 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Improved Preference Optimization Pipeline: from Data Generation to Budget-Controlled Regularization
Nov 07, 2024



Direct Preference Optimization (DPO) and its variants have become the de facto standards for aligning large language models (LLMs) with human preferences or specific goals. However, DPO requires high-quality preference data and suffers from unstable preference optimization. In this work, we aim to improve the preference optimization pipeline by taking a closer look at preference data generation and training regularization techniques. For preference data generation, we demonstrate that existing scoring-based reward models produce unsatisfactory preference data and perform poorly on out-of-distribution tasks. This significantly impacts the LLM alignment performance when using these data for preference tuning. To ensure high-quality preference data generation, we propose an iterative pairwise ranking mechanism that derives preference ranking of completions using pairwise comparison signals. For training regularization, we observe that preference optimization tends to achieve better convergence when the LLM predicted likelihood of preferred samples gets slightly reduced. However, the widely used supervised next-word prediction regularization strictly prevents any likelihood reduction of preferred samples. This observation motivates our design of a budget-controlled regularization formulation. Empirically we show that combining the two designs leads to aligned models that surpass existing SOTA across two popular benchmarks.
DFlow: Diverse Dialogue Flow Simulation with Large Language Models
Oct 18, 2024Developing language model-based dialogue agents requires effective data to train models that can follow specific task logic. However, most existing data augmentation methods focus on increasing diversity in language, topics, or dialogue acts at the utterance level, largely neglecting a critical aspect of task logic diversity at the dialogue level. This paper proposes a novel data augmentation method designed to enhance the diversity of synthetic dialogues by focusing on task execution logic. Our method uses LLMs to generate decision tree-structured task plans, which enables the derivation of diverse dialogue trajectories for a given task. Each trajectory, referred to as a "dialog flow", guides the generation of a multi-turn dialogue that follows a unique trajectory. We apply this method to generate a task-oriented dialogue dataset comprising 3,886 dialogue flows across 15 different domains. We validate the effectiveness of this dataset using the next action prediction task, where models fine-tuned on our dataset outperform strong baselines, including GPT-4. Upon acceptance of this paper, we plan to release the code and data publicly.
Blending Reward Functions via Few Expert Demonstrations for Faithful and Accurate Knowledge-Grounded Dialogue Generation
Nov 02, 2023The development of trustworthy conversational information-seeking systems relies on dialogue models that can generate faithful and accurate responses based on relevant knowledge texts. However, two main challenges hinder this task. Firstly, language models may generate hallucinations due to data biases present in their pretraining corpus. Secondly, knowledge texts often contain redundant and irrelevant information that distracts the model's attention from the relevant text span. Previous works use additional data annotations on the knowledge texts to learn a knowledge identification module in order to bypass irrelevant information, but collecting such high-quality span annotations can be costly. In this work, we leverage reinforcement learning algorithms to overcome the above challenges by introducing a novel reward function. Our reward function combines an accuracy metric and a faithfulness metric to provide a balanced quality judgment of generated responses, which can be used as a cost-effective approximation to a human preference reward model when only a few preference annotations are available. Empirical experiments on two conversational information-seeking datasets demonstrate that our method can compete with other strong supervised learning baselines.
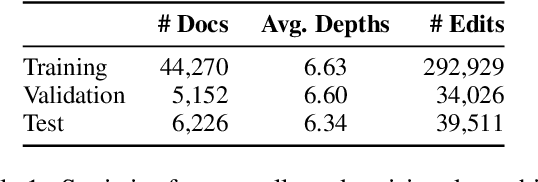
Improving Iterative Text Revision by Learning Where to Edit from Other Revision Tasks
Dec 02, 2022Iterative text revision improves text quality by fixing grammatical errors, rephrasing for better readability or contextual appropriateness, or reorganizing sentence structures throughout a document. Most recent research has focused on understanding and classifying different types of edits in the iterative revision process from human-written text instead of building accurate and robust systems for iterative text revision. In this work, we aim to build an end-to-end text revision system that can iteratively generate helpful edits by explicitly detecting editable spans (where-to-edit) with their corresponding edit intents and then instructing a revision model to revise the detected edit spans. Leveraging datasets from other related text editing NLP tasks, combined with the specification of editable spans, leads our system to more accurately model the process of iterative text refinement, as evidenced by empirical results and human evaluations. Our system significantly outperforms previous baselines on our text revision tasks and other standard text revision tasks, including grammatical error correction, text simplification, sentence fusion, and style transfer. Through extensive qualitative and quantitative analysis, we make vital connections between edit intentions and writing quality, and better computational modeling of iterative text revisions.
