 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheck and Link: Pairwise Lesion Correspondence Guides Mammogram Mass Detection
Sep 13, 2022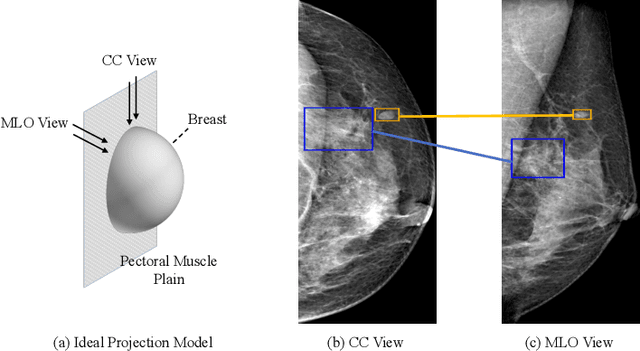
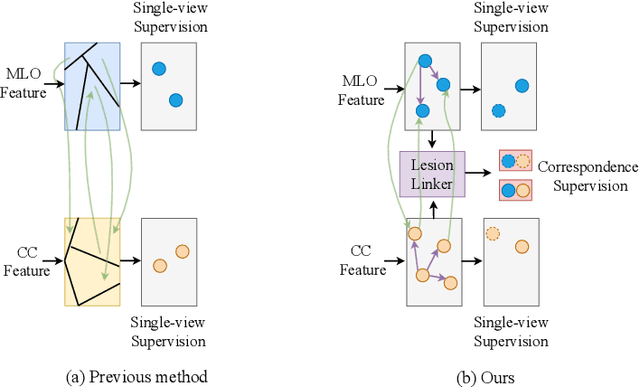
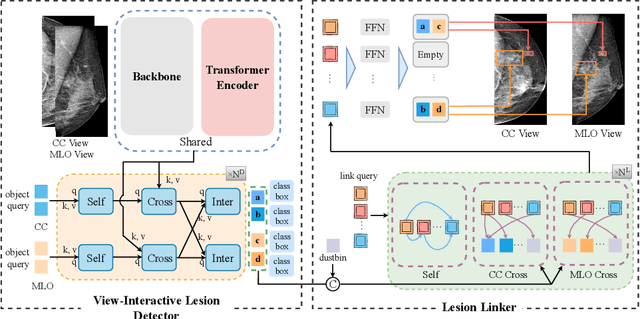
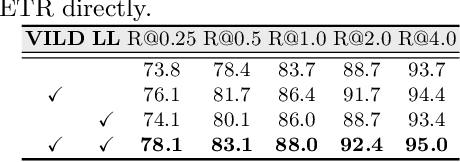
Detecting mass in mammogram is significant due to the high occurrence and mortality of breast cancer. In mammogram mass detection, modeling pairwise lesion correspondence explicitly is particularly important. However, most of the existing methods build relatively coarse correspondence and have not utilized correspondence supervision. In this paper, we propose a new transformer-based framework CL-Net to learn lesion detection and pairwise correspondence in an end-to-end manner. In CL-Net, View-Interactive Lesion Detector is proposed to achieve dynamic interaction across candidates of cross views, while Lesion Linker employs the correspondence supervision to guide the interaction process more accurately. The combination of these two designs accomplishes precise understanding of pairwise lesion correspondence for mammograms. Experiments show that CL-Net yields state-of-the-art performance on the public DDSM dataset and our in-house dataset. Moreover, it outperforms previous methods by a large margin in low FPI regime.
