 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba-VMR: Multimodal Query Augmentation via Generated Videos for Precise Temporal Grounding
Mar 23, 2026Text-driven video moment retrieval (VMR) remains challenging due to limited capture of hidden temporal dynamics in untrimmed videos, leading to imprecise grounding in long sequences. Traditional methods rely on natural language queries (NLQs) or static image augmentations, overlooking motion sequences and suffering from high computational costs in Transformer-based architectures. Existing approaches fail to integrate subtitle contexts and generated temporal priors effectively, we therefore propose a novel two-stage framework for enhanced temporal grounding. In the first stage, LLM-guided subtitle matching identifies relevant textual cues from video subtitles, fused with the query to generate auxiliary short videos via text-to-video models, capturing implicit motion information as temporal priors. In the second stage, augmented queries are processed through a multi-modal controlled Mamba network, extending text-controlled selection with video-guided gating for efficient fusion of generated priors and long sequences while filtering noise. Our framework is agnostic to base retrieval models and widely applicable for multimodal VMR. Experimental evaluations on the TVR benchmark demonstrate significant improvements over state-of-the-art methods, including reduced computational overhead and higher recall in long-sequence grounding.
Membership Inference on LLMs in the Wild
Jan 16, 2026Membership Inference Attacks (MIAs) act as a crucial auditing tool for the opaque training data of Large Language Models (LLMs). However, existing techniques predominantly rely on inaccessible model internals (e.g., logits) or suffer from poor generalization across domains in strict black-box settings where only generated text is available. In this work, we propose SimMIA, a robust MIA framework tailored for this text-only regime by leveraging an advanced sampling strategy and scoring mechanism. Furthermore, we present WikiMIA-25, a new benchmark curated to evaluate MIA performance on modern proprietary LLMs. Experiments demonstrate that SimMIA achieves state-of-the-art results in the black-box setting, rivaling baselines that exploit internal model information.
Efficient-VLN: A Training-Efficient Vision-Language Navigation Model
Dec 11, 2025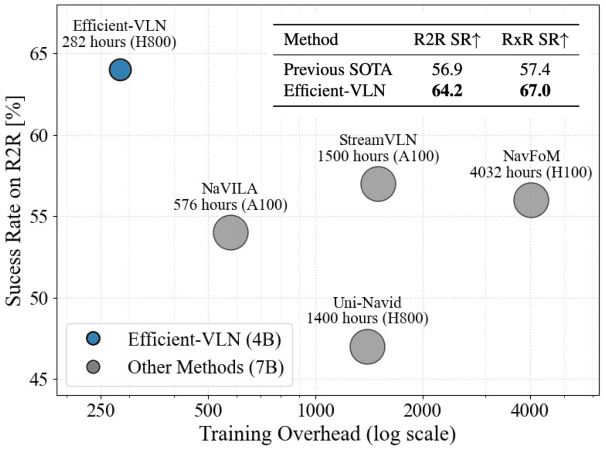
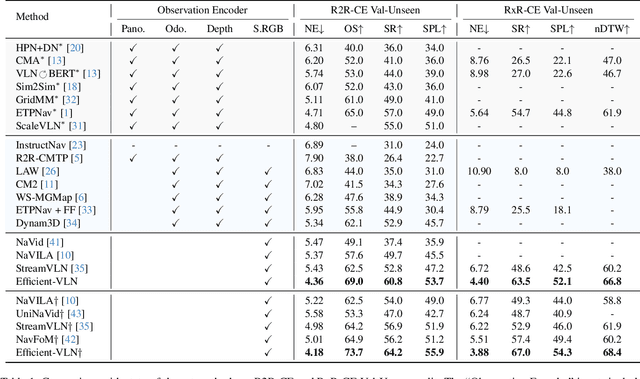
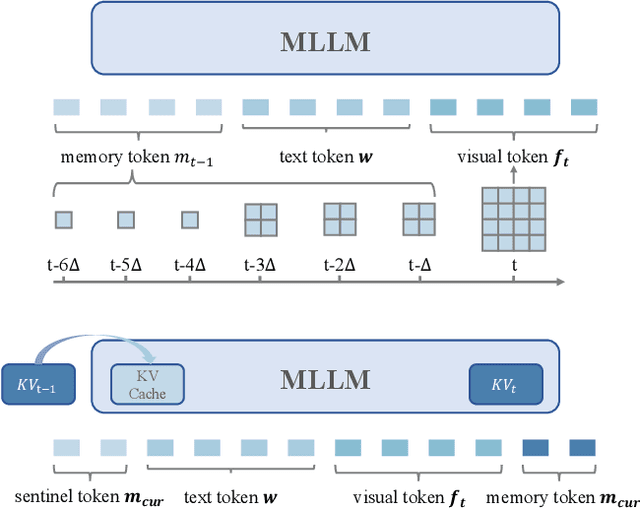
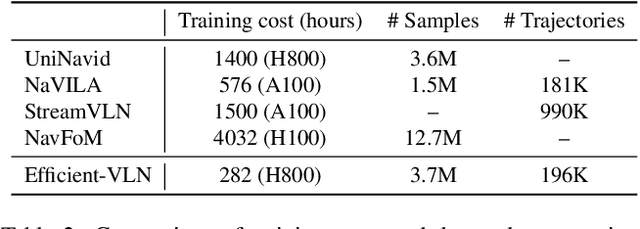
Multimodal large language models (MLLMs) have shown promising potential in Vision-Language Navigation (VLN). However, their practical development is severely hindered by the substantial training overhead. We recognize two key issues that contribute to the overhead: (1) the quadratic computational burden from processing long-horizon historical observations as massive sequences of tokens, and (2) the exploration-efficiency trade-off in DAgger, i.e., a data aggregation process of collecting agent-explored trajectories. While more exploration yields effective error-recovery trajectories for handling test-time distribution shifts, it comes at the cost of longer trajectory lengths for both training and inference. To address these challenges, we propose Efficient-VLN, a