefully curated vision-language datasets. While these datasets reach an order of 10 million samples, the labor cost is prohibitive to scale further. Conversely, unimodal encoders are pretrained with simpler annotations that are less cost-prohibitive, achieving scales of hundreds of millions to billions. As a result, unimodal encoders have achieved state-of-art (SOTA) on many downstream tasks. However, challenges remain when applying to VL tasks. The pretraining data is not optimal for cross-modal architectures and requires heavy computational resources. In addition, unimodal architectures lack cross-modal interactions that have demonstrated significant benefits for VL tasks. Therefore, how to best leverage pretrained unimodal encoders for VL tasks is still an area of active research. In this work, we propose a method to leverage unimodal vision and text encoders for VL tasks that augment existing VL approaches while conserving computational complexity. Specifically, we propose Multimodal Adaptive Distillation (MAD), which adaptively distills useful knowledge from pretrained encoders to cross-modal VL encoders. Second, to better capture nuanced impacts on VL task performance, we introduce an evaluation protocol that includes Visual Commonsense Reasoning (VCR), Visual Entailment (SNLI-VE), and Visual Question Answering (VQA), across a variety of data constraints and conditions of domain shift. Experiments demonstrate that MAD leads to consistent gains in the low-shot, domain-shifted, and fully-supervised conditions on VCR, SNLI-VE, and VQA, achieving SOTA performance on VCR compared to other single models pretrained with image-text data. Finally, MAD outperforms concurrent works utilizing pretrained vision encoder from CLIP. Code will be made available.
CLIP-TD: CLIP Targeted Distillation for Vision-Language Tasks
Jan 15, 2022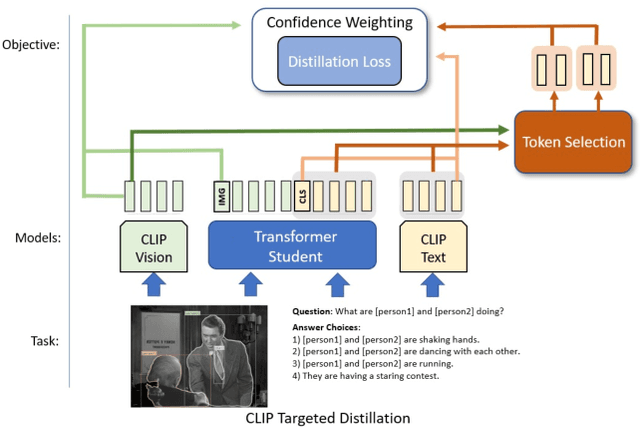
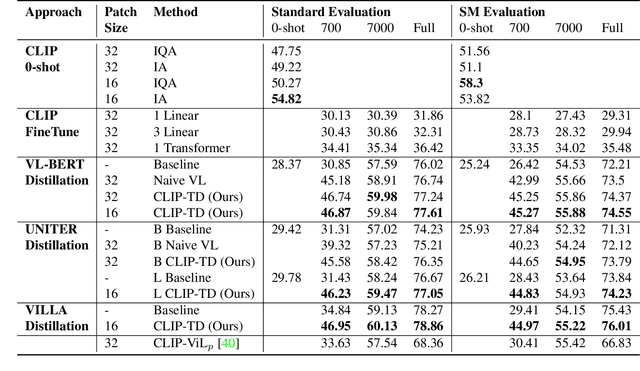
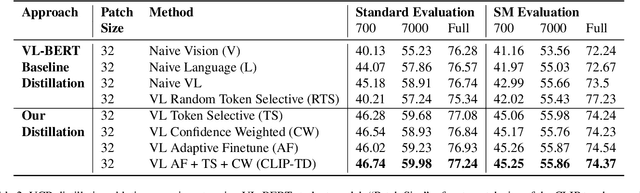

Contrastive language-image pretraining (CLIP) links vision and language modalities into a unified embedding space, yielding the tremendous potential for vision-language (VL) tasks. While early concurrent works have begun to study this potential on a subset of tasks, important questions remain: 1) What is the benefit of CLIP on unstudied VL tasks? 2) Does CLIP provide benefit in low-shot or domain-shifted scenarios? 3) Can CLIP improve existing approaches without impacting inference or pretraining complexity? In this work, we seek to answer these questions through two key contributions. First, we introduce an evaluation protocol that includes Visual Commonsense Reasoning (VCR), Visual Entailment (SNLI-VE), and Visual Question Answering (VQA), across a variety of data availability constraints and conditions of domain shift. Second, we propose an approach, named CLIP Targeted Distillation (CLIP-TD), to intelligently distill knowledge from CLIP into existing architectures using a dynamically weighted objective applied to adaptively selected tokens per instance. Experiments demonstrate that our proposed CLIP-TD leads to exceptional gains in the low-shot (up to 51.9%) and domain-shifted (up to 71.3%) conditions of VCR, while simultaneously improving performance under standard fully-supervised conditions (up to 2%), achieving state-of-art performance on VCR compared to other single models that are pretrained with image-text data only. On SNLI-VE, CLIP-TD produces significant gains in low-shot conditions (up to 6.6%) as well as fully supervised (up to 3%). On VQA, CLIP-TD provides improvement in low-shot (up to 9%), and in fully-supervised (up to 1.3%). Finally, CLIP-TD outperforms concurrent works utilizing CLIP for finetuning, as well as baseline naive distillation approaches. Code will be made available.