PointScatter: Point Set Representation for Tubular Structure Extraction
Sep 13, 2022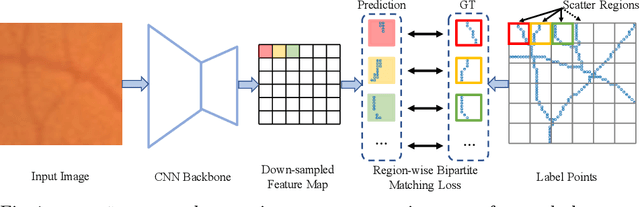
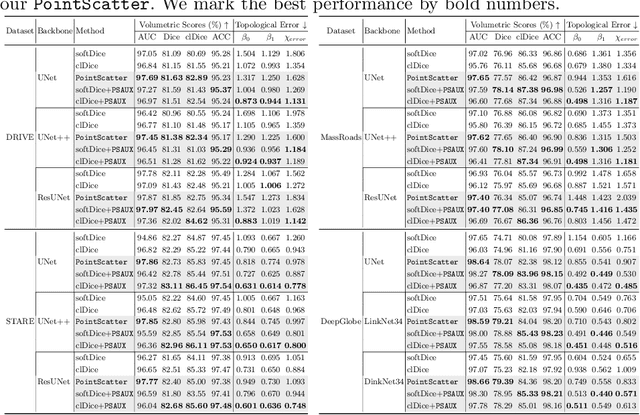
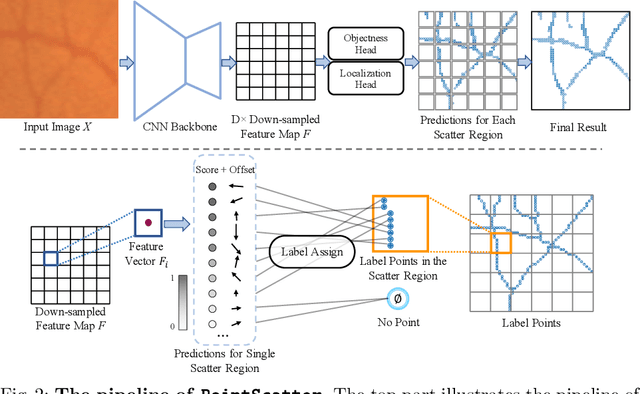
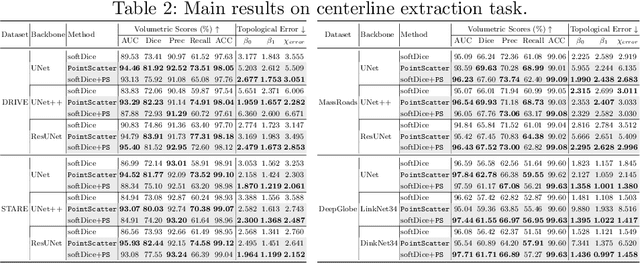
This paper explores the point set representation for tubular structure extraction tasks. Compared with the traditional mask representation, the point set representation enjoys its flexibility and representation ability, which would not be restricted by the fixed grid as the mask. Inspired by this, we propose PointScatter, an alternative to the segmentation models for the tubular structure extraction task. PointScatter splits the image into scatter regions and parallelly predicts points for each scatter region. We further propose the greedy-based region-wise bipartite matching algorithm to train the network end-to-end and efficiently. We benchmark the PointScatter on four public tubular datasets, and the extensive experiments on tubular structure segmentation and centerline extraction task demonstrate the effectiveness of our approach. Code is available at https://github.com/zhangzhao2022/pointscatter.
Boosting 3D Object Detection via Object-Focused Image Fusion
Jul 21, 2022
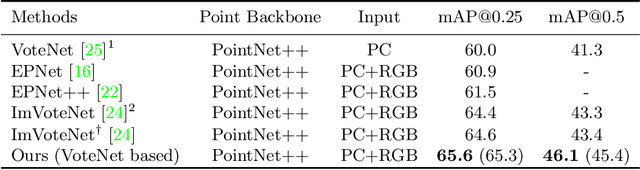

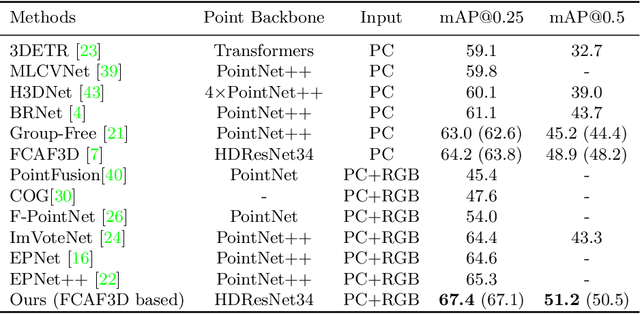
3D object detection has achieved remarkable progress by taking point clouds as the only input. However, point clouds often suffer from incomplete geometric structures and the lack of semantic information, which makes detectors hard to accurately classify detected objects. In this work, we focus on how to effectively utilize object-level information from images to boost the performance of point-based 3D detector. We present DeMF, a simple yet effective method to fuse image information into point features. Given a set of point features and image feature maps, DeMF adaptively aggregates image features by taking the projected 2D location of the 3D point as reference. We evaluate our method on the challenging SUN RGB-D dataset, improving state-of-the-art results by a large margin (+2.1 mAP@0.25 and +2.3mAP@0.5). Code is available at https://github.com/haoy945/DeMF.