Self-augmented Data Selection for Few-shot Dialogue Generation
May 19, 2022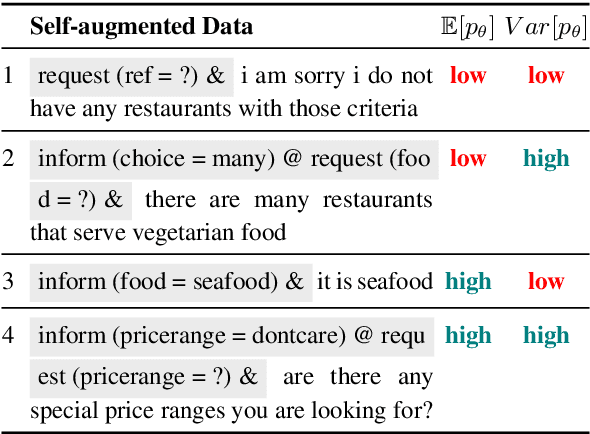
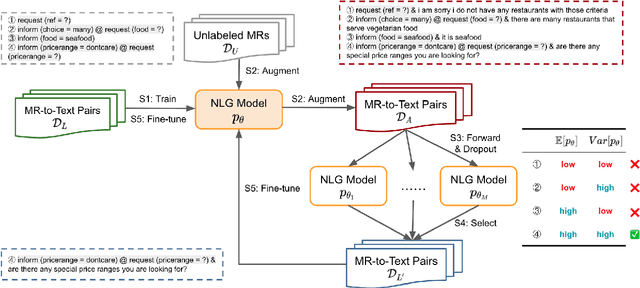

The natural language generation (NLG) module in task-oriented dialogue systems translates structured meaning representations (MRs) into text responses, which has a great impact on users' experience as the human-machine interaction interface. However, in practice, developers often only have a few well-annotated data and confront a high data collection cost to build the NLG module. In this work, we adopt the self-training framework to deal with the few-shot MR-to-Text generation problem. We leverage the pre-trained language model to self-augment many pseudo-labeled data. To prevent the gradual drift from target data distribution to noisy augmented data distribution, we propose a novel data selection strategy to select the data that our generation model is most uncertain about. Compared with existing data selection methods, our method is: (1) parameter-efficient, which does not require training any additional neural models, (2) computation-efficient, which only needs to apply several stochastic forward passes of the model to estimate the uncertainty. We conduct empirical experiments on two benchmark datasets: FewShotWOZ and FewShotSGD, and show that our proposed framework consistently outperforms other baselines in terms of BLEU and ERR.