CLIP-Event: Connecting Text and Images with Event Structures
Jan 13, 2022
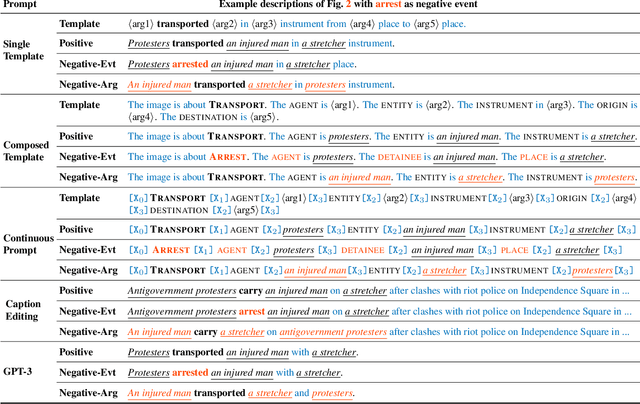
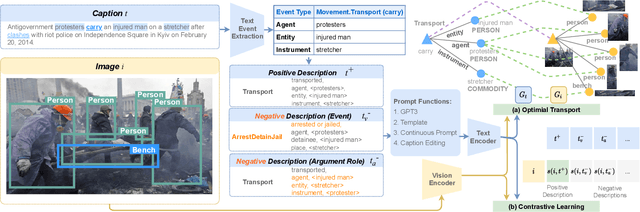

Vision-language (V+L) pretraining models have achieved great success in supporting multimedia applications by understanding the alignments between images and text. While existing vision-language pretraining models primarily focus on understanding objects in images or entities in text, they often ignore the alignment at the level of events and their argument structures. % In this work, we propose a contrastive learning framework to enforce vision-language pretraining models to comprehend events and associated argument (participant) roles. To achieve this, we take advantage of text information extraction technologies to obtain event structural knowledge, and utilize multiple prompt functions to contrast difficult negative descriptions by manipulating event structures. We also design an event graph alignment loss based on optimal transport to capture event argument structures. In addition, we collect a large event-rich dataset (106,875 images) for pretraining, which provides a more challenging image retrieval benchmark to assess the understanding of complicated lengthy sentences. Experiments show that our zero-shot CLIP-Event outperforms the state-of-the-art supervised model in argument extraction on Multimedia Event Extraction, achieving more than 5\% absolute F-score gain in event extraction, as well as significant improvements on a variety of downstream tasks under zero-shot settings.
