 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving the Hubbard model with Neural Quantum States
Jul 03, 2025The rapid development of neural quantum states (NQS) has established it as a promising framework for studying quantum many-body systems. In this work, by leveraging the cutting-edge transformer-based architectures and developing highly efficient optimization algorithms, we achieve the state-of-the-art results for the doped two-dimensional (2D) Hubbard model, arguably the minimum model for high-Tc superconductivity. Interestingly, we find different attention heads in the NQS ansatz can directly encode correlations at different scales, making it capable of capturing long-range correlations and entanglements in strongly correlated systems. With these advances, we establish the half-filled stripe in the ground state of 2D Hubbard model with the next nearest neighboring hoppings, consistent with experimental observations in cuprates. Our work establishes NQS as a powerful tool for solving challenging many-fermions systems.
Learn from Foundation Model: Fruit Detection Model without Manual Annotation
Nov 25, 2024



Recent breakthroughs in large foundation models have enabled the possibility of transferring knowledge pre-trained on vast datasets to domains with limited data availability. Agriculture is one of the domains that lacks sufficient data. This study proposes a framework to train effective, domain-specific, small models from foundation models without manual annotation. Our approach begins with SDM (Segmentation-Description-Matching), a stage that leverages two foundation models: SAM2 (Segment Anything in Images and Videos) for segmentation and OpenCLIP (Open Contrastive Language-Image Pretraining) for zero-shot open-vocabulary classification. In the second stage, a novel knowledge distillation mechanism is utilized to distill compact, edge-deployable models from SDM, enhancing both inference speed and perception accuracy. The complete method, termed SDM-D (Segmentation-Description-Matching-Distilling), demonstrates strong performance across various fruit detection tasks object detection, semantic segmentation, and instance segmentation) without manual annotation. It nearly matches the performance of models trained with abundant labels. Notably, SDM-D outperforms open-set detection methods such as Grounding SAM and YOLO-World on all tested fruit detection datasets. Additionally, we introduce MegaFruits, a comprehensive fruit segmentation dataset encompassing over 25,000 images, and all code and datasets are made publicly available at https://github.com/AgRoboticsResearch/SDM-D.git.
DOF: Accelerating High-order Differential Operators with Forward Propagation
Feb 15, 2024



Solving partial differential equations (PDEs) efficiently is essential for analyzing complex physical systems. Recent advancements in leveraging deep learning for solving PDE have shown significant promise. However, machine learning methods, such as Physics-Informed Neural Networks (PINN), face challenges in handling high-order derivatives of neural network-parameterized functions. Inspired by Forward Laplacian, a recent method of accelerating Laplacian computation, we propose an efficient computational framework, Differential Operator with Forward-propagation (DOF), for calculating general second-order differential operators without losing any precision. We provide rigorous proof of the advantages of our method over existing methods, demonstrating two times improvement in efficiency and reduced memory consumption on any architectures. Empirical results illustrate that our method surpasses traditional automatic differentiation (AutoDiff) techniques, achieving 2x improvement on the MLP structure and nearly 20x improvement on the MLP with Jacobian sparsity.
Deep Learning with Information Fusion and Model Interpretation for Health Monitoring of Fetus based on Long-term Prenatal Electronic Fetal Heart Rate Monitoring Data
Jan 27, 2024Long-term fetal heart rate (FHR) monitoring during the antepartum period, increasingly popularized by electronic FHR monitoring, represents a growing approach in FHR monitoring. This kind of continuous monitoring, in contrast to the short-term one, collects an extended period of fetal heart data. This offers a more comprehensive understanding of fetus's conditions. However, the interpretation of long-term antenatal fetal heart monitoring is still in its early stages, lacking corresponding clinical standards. Furthermore, the substantial amount of data generated by continuous monitoring imposes a significant burden on clinical work when analyzed manually. To address above challenges, this study develops an automatic analysis system named LARA (Long-term Antepartum Risk Analysis system) for continuous FHR monitoring, combining deep learning and information fusion methods. LARA's core is a well-established convolutional neural network (CNN) model. It processes long-term FHR data as input and generates a Risk Distribution Map (RDM) and Risk Index (RI) as the analysis results. We evaluate LARA on inner test dataset, the performance metrics are as follows: AUC 0.872, accuracy 0.816, specificity 0.811, sensitivity 0.806, precision 0.271, and F1 score 0.415. In our study, we observe that long-term FHR monitoring data with higher RI is more likely to result in adverse outcomes (p=0.0021). In conclusion, this study introduces LARA, the first automated analysis system for long-term FHR monitoring, initiating the further explorations into its clinical value in the future.
Landslide Surface Displacement Prediction Based on VSXC-LSTM Algorithm
Jul 24, 2023



