 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePivotRL: High Accuracy Agentic Post-Training at Low Compute Cost
Mar 22, 2026Post-training for long-horizon agentic tasks has a tension between compute efficiency and generalization. While supervised fine-tuning (SFT) is compute efficient, it often suffers from out-of-domain (OOD) degradation. Conversely, end-to-end reinforcement learning (E2E RL) preserves OOD capabilities, but incurs high compute costs due to many turns of on-policy rollout. We introduce PivotRL, a novel framework that operates on existing SFT trajectories to combine the compute efficiency of SFT with the OOD accuracy of E2E RL. PivotRL relies on two key mechanisms: first, it executes local, on-policy rollouts and filters for pivots: informative intermediate turns where sampled actions exhibit high variance in outcomes; second, it utilizes rewards for functional-equivalent actions rather than demanding strict string matching with the SFT data demonstration. We theoretically show that these mechanisms incentivize strong learning signals with high natural gradient norm, while maximally preserving policy probability ordering on actions unrelated to training tasks. In comparison to standard SFT on identical data, we demonstrate that PivotRL achieves +4.17% higher in-domain accuracy on average across four agentic domains, and +10.04% higher OOD accuracy in non-agentic tasks. Notably, on agentic coding tasks, PivotRL achieves competitive accuracy with E2E RL with 4x fewer rollout turns. PivotRL is adopted by NVIDIA's Nemotron-3-Super-120B-A12B, acting as the workhorse in production-scale agentic post-training.
Towards Anytime-Valid Statistical Watermarking
Feb 19, 2026The proliferation of Large Language Models (LLMs) necessitates efficient mechanisms to distinguish machine-generated content from human text. While statistical watermarking has emerged as a promising solution, existing methods suffer from two critical limitations: the lack of a principled approach for selecting sampling distributions and the reliance on fixed-horizon hypothesis testing, which precludes valid early stopping. In this paper, we bridge this gap by developing the first e-value-based watermarking framework, Anchored E-Watermarking, that unifies optimal sampling with anytime-valid inference. Unlike traditional approaches where optional stopping invalidates Type-I error guarantees, our framework enables valid, anytime-inference by constructing a test supermartingale for the detection process. By leveraging an anchor distribution to approximate the target model, we characterize the optimal e-value with respect to the worst-case log-growth rate and derive the optimal expected stopping time. Our theoretical claims are substantiated by simulations and evaluations on established benchmarks, showing that our framework can significantly enhance sample efficiency, reducing the average token budget required for detection by 13-15% relative to state-of-the-art baselines.
dUltra: Ultra-Fast Diffusion Language Models via Reinforcement Learning
Dec 24, 2025Masked diffusion language models (MDLMs) offer the potential for parallel token generation, but most open-source MDLMs decode fewer than 5 tokens per model forward pass even with sophisticated sampling strategies. As a result, their sampling speeds are often comparable to AR + speculative decoding schemes, limiting their advantage over mainstream autoregressive approaches. Existing distillation-based accelerators (dParallel, d3LLM) finetune MDLMs on trajectories generated by a base model, which can become off-policy during finetuning and restrict performance to the quality of the base model's samples. We propose \texttt{dUltra}, an on-policy reinforcement learning framework based on Group Relative Policy Optimization (GRPO) that learns unmasking strategies for efficient parallel decoding. dUltra introduces an unmasking planner head that predicts per-token unmasking likelihoods under independent Bernoulli distributions. We jointly optimize the base diffusion LLM and the unmasking order planner using reward signals combining verifiable reward, distillation reward, and the number of unmasking steps. Across mathematical reasoning and code generation tasks, dUltra improves the accuracy--efficiency trade-off over state-of-the-art heuristic and distillation baselines, moving towards achieving ``diffusion supremacy'' over autoregressive models.