RegionCLIP: Region-based Language-Image Pretraining
Dec 16, 2021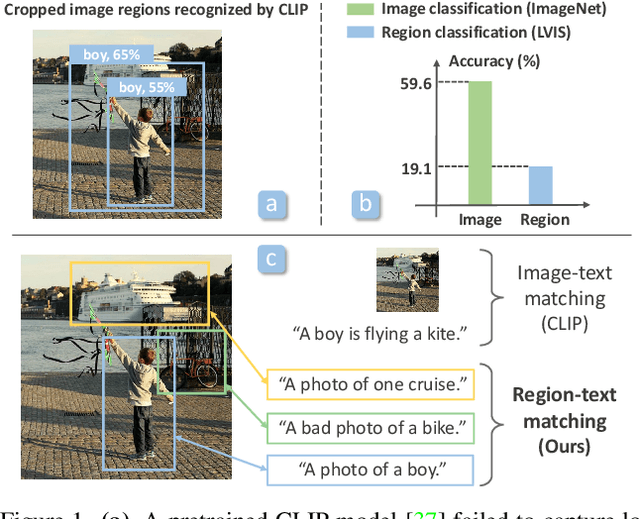
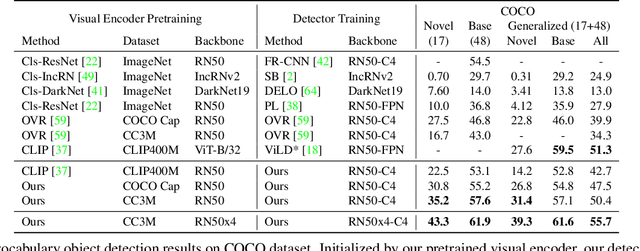
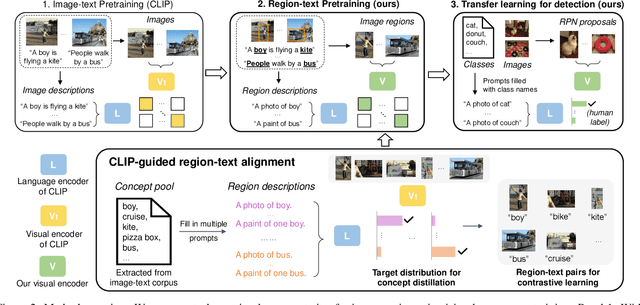
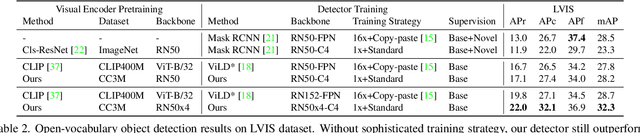
Contrastive language-image pretraining (CLIP) using image-text pairs has achieved impressive results on image classification in both zero-shot and transfer learning settings. However, we show that directly applying such models to recognize image regions for object detection leads to poor performance due to a domain shift: CLIP was trained to match an image as a whole to a text description, without capturing the fine-grained alignment between image regions and text spans. To mitigate this issue, we propose a new method called RegionCLIP that significantly extends CLIP to learn region-level visual representations, thus enabling fine-grained alignment between image regions and textual concepts. Our method leverages a CLIP model to match image regions with template captions and then pretrains our model to align these region-text pairs in the feature space. When transferring our pretrained model to the open-vocabulary object detection tasks, our method significantly outperforms the state of the art by 3.8 AP50 and 2.2 AP for novel categories on COCO and LVIS datasets, respectively. Moreoever, the learned region representations support zero-shot inference for object detection, showing promising results on both COCO and LVIS datasets. Our code is available at https://github.com/microsoft/RegionCLIP.
BEVT: BERT Pretraining of Video Transformers
Dec 02, 2021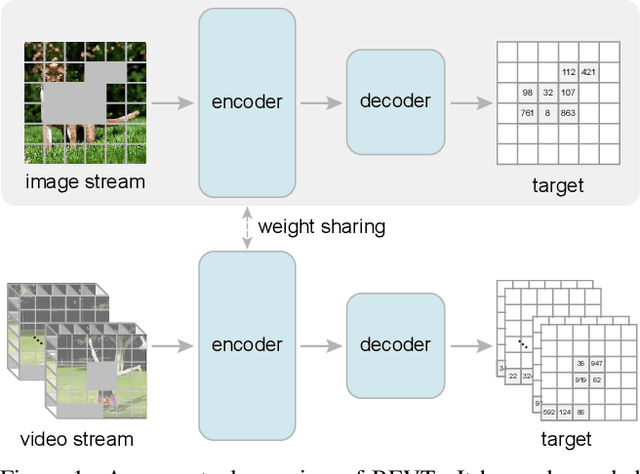
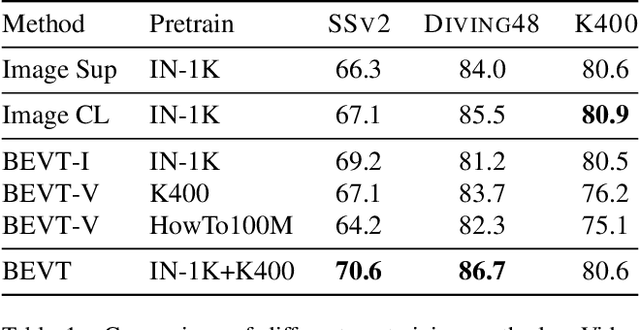
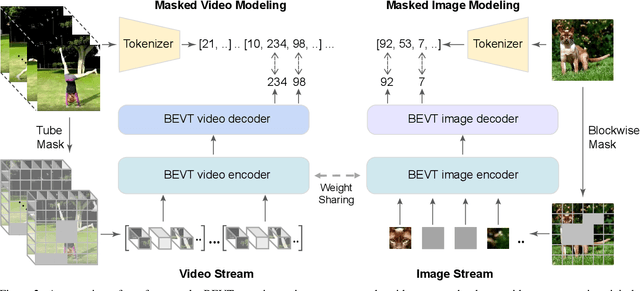

This paper studies the BERT pretraining of video transformers. It is a straightforward but worth-studying extension given the recent success from BERT pretraining of image transformers. We introduce BEVT which decouples video representation learning into spatial representation learning and temporal dynamics learning. In particular, BEVT first performs masked image modeling on image data, and then conducts masked image modeling jointly with masked video modeling