Landslide is a natural disaster that can easily threaten local ecology, people's lives and property. In this paper, we conduct modelling research on real unidirectional surface displacement data of recent landslides in the research area and propose a time series prediction framework named VMD-SegSigmoid-XGBoost-ClusterLSTM (VSXC-LSTM) based on variational mode decomposition, which can predict the landslide surface displacement more accurately. The model performs well on the test set. Except for the random item subsequence that is hard to fit, the root mean square error (RMSE) and the mean absolute percentage error (MAPE) of the trend item subsequence and the periodic item subsequence are both less than 0.1, and the RMSE is as low as 0.006 for the periodic item prediction module based on XGBoost\footnote{Accepted in ICANN2023}.
Forward Laplacian: A New Computational Framework for Neural Network-based Variational Monte Carlo
Jul 17, 2023Neural network-based variational Monte Carlo (NN-VMC) has emerged as a promising cutting-edge technique of ab initio quantum chemistry. However, the high computational cost of existing approaches hinders their applications in realistic chemistry problems. Here, we report the development of a new NN-VMC method that achieves a remarkable speed-up by more than one order of magnitude, thereby greatly extending the applicability of NN-VMC to larger systems. Our key design is a novel computational framework named Forward Laplacian, which computes the Laplacian associated with neural networks, the bottleneck of NN-VMC, through an efficient forward propagation process. We then demonstrate that Forward Laplacian is not only versatile but also facilitates more developments of acceleration methods across various aspects, including optimization for sparse derivative matrix and efficient neural network design. Empirically, our approach enables NN-VMC to investigate a broader range of atoms, molecules and chemical reactions for the first time, providing valuable references to other ab initio methods. The results demonstrate a great potential in applying deep learning methods to solve general quantum mechanical problems.
Text Alignment Is An Efficient Unified Model for Massive NLP Tasks
Jul 06, 2023