GSM-Agent: Understanding Agentic Reasoning Using Controllable Environments
Sep 26, 2025
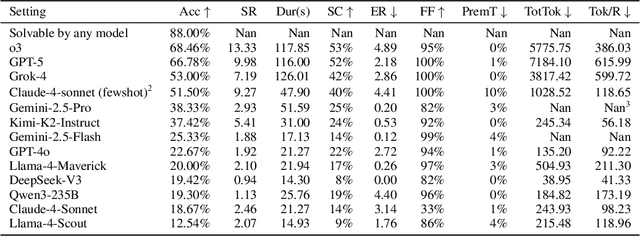


As LLMs are increasingly deployed as agents, agentic reasoning - the ability to combine tool use, especially search, and reasoning - becomes a critical skill. However, it is hard to disentangle agentic reasoning when evaluated in complex environments and tasks. Current agent benchmarks often mix agentic reasoning with challenging math reasoning, expert-level knowledge, and other advanced capabilities. To fill this gap, we build a novel benchmark, GSM-Agent, where an LLM agent is required to solve grade-school-level reasoning problems, but is only presented with the question in the prompt without the premises that contain the necessary information to solve the task, and needs to proactively collect that information using tools. Although the original tasks are grade-school math problems, we observe that even frontier models like GPT-5 only achieve 67% accuracy. To understand and analyze the agentic reasoning patterns, we propose the concept of agentic reasoning graph: cluster the environment's document embeddings into nodes, and map each tool call to its nearest node to build a reasoning path. Surprisingly, we identify that the ability to revisit a previously visited node, widely taken as a crucial pattern in static reasoning, is often missing for agentic reasoning for many models. Based on the insight, we propose a tool-augmented test-time scaling method to improve LLM's agentic reasoning performance by adding tools to encourage models to revisit. We expect our benchmark and the agentic reasoning framework to aid future studies of understanding and pushing the boundaries of agentic reasoning.
Generalization or Hallucination? Understanding Out-of-Context Reasoning in Transformers
Jun 12, 2025Large language models (LLMs) can acquire new knowledge through fine-tuning, but this process exhibits a puzzling duality: models can generalize remarkably from new facts, yet are also prone to hallucinating incorrect information. However, the reasons for this phenomenon remain poorly understood. In this work, we argue that both behaviors stem from a single mechanism known as out-of-context reasoning (OCR): the ability to deduce implications by associating concepts, even those without a causal link. Our experiments across five prominent LLMs confirm that OCR indeed drives both generalization and hallucination, depending on whether the associated concepts are causally related. To build a rigorous theoretical understanding of this phenomenon, we then formalize OCR as a synthetic factual recall task. We empirically show that a one-layer single-head attention-only transformer with factorized output and value matrices can learn to solve this task, while a model with combined weights cannot, highlighting the crucial role of matrix factorization. Our theoretical analysis shows that the OCR capability can be attributed to the implicit bias of gradient descent, which favors solutions that minimize the nuclear norm of the combined output-value matrix. This mathematical structure explains why the model learns to associate facts and implications with high sample efficiency, regardless of whether the correlation is causal or merely spurious. Ultimately, our work provides a theoretical foundation for understanding the OCR phenomenon, offering a new lens for analyzing and mitigating undesirable behaviors from knowledge injection.
Sample Complexity and Representation Ability of Test-time Scaling Paradigms
Jun 05, 2025Test-time scaling paradigms have significantly advanced the capabilities of large language models (LLMs) on complex tasks. Despite their empirical success, theoretical understanding of the sample efficiency of various test-time strategies -- such as self-consistency, best-of-$n$, and self-correction -- remains limited. In this work, we first establish a separation result between two repeated sampling strategies: self-consistency requires $\Theta(1/\Delta^2)$ samples to produce the correct answer, while best-of-$n$ only needs $\Theta(1/\Delta)$, where $\Delta < 1$ denotes the probability gap between the correct and second most likely answers. Next, we present an expressiveness result for the self-correction approach with verifier feedback: it enables Transformers to simulate online learning over a pool of experts at test time. Therefore, a single Transformer architecture can provably solve multiple tasks without prior knowledge of the specific task associated with a user query, extending the representation theory of Transformers from single-task to multi-task settings. Finally, we empirically validate our theoretical results, demonstrating the practical effectiveness of self-correction methods.