on video data. This design is motivated by two observations: 1) transformers learned on image datasets provide decent spatial priors that can ease the learning of video transformers, which are often times computationally-intensive if trained from scratch; 2) discriminative clues, i.e., spatial and temporal information, needed to make correct predictions vary among different videos due to large intra-class and inter-class variations. We conduct extensive experiments on three challenging video benchmarks where BEVT achieves very promising results. On Kinetics 400, for which recognition mostly relies on discriminative spatial representations, BEVT achieves comparable results to strong supervised baselines. On Something-Something-V2 and Diving 48, which contain videos relying on temporal dynamics, BEVT outperforms by clear margins all alternative baselines and achieves state-of-the-art performance with a 70.6% and 86.7% Top-1 accuracy respectively.
Florence: A New Foundation Model for Computer Vision
Nov 22, 2021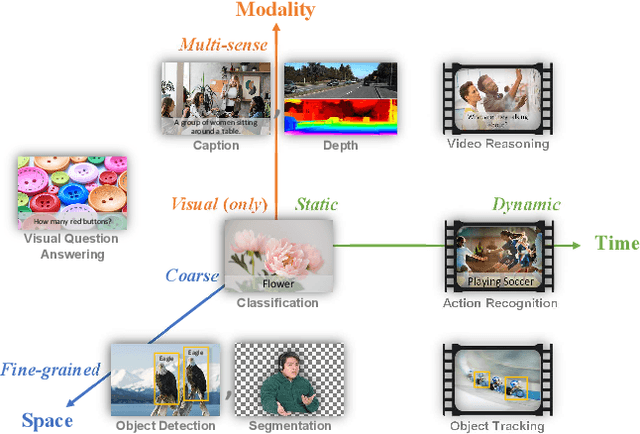
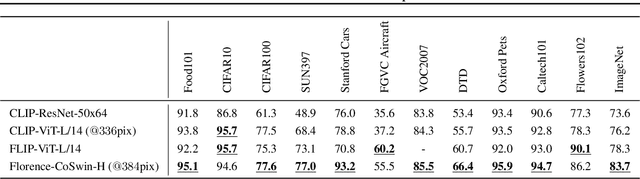
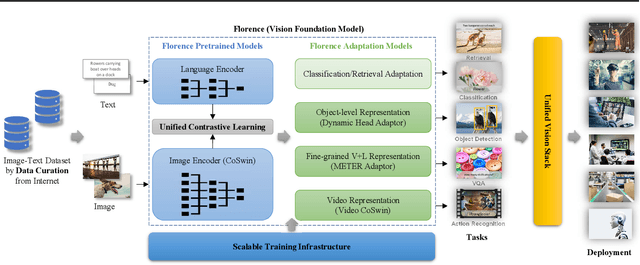
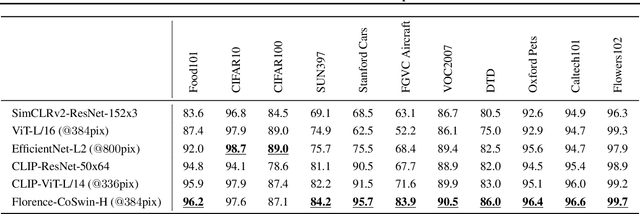
Automated visual understanding of our diverse and open world demands computer vision models to generalize well with minimal customization for specific tasks, similar to human vision. Computer vision foundation models, which are trained on diverse, large-scale dataset and can be adapted to a wide range of downstream tasks, are critical for this mission to solve real-world computer vision applications. While existing vision foundation models such as CLIP, ALIGN, and Wu Dao 2.0 focus mainly on mapping images and textual representations to a cross-modal shared representation, we introduce a new computer vision foundation model, Florence, to expand the representations from coarse (scene) to fine (object), from static (images) to dynamic (videos), and from RGB to multiple modalities (caption, depth). By incorporating universal visual-language representations from Web-scale image-text data, our Florence model can be easily adapted for various computer vision tasks, such as classification, retrieval, object