 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIFT: A Residual Flow Adapter for Decoding Continuous Outputs in Vision-Language Models
Jun 04, 2026Many modern vision-language models (VLMs) build on autoregressive decoding of discrete tokens. While text-based output interfaces enable scalable pretraining and strong zero-shot generalization across diverse tasks, they are poorly suited for problems that require precise continuous outputs, such as localizing temporal boundaries of events or generating robotic control actions. To address this challenge, we propose DRIFT, a general framework for adapting pretrained VLMs to continuous decoding tasks. DRIFT combines a base predictor, which provides a coarse estimate of the target output, with a generative refinement module based on flow matching that iteratively improves the prediction. This residual formulation transforms the generative modeling problem from learning a global output distribution to modeling a localized residual distribution around a strong prior, substantially simplifying optimization. We evaluate DRIFT on both perception and planning tasks, including visual grounding and robotic control. Across multiple tasks and architectures spanning MLLMs, VLAs, and WAMs, DRIFT consistently outperforms a strong set of regression- and generative-based solutions.
M$^3$Eval: Multi-Modal Memory Evaluation through Cognitively-Grounded Video Tasks
Jun 03, 2026As multi-modal models advance towards long-form video understanding, memory emerges as a critical capability. Despite substantial efforts in developing video datasets and benchmarks, existing works primarily focus on perception and reasoning, without systematically evaluating memory: what models retain, how faithfully information is preserved, and how robust memory remains under interference. To address this gap, we introduce M$^3$Eval, the first comprehensive evaluation framework and benchmark for probing different memory dimensions in multi-modal models. Grounded in cognitive psychology, our design features carefully constructed tasks that isolate key aspects of memory. Leveraging M$^3$Eval, we conduct extensive experiments across representative multi-modal models, revealing consistent weaknesses and distinctive behaviors. We find that models struggle to maintain disentangled representations when processing parallel video streams, exhibit interference patterns differing substantially from those observed in human memory, ground memory sources more reliably in the spatial domain than the temporal domain, and demonstrate limited symbolic memory. Collectively, our benchmark provides a valuable resource for future research, while our findings highlight memory as a fundamental yet underexplored capability and offer insights for designing more effective memory mechanisms in multi-modal models. Our code and dataset are available at https://pku-value-lab.github.io/m3eval-homepage.
DUALVISION: RGB-Infrared Multimodal Large Language Models for Robust Visual Reasoning
Apr 20, 2026Multimodal large language models (MLLMs) have achieved impressive performance on visual perception and reasoning tasks with RGB imagery, yet they remain fragile under common degradations, such as fog, blur, or low-light conditions. Infrared (IR) imaging, a well-established complement to RGB, offers inherent robustness in these conditions, but its integration into MLLMs remains underexplored. To bridge this gap, we propose DUALVISION, a lightweight fusion module that efficiently incorporates IR-RGB information into MLLMs via patch-level localized cross-attention. To support training and evaluation and to facilitate future research, we also introduce DV-204K, a dataset of ~25K publicly available aligned IR-RGB image pairs with 204K modality-specific QA annotations, and DV-500, a benchmark of 500 IR-RGB image pairs with 500 QA pairs designed for evaluating cross-modal reasoning. Leveraging these datasets, we benchmark both open- and closed-source MLLMs and demonstrate that DUALVISION delivers strong empirical performance under a wide range of visual degradations. Our code and dataset are available at https://abrarmajeedi.github.io/dualvision.
ReGLA: Efficient Receptive-Field Modeling with Gated Linear Attention Network
Feb 05, 2026Balancing accuracy and latency on high-resolution images is a critical challenge for lightweight models, particularly for Transformer-based architectures that often suffer from excessive latency. To address this issue, we introduce \textbf{ReGLA}, a series of lightweight hybrid networks, which integrates efficient convolutions for local feature extraction with ReLU-based gated linear attention for global modeling. The design incorporates three key innovations: the Efficient Large Receptive Field (ELRF) module for enhancing convolutional efficiency while preserving a large receptive field; the ReLU Gated Modulated Attention (RGMA) module for maintaining linear complexity while enhancing local feature representation; and a multi-teacher distillation strategy to boost performance on downstream tasks. Extensive experiments validate the superiority of ReGLA; particularly the ReGLA-M achieves \textbf{80.85\%} Top-1 accuracy on ImageNet-1K at $224px$, with only \textbf{4.98 ms} latency at $512px$. Furthermore, ReGLA outperforms similarly scaled iFormer models in downstream tasks, achieving gains of \textbf{3.1\%} AP on COCO object detection and \textbf{3.6\%} mIoU on ADE20K semantic segmentation, establishing it as a state-of-the-art solution for high-resolution visual applications.