DecoupleNet: Decoupled Network for Domain Adaptive Semantic Segmentation
Jul 20, 2022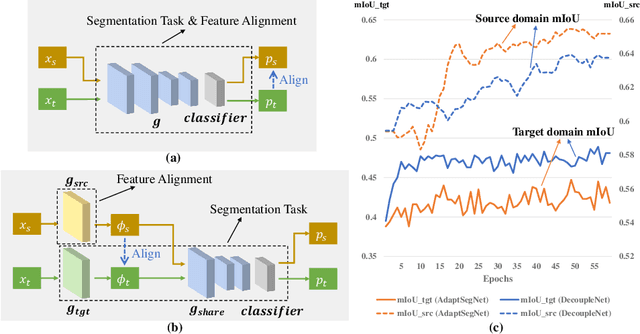
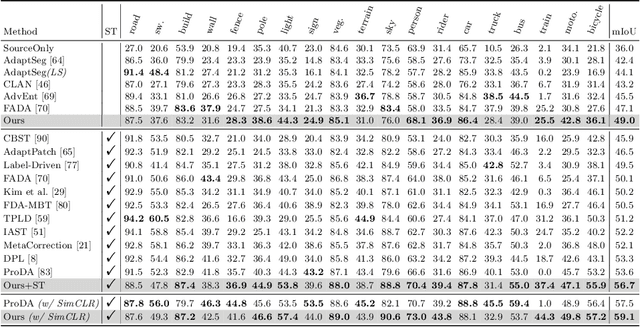
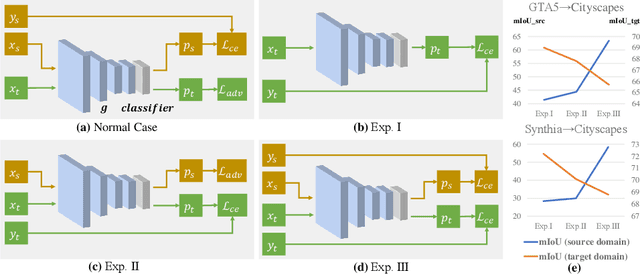
Unsupervised domain adaptation in semantic segmentation has been raised to alleviate the reliance on expensive pixel-wise annotations. It leverages a labeled source domain dataset as well as unlabeled target domain images to learn a segmentation network. In this paper, we observe two main issues of the existing domain-invariant learning framework. (1) Being distracted by the feature distribution alignment, the network cannot focus on the segmentation task. (2) Fitting source domain data well would compromise the target domain performance. To address these issues, we propose DecoupleNet that alleviates source domain overfitting and enables the final model to focus more on the segmentation task. Furthermore, we put forward Self-Discrimination (SD) and introduce an auxiliary classifier to learn more discriminative target domain features with pseudo labels. Finally, we propose Online Enhanced Self-Training (OEST) to contextually enhance the quality of pseudo labels in an online manner. Experiments show our method outperforms existing state-of-the-art methods, and extensive ablation studies verify the effectiveness of each component. Code is available at https://github.com/dvlab-research/DecoupleNet.
Is $L^2$ Physics-Informed Loss Always Suitable for Training Physics-Informed Neural Network?