Read, Revise, Repeat: A System Demonstration for Human-in-the-loop Iterative Text Revision
Apr 07, 2022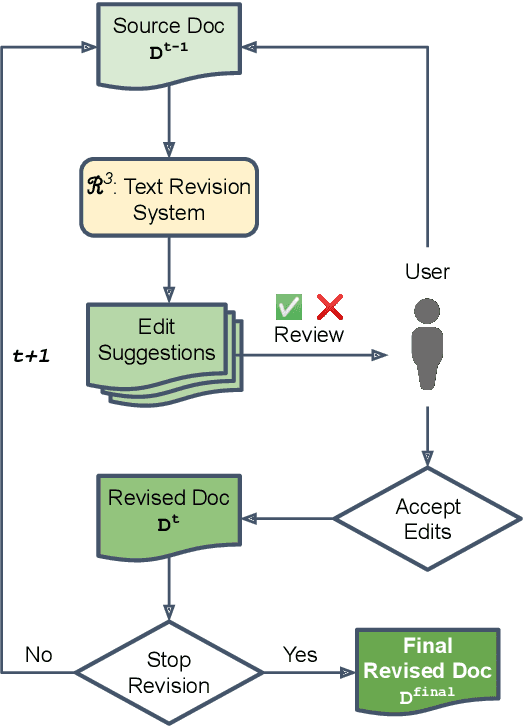


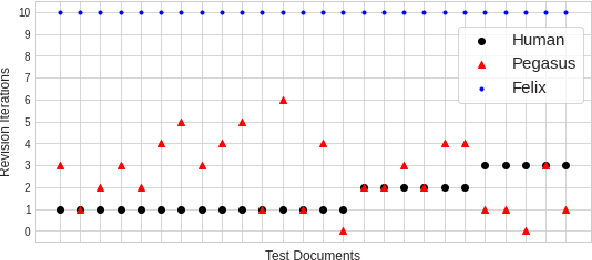
Revision is an essential part of the human writing process. It tends to be strategic, adaptive, and, more importantly, iterative in nature. Despite the success of large language models on text revision tasks, they are limited to non-iterative, one-shot revisions. Examining and evaluating the capability of large language models for making continuous revisions and collaborating with human writers is a critical step towards building effective writing assistants. In this work, we present a human-in-the-loop iterative text revision system, Read, Revise, Repeat (R3), which aims at achieving high quality text revisions with minimal human efforts by reading model-generated revisions and user feedbacks, revising documents, and repeating human-machine interactions. In R3, a text revision model provides text editing suggestions for human writers, who can accept or reject the suggested edits. The accepted edits are then incorporated into the model for the next iteration of document revision. Writers can therefore revise documents iteratively by interacting with the system and simply accepting/rejecting its suggested edits until the text revision model stops making further revisions or reaches a predefined maximum number of revisions. Empirical experiments show that R3 can generate revisions with comparable acceptance rate to human writers at early revision depths, and the human-machine interaction can get higher quality revisions with fewer iterations and edits. The collected human-model interaction dataset and system code are available at \url{https://github.com/vipulraheja/IteraTeR}. Our system demonstration is available at \url{https://youtu.be/lK08tIpEoaE}.
Diverse Text Generation via Variational Encoder-Decoder Models with Gaussian Process Priors
Apr 04, 2022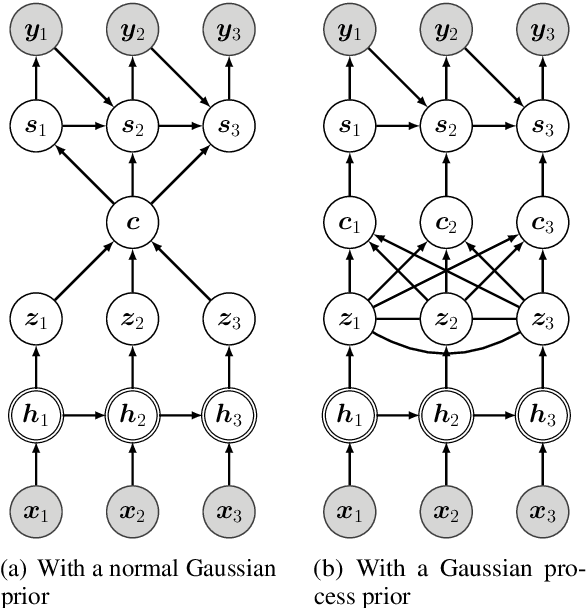

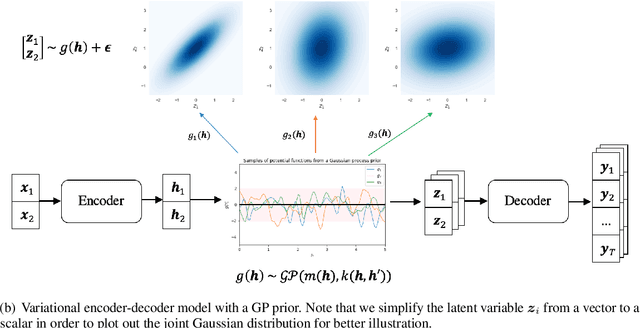
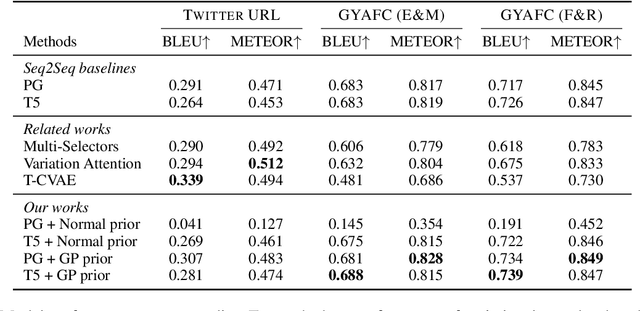