Decomposing LLM Self-Correction: The Accuracy-Correction Paradox and Error Depth Hypothesis
Dec 24, 2025Large Language Models (LLMs) are widely believed to possess self-correction capabilities, yet recent studies suggest that intrinsic self-correction--where models correct their own outputs without external feedback--remains largely ineffective. In this work, we systematically decompose self-correction into three distinct sub-capabilities: error detection, error localization, and error correction. Through cross-model experiments on GSM8K-Complex (n=500 per model, 346 total errors) with three major LLMs, we uncover a striking Accuracy-Correction Paradox: weaker models (GPT-3.5, 66% accuracy) achieve 1.6x higher intrinsic correction rates than stronger models (DeepSeek, 94% accuracy)--26.8% vs 16.7%. We propose the Error Depth Hypothesis: stronger models make fewer but deeper errors that resist self-correction. Error detection rates vary dramatically across architectures (10% to 82%), yet detection capability does not predict correction success--Claude detects only 10% of errors but corrects 29% intrinsically. Surprisingly, providing error location hints hurts all models. Our findings challenge linear assumptions about model capability and self-improvement, with important implications for the design of self-refinement pipelines.
Rethinking Chain-of-Thought Reasoning for Videos
Dec 10, 2025Chain-of-thought (CoT) reasoning has been highly successful in solving complex tasks in natural language processing, and recent multimodal large language models (MLLMs) have extended this paradigm to video reasoning. However, these models typically build on lengthy reasoning chains and large numbers of input visual tokens. Motivated by empirical observations from our benchmark study, we hypothesize that concise reasoning combined with a reduced set of visual tokens can be sufficient for effective video reasoning. To evaluate this hypothesis, we design and validate an efficient post-training and inference framework that enhances a video MLLM's reasoning capability. Our framework enables models to operate on compressed visual tokens and generate brief reasoning traces prior to answering. The resulting models achieve substantially improved inference efficiency, deliver competitive performance across diverse benchmarks, and avoid reliance on manual CoT annotations or supervised fine-tuning. Collectively, our results suggest that long, human-like CoT reasoning may not be necessary for general video reasoning, and that concise reasoning can be both effective and efficient. Our code will be released at https://github.com/LaVi-Lab/Rethink_CoT_Video.
A scalable and real-time neural decoder for topological quantum codes
Dec 08, 2025Fault-tolerant quantum computing will require error rates far below those achievable with physical qubits. Quantum error correction (QEC) bridges this gap, but depends on decoders being simultaneously fast, accurate, and scalable. This combination of requirements has not yet been met by a machine-learning decoder, nor by any decoder for promising resource-efficient codes such as the colour code. Here we introduce AlphaQubit 2, a neural-network decoder that achieves near-optimal logical error rates for both surface and colour codes at large scales under realistic noise. For the colour code, it is orders of magnitude faster than other high-accuracy decoders. For the surface code, we demonstrate real-time decoding faster than 1 microsecond per cycle up to distance 11 on current commercial accelerators with better accuracy than leading real-time decoders. These results support the practical application of a wider class of promising QEC codes, and establish a credible path towards high-accuracy, real-time neural decoding at the scales required for fault-tolerant quantum computation.
Visual Bridge: Universal Visual Perception Representations Generating
Nov 11, 2025Recent advances in diffusion models have achieved remarkable success in isolated computer vision tasks such as text-to-image generation, depth estimation, and optical flow. However, these models are often restricted by a ``single-task-single-model'' paradigm, severely limiting their generalizability and scalability in multi-task scenarios. Motivated by the cross-domain generalization ability of large language models, we propose a universal visual perception framework based on flow matching that can generate diverse visual representations across multiple tasks. Our approach formulates the process as a universal flow-matching problem from image patch tokens to task-specific representations rather than an independent generation or regression problem. By leveraging a strong self-supervised foundation model as the anchor and introducing a multi-scale, circular task embedding mechanism, our method learns a universal velocity field to bridge the gap between heterogeneous tasks, supporting efficient and flexible representation transfer. Extensive experiments on classification, detection, segmentation, depth estimation, and image-text retrieval demonstrate that our model achieves competitive performance in both zero-shot and fine-tuned settings, outperforming prior generalist and several specialist models. Ablation studies further validate the robustness, scalability, and generalization of our framework. Our work marks a significant step towards general-purpose visual perception, providing a solid foundation for future research in universal vision modeling.