Jun 04, 2022
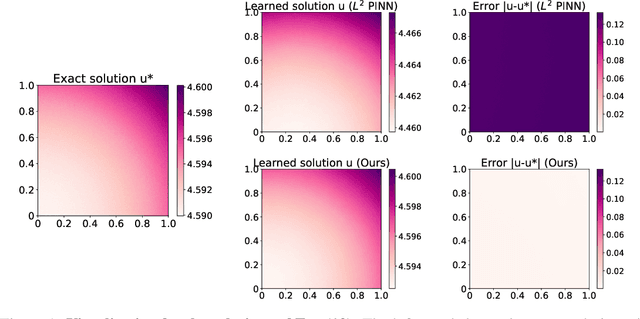
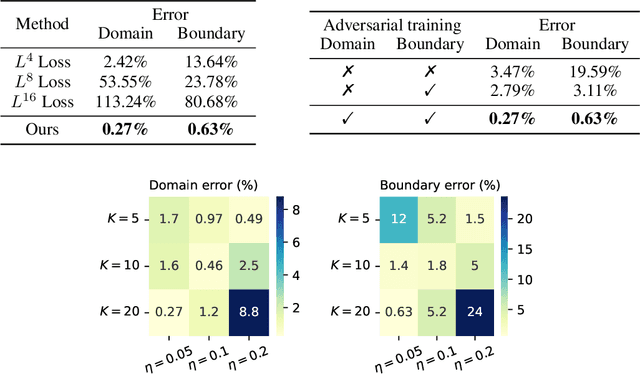
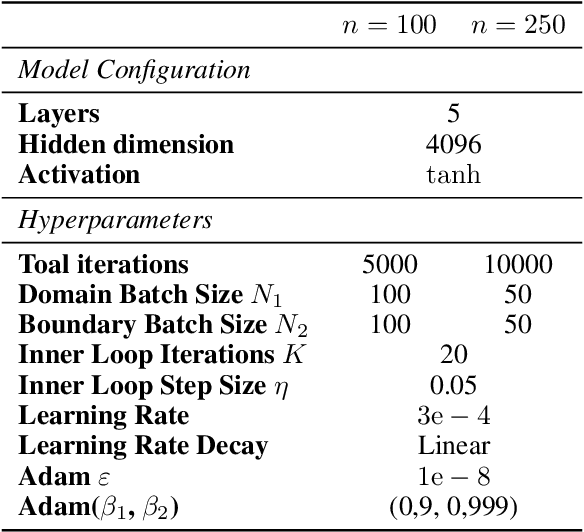
The Physics-Informed Neural Network (PINN) approach is a new and promising way to solve partial differential equations using deep learning. The $L^2$ Physics-Informed Loss is the de-facto standard in training Physics-Informed Neural Networks. In this paper, we challenge this common practice by investigating the relationship between the loss function and the approximation quality of the learned solution. In particular, we leverage the concept of stability in the literature of partial differential equation to study the asymptotic behavior of the learned solution as the loss approaches zero. With this concept, we study an important class of high-dimensional non-linear PDEs in optimal control, the Hamilton-Jacobi-Bellman(HJB) Equation, and prove that for general $L^p$ Physics-Informed Loss, a wide class of HJB equation is stable only if $p$ is sufficiently large. Therefore, the commonly used $L^2$ loss is not suitable for training PINN on those equations, while $L^{\infty}$ loss is a better choice. Based on the theoretical insight, we develop a novel PINN training algorithm to minimize the $L^{\infty}$ loss for HJB equations which is in a similar spirit to adversarial training. The effectiveness of the proposed algorithm is empirically demonstrated through experiments.
Voxel Field Fusion for 3D Object Detection
May 31, 2022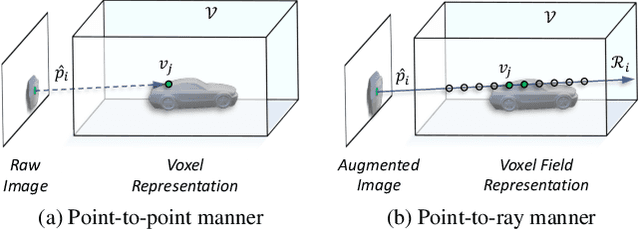

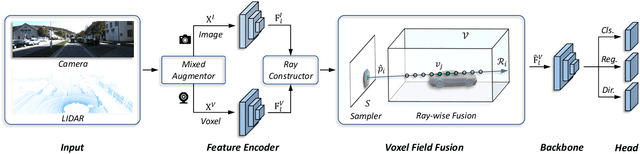
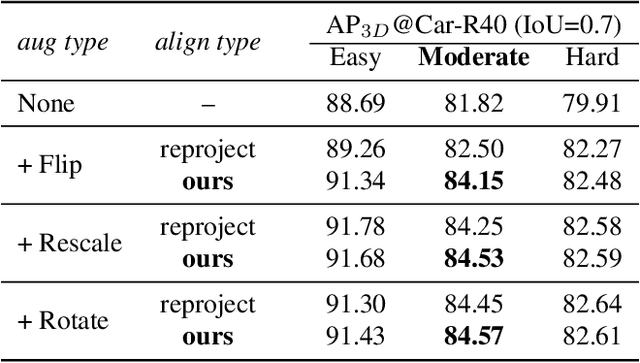
In this work, we present a conceptually simple yet effective framework for cross-modality 3D object detection, named voxel field fusion. The proposed approach aims to maintain cross-modality consistency by representing and fusing augmented image features as a ray in the voxel field. To this end, the learnable sampler is first designed to sample vital features from the image plane that are projected to the voxel grid in a point-to-ray manner, which maintains the consistency in feature representation with spatial context. In addition, ray-wise fusion is conducted to fuse features with the supplemental context in the constructed voxel field. We further develop mixed augmentor to align feature-variant transformations, which bridges the modality gap in data augmentation. The proposed framework is demonstrated to achieve consistent gains in various benchmarks and outperforms previous fusion-based methods on KITTI and nuScenes datasets. Code is made available at https://github.com/dvlab-research/VFF.