detection, VQA, image caption, video retrieval and action recognition. Moreover, Florence demonstrates outstanding performance in many types of transfer learning: fully sampled fine-tuning, linear probing, few-shot transfer and zero-shot transfer for novel images and objects. All of these properties are critical for our vision foundation model to serve general purpose vision tasks. Florence achieves new state-of-the-art results in majority of 44 representative benchmarks, e.g., ImageNet-1K zero-shot classification with top-1 accuracy of 83.74 and the top-5 accuracy of 97.18, 62.4 mAP on COCO fine tuning, 80.36 on VQA, and 87.8 on Kinetics-600.
VALUE: A Multi-Task Benchmark for Video-and-Language Understanding Evaluation
Jun 08, 2021

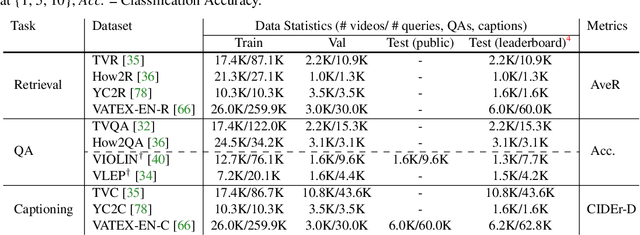
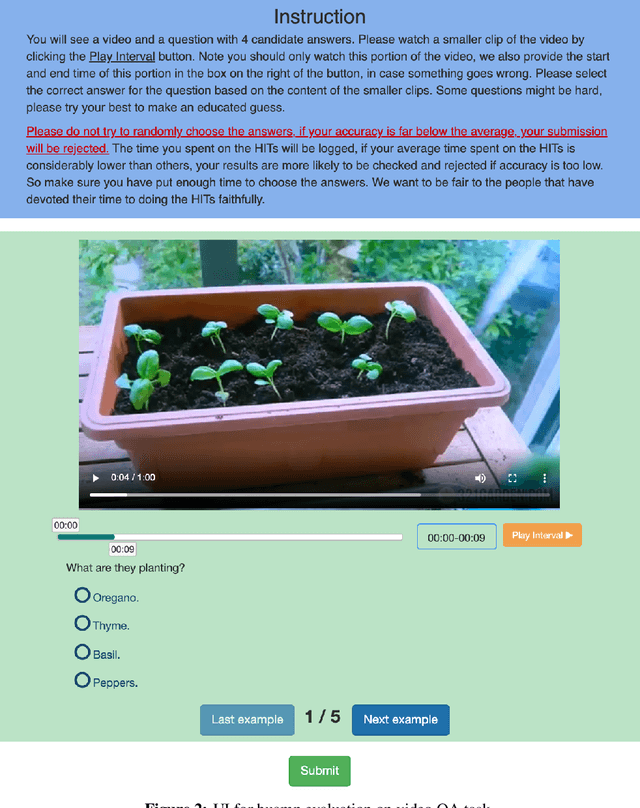
Most existing video-and-language (VidL) research focuses on a single dataset, or multiple datasets of a single task. In reality, a truly useful VidL system is expected to be easily generalizable to diverse tasks, domains, and datasets. To facilitate the evaluation of such systems, we introduce Video-And-Language Understanding Evaluation (VALUE) benchmark, an assemblage of 11 VidL datasets over 3 popular tasks: (i) text-to-video retrieval; (ii) video question answering; and (iii) video captioning. VALUE benchmark aims to cover a broad range of video genres, video lengths, data volumes, and task difficulty levels. Rather than focusing on single-channel videos with visual information only, VALUE promotes models that leverage information from both video frames and their associated subtitles, as well as models that share knowledge across multiple tasks. We evaluate various baseline methods with and without large-scale VidL pre-training, and systematically investigate the impact of video input channels, fusion methods, and different video representations. We also study the transferability between tasks, and conduct multi-task learning under different settings. The significant gap between our best model and human performance calls for future study for advanced VidL models. VALUE is available at https://value-leaderboard.github.io/.