Recovering Parametric Scenes from Very Few Time-of-Flight Pixels
Sep 19, 2025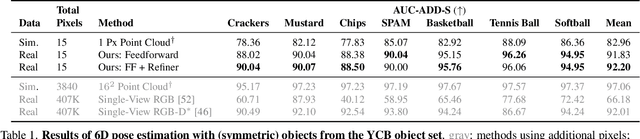
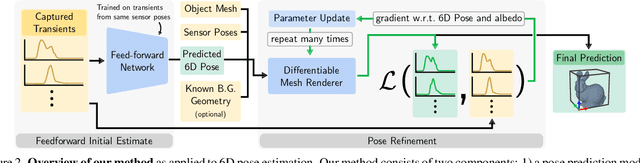
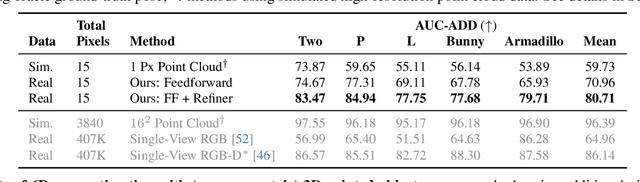
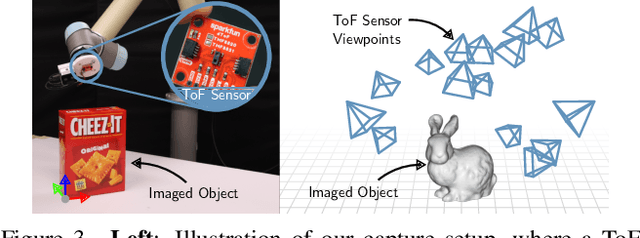
We aim to recover the geometry of 3D parametric scenes using very few depth measurements from low-cost, commercially available time-of-flight sensors. These sensors offer very low spatial resolution (i.e., a single pixel), but image a wide field-of-view per pixel and capture detailed time-of-flight data in the form of time-resolved photon counts. This time-of-flight data encodes rich scene information and thus enables recovery of simple scenes from sparse measurements. We investigate the feasibility of using a distributed set of few measurements (e.g., as few as 15 pixels) to recover the geometry of simple parametric scenes with a strong prior, such as estimating the 6D pose of a known object. To achieve this, we design a method that utilizes both feed-forward prediction to infer scene parameters, and differentiable rendering within an analysis-by-synthesis framework to refine the scene parameter estimate. We develop hardware prototypes and demonstrate that our method effectively recovers object pose given an untextured 3D model in both simulations and controlled real-world captures, and show promising initial results for other parametric scenes. We additionally conduct experiments to explore the limits and capabilities of our imaging solution.
Robust 3D Object Detection using Probabilistic Point Clouds from Single-Photon LiDARs
Jul 31, 2025LiDAR-based 3D sensors provide point clouds, a canonical 3D representation used in various scene understanding tasks. Modern LiDARs face key challenges in several real-world scenarios, such as long-distance or low-albedo objects, producing sparse or erroneous point clouds. These errors, which are rooted in the noisy raw LiDAR measurements, get propagated to downstream perception models, resulting in potentially severe loss of accuracy. This is because conventional 3D processing pipelines do not retain any uncertainty information from the raw measurements when constructing point clouds. We propose Probabilistic Point Clouds (PPC), a novel 3D scene representation where each point is augmented with a probability attribute that encapsulates the measurement uncertainty (or confidence) in the raw data. We further introduce inference approaches that leverage PPC for robust 3D object detection; these methods are versatile and can be used as computationally lightweight drop-in modules in 3D inference pipelines. We demonstrate, via both simulations and real captures, that PPC-based 3D inference methods outperform several baselines using LiDAR as well as camera-LiDAR fusion models, across challenging indoor and outdoor scenarios involving small, distant, and low-albedo objects, as well as strong ambient light. Our project webpage is at https://bhavyagoyal.github.io/ppc .