Nearly Minimax Optimal Offline Reinforcement Learning with Linear Function Approximation: Single-Agent MDP and Markov Game
May 31, 2022


Offline reinforcement learning (RL) aims at learning an optimal strategy using a pre-collected dataset without further interactions with the environment. While various algorithms have been proposed for offline RL in the previous literature, the minimax optimal performance has only been (nearly) achieved for tabular Markov decision processes (MDPs). In this paper, we focus on offline RL with linear function approximation and propose two new algorithms, SPEVI+ and SPMVI+, for single-agent MDPs and two-player zero-sum Markov games (MGs), respectively. The proposed algorithms feature carefully crafted data splitting mechanisms and novel variance-reduction pessimistic estimators. Theoretical analysis demonstrates that they are capable of matching the performance lower bounds up to logarithmic factors. As a byproduct, a new performance lower bound is established for MGs, which tightens the existing results. To the best of our knowledge, these are the first computationally efficient and nearly minimax optimal algorithms for offline single-agent MDPs and MGs with linear function approximation.
Why Robust Generalization in Deep Learning is Difficult: Perspective of Expressive Power
May 27, 2022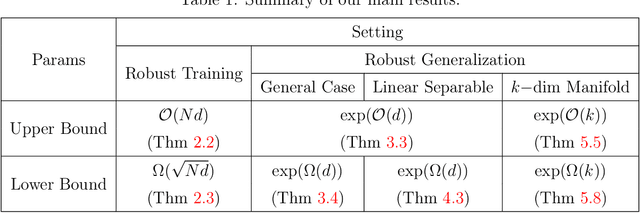

It is well-known that modern neural networks are vulnerable to adversarial examples. To mitigate this problem, a series of robust learning algorithms have been proposed. However, although the robust training error can be near zero via some methods, all existing algorithms lead to a high robust generalization error. In this paper, we provide a theoretical understanding of this puzzling phenomenon from the perspective of expressive power for deep neural networks. Specifically, for binary classification problems with well-separated data, we show that, for ReLU networks, while mild over-parameterization is sufficient for high robust training accuracy, there exists a constant robust generalization gap unless the size of the neural network is exponential in the data dimension $d$. Even if the data is linear separable, which means achieving low clean generalization error is easy, we can still prove an $\exp({\Omega}(d))$ lower bound for robust generalization. Moreover, we establish an improved upper bound of $\exp({\mathcal{O}}(k))$ for the network size to achieve low robust generalization error when the data lies on a manifold with intrinsic dimension $k$ ($k \ll d$). Nonetheless, we also have a lower bound that grows exponentially with respect to $k$ -- the curse of dimensionality is inevitable. By demonstrating an exponential separation between the network size for achieving low robust training and generalization error, our results reveal that the hardness of robust generalization may stem from the expressive power of practical models.