CUPID: Adaptive Curation of Pre-training Data for Video-and-Language Representation Learning
Apr 13, 2021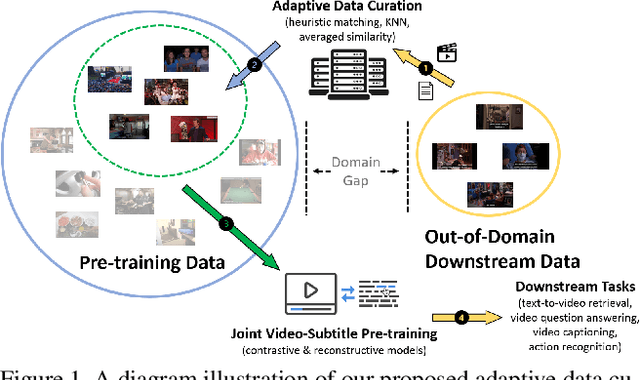

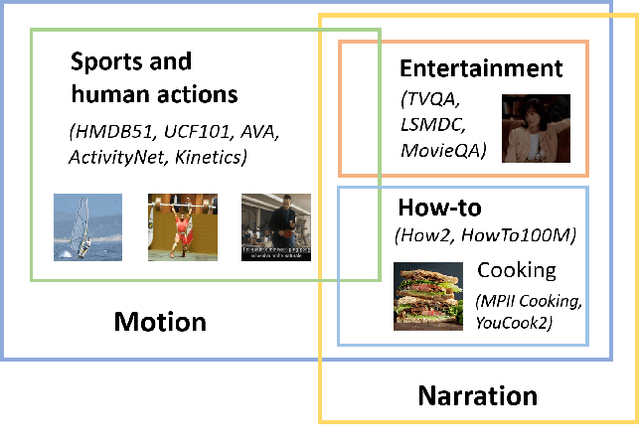
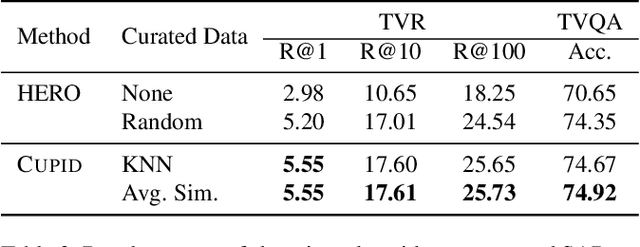
This work concerns video-language pre-training and representation learning. In this now ubiquitous training scheme, a model first performs pre-training on paired videos and text (e.g., video clips and accompanied subtitles) from a large uncurated source corpus, before transferring to specific downstream tasks. This two-stage training process inevitably raises questions about the generalization ability of the pre-trained model, which is particularly pronounced when a salient domain gap exists between source and target data (e.g., instructional cooking videos vs. movies). In this paper, we first bring to light the sensitivity of pre-training objectives (contrastive vs. reconstructive) to domain discrepancy. Then, we propose a simple yet effective framework, CUPID, to bridge this domain gap by filtering and adapting source data to the target data, followed by domain-focused pre-training. Comprehensive experiments demonstrate that pre-training on a considerably small subset of domain-focused data can effectively close the source-target domain gap and achieve significant performance gain, compared to random sampling or even exploiting the full pre-training dataset. CUPID yields new state-of-the-art performance across multiple video-language and video tasks, including text-to-video retrieval [72, 37], video question answering [36], and video captioning [72], with consistent performance lift over different pre-training methods.