Generating high quality texts with high diversity is important for many NLG applications, but current methods mostly focus on building deterministic models to generate higher quality texts and do not provide many options for promoting diversity. In this work, we present a novel latent structured variable model to generate high quality texts by enriching contextual representation learning of encoder-decoder models. Specifically, we introduce a stochastic function to map deterministic encoder hidden states into random context variables. The proposed stochastic function is sampled from a Gaussian process prior to (1) provide infinite number of joint Gaussian distributions of random context variables (diversity-promoting) and (2) explicitly model dependency between context variables (accurate-encoding). To address the learning challenge of Gaussian processes, we propose an efficient variational inference approach to approximate the posterior distribution of random context variables. We evaluate our method in two typical text generation tasks: paraphrase generation and text style transfer. Experimental results on benchmark datasets demonstrate that our method improves the generation quality and diversity compared with other baselines.
Understanding Iterative Revision from Human-Written Text
Mar 16, 2022
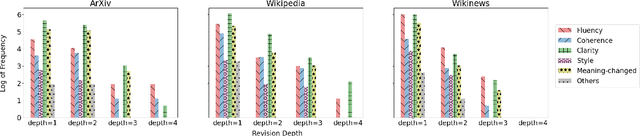
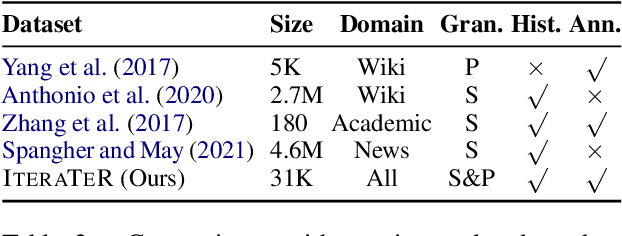
Writing is, by nature, a strategic, adaptive, and more importantly, an iterative process. A crucial part of writing is editing and revising the text. Previous works on text revision have focused on defining edit intention taxonomies within a single domain or developing computational models with a single level of edit granularity, such as sentence-level edits, which differ from human's revision cycles. This work describes IteraTeR: the first large-scale, multi-domain, edit-intention annotated corpus of iteratively revised text. In particular, IteraTeR is collected based on a new framework to comprehensively model the iterative text revisions that generalize to various domains of formal writing, edit intentions, revision depths, and granularities. When we incorporate our annotated edit intentions, both generative and edit-based text revision models significantly improve automatic evaluations. Through our work, we better understand the text revision process, making vital connections between edit intentions and writing quality, enabling the creation of diverse corpora to support computational modeling of iterative text revisions.