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
May 18, 2025Large Language Models (LLMs) have demonstrated remarkable performance in many applications, including challenging reasoning problems via chain-of-thoughts (CoTs) techniques that generate ``thinking tokens'' before answering the questions. While existing theoretical works demonstrate that CoTs with discrete tokens boost the capability of LLMs, recent work on continuous CoTs lacks a theoretical understanding of why it outperforms discrete counterparts in various reasoning tasks such as directed graph reachability, a fundamental graph reasoning problem that includes many practical domain applications as special cases. In this paper, we prove that a two-layer transformer with $D$ steps of continuous CoTs can solve the directed graph reachability problem, where $D$ is the diameter of the graph, while the best known result of constant-depth transformers with discrete CoTs requires $O(n^2)$ decoding steps where $n$ is the number of vertices ($D<n$). In our construction, each continuous thought vector is a superposition state that encodes multiple search frontiers simultaneously (i.e., parallel breadth-first search (BFS)), while discrete CoTs must choose a single path sampled from the superposition state, which leads to sequential search that requires many more steps and may be trapped into local solutions. We also performed extensive experiments to verify that our theoretical construction aligns well with the empirical solution obtained via training dynamics. Notably, encoding of multiple search frontiers as a superposition state automatically emerges in training continuous CoTs, without explicit supervision to guide the model to explore multiple paths simultaneously.
How Do LLMs Perform Two-Hop Reasoning in Context?
Feb 19, 2025



"Socrates is human. All humans are mortal. Therefore, Socrates is mortal." This classical example demonstrates two-hop reasoning, where a conclusion logically follows from two connected premises. While transformer-based Large Language Models (LLMs) can make two-hop reasoning, they tend to collapse to random guessing when faced with distracting premises. To understand the underlying mechanism, we train a three-layer transformer on synthetic two-hop reasoning tasks. The training dynamics show two stages: a slow learning phase, where the 3-layer transformer performs random guessing like LLMs, followed by an abrupt phase transitions, where the 3-layer transformer suddenly reaches $100%$ accuracy. Through reverse engineering, we explain the inner mechanisms for how models learn to randomly guess between distractions initially, and how they learn to ignore distractions eventually. We further propose a three-parameter model that supports the causal claims for the mechanisms to the training dynamics of the transformer. Finally, experiments on LLMs suggest that the discovered mechanisms generalize across scales. Our methodologies provide new perspectives for scientific understandings of LLMs and our findings provide new insights into how reasoning emerges during training.
Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning
Feb 05, 2025



Large Language Models (LLMs) excel at reasoning and planning when trained on chainof-thought (CoT) data, where the step-by-step thought process is explicitly outlined by text tokens. However, this results in lengthy inputs where many words support textual coherence rather than core reasoning information, and processing these inputs consumes substantial computation resources. In this work, we propose a hybrid representation of the reasoning process, where we partially abstract away the initial reasoning steps using latent discrete tokens generated by VQ-VAE, significantly reducing the length of reasoning traces. We explore the use of latent trace abstractions in two scenarios: 1) training the model from scratch for the Keys-Finding Maze problem, 2) fine-tuning LLMs on this hybrid data with an extended vocabulary including unseen latent tokens, for both logical and mathematical reasoning problems. To facilitate effective learning, we introduce a simple training procedure that randomly mixes latent and text tokens, which enables fast adaptation to new latent tokens. Our approach consistently outperforms the baselines methods in various benchmarks.
How to Evaluate Reward Models for RLHF
Oct 18, 2024



We introduce a new benchmark for reward models that quantifies their ability to produce strong language models through RLHF (Reinforcement Learning from Human Feedback). The gold-standard approach is to run a full RLHF training pipeline and directly probe downstream LLM performance. However, this process is prohibitively expensive. To address this, we build a predictive model of downstream LLM performance by evaluating the reward model on proxy tasks. These proxy tasks consist of a large-scale human preference and a verifiable correctness preference dataset, in which we measure 12 metrics across 12 domains. To investigate which reward model metrics are most correlated to gold-standard RLHF outcomes, we launch an end-to-end RLHF experiment on a large-scale crowdsourced human preference platform to view real reward model downstream performance as ground truth. Ultimately, we compile our data and findings into Preference Proxy Evaluations (PPE), the first reward model benchmark explicitly linked to post-RLHF real-world human preference performance, which we open-source for public use and further development. Our code and evaluations can be found at https://github.com/lmarena/PPE .