Large language models (LLMs), typically designed as a function of next-word prediction, have excelled across extensive NLP tasks. Despite the generality, next-word prediction is often not an efficient formulation for many of the tasks, demanding an extreme scale of model parameters (10s or 100s of billions) and sometimes yielding suboptimal performance. In practice, it is often desirable to build more efficient models -- despite being less versatile, they still apply to a substantial subset of problems, delivering on par or even superior performance with much smaller model sizes. In this paper, we propose text alignment as an efficient unified model for a wide range of crucial tasks involving text entailment, similarity, question answering (and answerability), factual consistency, and so forth. Given a pair of texts, the model measures the degree of alignment between their information. We instantiate an alignment model (Align) through lightweight finetuning of RoBERTa (355M parameters) using 5.9M examples from 28 datasets. Despite its compact size, extensive experiments show the model's efficiency and strong performance: (1) On over 20 datasets of aforementioned diverse tasks, the model matches or surpasses FLAN-T5 models that have around 2x or 10x more parameters; the single unified model also outperforms task-specific models finetuned on individual datasets; (2) When applied to evaluate factual consistency of language generation on 23 datasets, our model improves over various baselines, including the much larger GPT-3.5 (ChatGPT) and sometimes even GPT-4; (3) The lightweight model can also serve as an add-on component for LLMs such as GPT-3.5 in question answering tasks, improving the average exact match (EM) score by 17.94 and F1 score by 15.05 through identifying unanswerable questions.
AlignScore: Evaluating Factual Consistency with a Unified Alignment Function
May 26, 2023Many text generation applications require the generated text to be factually consistent with input information. Automatic evaluation of factual consistency is challenging. Previous work has developed various metrics that often depend on specific functions, such as natural language inference (NLI) or question answering (QA), trained on limited data. Those metrics thus can hardly assess diverse factual inconsistencies (e.g., contradictions, hallucinations) that occur in varying inputs/outputs (e.g., sentences, documents) from different tasks. In this paper, we propose AlignScore, a new holistic metric that applies to a variety of factual inconsistency scenarios as above. AlignScore is based on a general function of information alignment between two arbitrary text pieces. Crucially, we develop a unified training framework of the alignment function by integrating a large diversity of data sources, resulting in 4.7M training examples from 7 well-established tasks (NLI, QA, paraphrasing, fact verification, information retrieval, semantic similarity, and summarization). We conduct extensive experiments on large-scale benchmarks including 22 evaluation datasets, where 19 of the datasets were never seen in the alignment training. AlignScore achieves substantial improvement over a wide range of previous metrics. Moreover, AlignScore (355M parameters) matches or even outperforms metrics based on ChatGPT and GPT-4 that are orders of magnitude larger.
Reconstruction Task Finds Universal Winning Tickets
Feb 23, 2022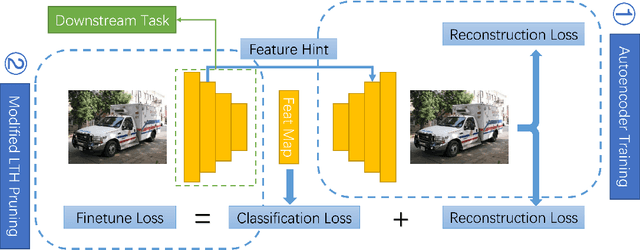
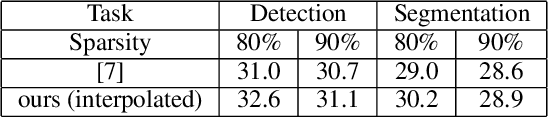
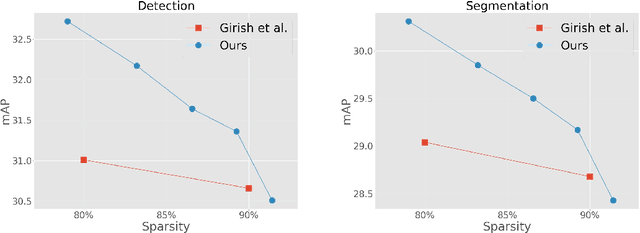
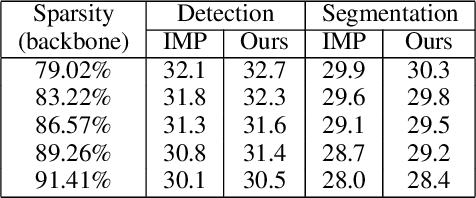
Pruning well-trained neural networks is effective to achieve a promising accuracy-efficiency trade-off in computer vision regimes. However, most of existing pruning algorithms only focus on the classification task defined on the source domain. Different from the strong transferability of the original model, a pruned network is hard to transfer to complicated downstream tasks such as object detection arXiv:arch-ive/2012.04643. In this paper, we show that the image-level pretrain task is not capable of pruning models for diverse downstream tasks. To mitigate this problem, we introduce image reconstruction, a pixel-level task, into the traditional pruning framework. Concretely, an autoencoder is trained based on the original model, and then the pruning process is optimized with both autoencoder and classification losses. The empirical study on benchmark downstream tasks shows that the proposed method can outperform state-of-the-art results explicitly.
MEmoBERT: Pre-training Model with Prompt-based Learning for Multimodal Emotion Recognition
Oct 27, 2021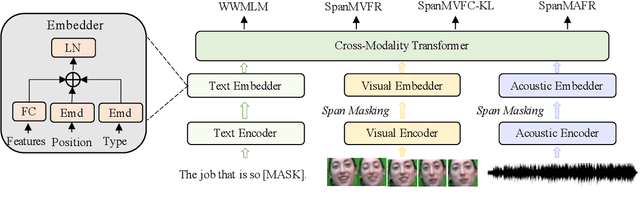

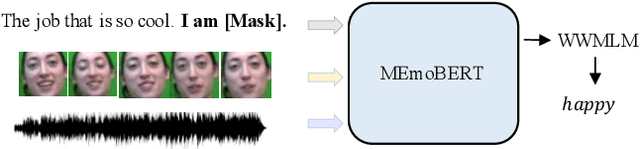
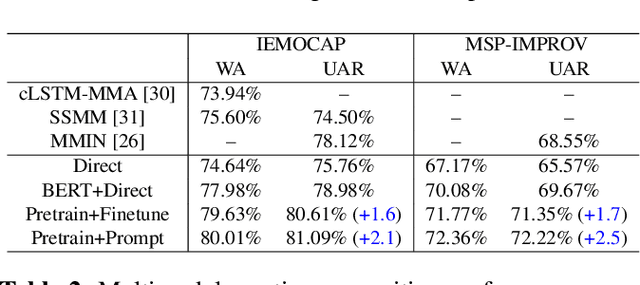
Multimodal emotion recognition study is hindered by the lack of labelled corpora in terms of scale and diversity, due to the high annotation cost and label ambiguity. In this paper, we propose a pre-training model \textbf{MEmoBERT} for multimodal emotion recognition, which learns multimodal joint representations through self-supervised learning from large-scale unlabeled video data that come in sheer volume. Furthermore, unlike the conventional "pre-train, finetune" paradigm, we propose a prompt-based method that reformulates the downstream emotion classification task as a masked text prediction one, bringing the downstream task closer to the pre-training. Extensive experiments on two benchmark datasets, IEMOCAP and MSP-IMPROV, show that our proposed MEmoBERT significantly enhances emotion recognition performance.