Your Transformer May Not be as Powerful as You Expect
May 26, 2022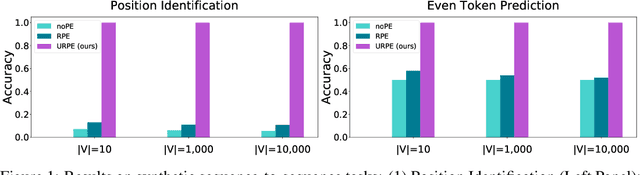
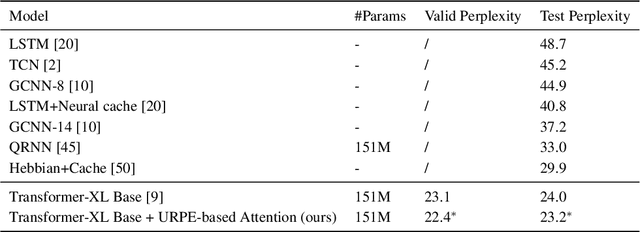
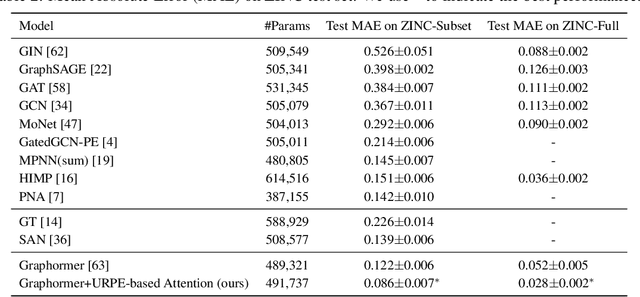
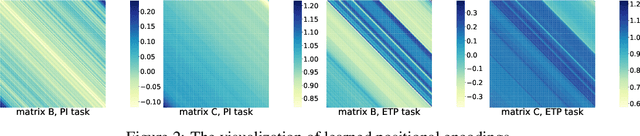
Relative Positional Encoding (RPE), which encodes the relative distance between any pair of tokens, is one of the most successful modifications to the original Transformer. As far as we know, theoretical understanding of the RPE-based Transformers is largely unexplored. In this work, we mathematically analyze the power of RPE-based Transformers regarding whether the model is capable of approximating any continuous sequence-to-sequence functions. One may naturally assume the answer is in the affirmative -- RPE-based Transformers are universal function approximators. However, we present a negative result by showing there exist continuous sequence-to-sequence functions that RPE-based Transformers cannot approximate no matter how deep and wide the neural network is. One key reason lies in that most RPEs are placed in the softmax attention that always generates a right stochastic matrix. This restricts the network from capturing positional information in the RPEs and limits its capacity. To overcome the problem and make the model more powerful, we first present sufficient conditions for RPE-based Transformers to achieve universal function approximation. With the theoretical guidance, we develop a novel attention module, called Universal RPE-based (URPE) Attention, which satisfies the conditions. Therefore, the corresponding URPE-based Transformers become universal function approximators. Extensive experiments covering typical architectures and tasks demonstrate that our model is parameter-efficient and can achieve superior performance to strong baselines in a wide range of applications.
Human-in-the-loop: Provably Efficient Preference-based Reinforcement Learning with General Function Approximation
May 24, 2022We study human-in-the-loop reinforcement learning (RL) with trajectory preferences, where instead of receiving a numeric reward at each step, the agent only receives preferences over trajectory pairs from a human overseer. The goal of the agent is to learn the optimal policy which is most preferred by the human overseer. Despite the empirical successes, the theoretical understanding of preference-based RL (PbRL) is only limited to the tabular case. In this paper, we propose the first optimistic model-based algorithm for PbRL with general function approximation, which estimates the model using value-targeted regression and calculates the exploratory policies by solving an optimistic planning problem. Our algorithm achieves the regret of $\tilde{O} (\operatorname{poly}(d H) \sqrt{K} )$, where $d$ is the complexity measure of the transition and preference model depending on the Eluder dimension and log-covering numbers, $H$ is the planning horizon, $K$ is the number of episodes, and $\tilde O(\cdot)$ omits logarithmic terms. Our lower bound indicates that our algorithm is near-optimal when specialized to the linear setting. Furthermore, we extend the PbRL problem by formulating a novel problem called RL with $n$-wise comparisons, and provide the first sample-efficient algorithm for this new setting. To the best of our knowledge, this is the first theoretical result for PbRL with (general) function approximation.