FlowEval: A Consensus-Based Dialogue Evaluation Framework Using Segment Act Flows
Feb 14, 2022



Despite recent progress in open-domain dialogue evaluation, how to develop automatic metrics remains an open problem. We explore the potential of dialogue evaluation featuring dialog act information, which was hardly explicitly modeled in previous methods. However, defined at the utterance level in general, dialog act is of coarse granularity, as an utterance can contain multiple segments possessing different functions. Hence, we propose segment act, an extension of dialog act from utterance level to segment level, and crowdsource a large-scale dataset for it. To utilize segment act flows, sequences of segment acts, for evaluation, we develop the first consensus-based dialogue evaluation framework, FlowEval. This framework provides a reference-free approach for dialog evaluation by finding pseudo-references. Extensive experiments against strong baselines on three benchmark datasets demonstrate the effectiveness and other desirable characteristics of our FlowEval, pointing out a potential path for better dialogue evaluation.
SideControl: Controlled Open-domain Dialogue Generation via Additive Side Networks
Sep 05, 2021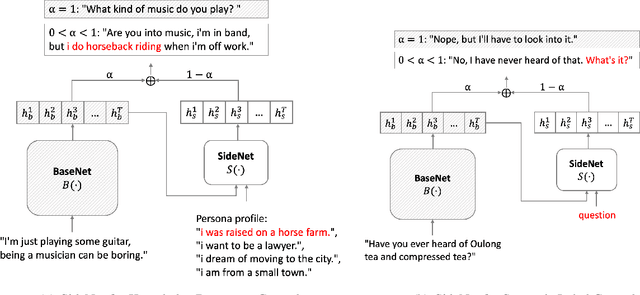
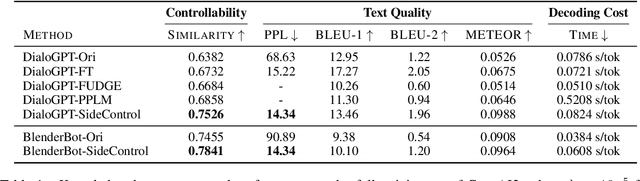
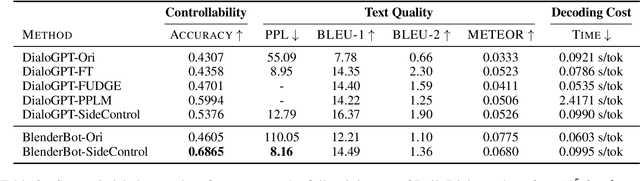
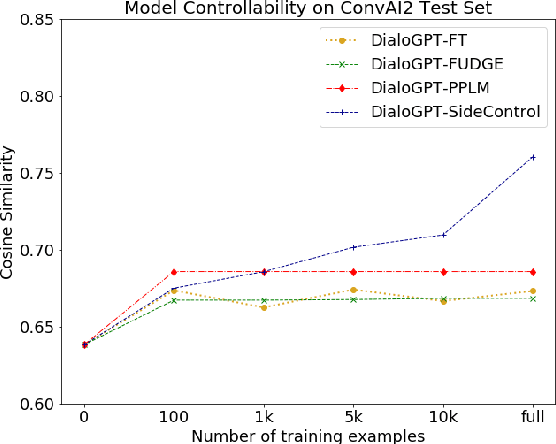
Transformer-based pre-trained language models boost the performance of open-domain dialogue systems. Prior works leverage Transformer-based pre-trained language models to generate texts with desired attributes in two general approaches: (1) gradient-based methods: updating all latent representations of pre-trained models with gradients from attribute models; (2) weighted-decoding methods: re-ranking beam candidates from pre-trained models with attribute functions. However, gradient-based methods lead to high computation cost and can easily get overfitted on small training sets, while weighted-decoding methods are inherently constrained by the low-variance high-bias pre-trained model. In this work, we propose a novel approach to control the generation of Transformer-based pre-trained language models: the SideControl framework, which leverages a novel control attributes loss to incorporate useful control signals, and is shown to perform well with very limited training samples. We evaluate our proposed method on two benchmark open-domain dialogue datasets, and results show that the SideControl framework has better controllability, higher generation quality and better sample-efficiency than existing gradient-based and weighted-decoding baselines.