training-efficient VLN model. Specifically, to mitigate the token processing burden, we design two efficient memory mechanisms: a progressive memory that dynamically allocates more tokens to recent observations, and a learnable recursive memory that utilizes the key-value cache of learnable tokens as the memory state. Moreover, we introduce a dynamic mixed policy to balance the exploration-efficiency trade-off. Extensive experiments show that Efficient-VLN achieves state-of-the-art performance on R2R-CE (64.2% SR) and RxR-CE (67.0% SR). Critically, our model consumes merely 282 H800 GPU hours, demonstrating a dramatic reduction in training overhead compared to state-of-the-art methods.
Learning from Videos for 3D World: Enhancing MLLMs with 3D Vision Geometry Priors
May 30, 2025Previous research has investigated the application of Multimodal Large Language Models (MLLMs) in understanding 3D scenes by interpreting them as videos. These approaches generally depend on comprehensive 3D data inputs, such as point clouds or reconstructed Bird's-Eye View (BEV) maps. In our research, we advance this field by enhancing the capability of MLLMs to understand and reason in 3D spaces directly from video data, without the need for additional 3D input. We propose a novel and efficient method, the Video-3D Geometry Large Language Model (VG LLM). Our approach employs a 3D visual geometry encoder that extracts 3D prior information from video sequences. This information is integrated with visual tokens and fed into the MLLM. Extensive experiments have shown that our method has achieved substantial improvements in various tasks related to 3D scene understanding and spatial reasoning, all directly learned from video sources. Impressively, our 4B model, which does not rely on explicit 3D data inputs, achieves competitive results compared to existing state-of-the-art methods, and even surpasses the Gemini-1.5-Pro in the VSI-Bench evaluations.
C$^2$LEVA: Toward Comprehensive and Contamination-Free Language Model Evaluation
Dec 06, 2024



Recent advances in large language models (LLMs) have shown significant promise, yet their evaluation raises concerns, particularly regarding data contamination due to the lack of access to proprietary training data. To address this issue, we present C$^2$LEVA, a comprehensive bilingual benchmark featuring systematic contamination prevention. C$^2$LEVA firstly offers a holistic evaluation encompassing 22 tasks, each targeting a specific application or ability of LLMs, and secondly a trustworthy assessment due to our contamination-free tasks, ensured by a systematic contamination prevention strategy that fully automates test data renewal and enforces data protection during benchmark data release. Our large-scale evaluation of 15 open-source and proprietary models demonstrates the effectiveness of C$^2$LEVA.
Making Long-Context Language Models Better Multi-Hop Reasoners
Aug 06, 2024



Recent advancements in long-context modeling have enhanced language models (LMs) for complex tasks across multiple NLP applications. Despite this progress, we find that these models struggle with multi-hop reasoning and exhibit decreased performance in the presence of noisy contexts. In this paper, we introduce Reasoning with Attributions, a novel approach that prompts LMs to supply attributions for each assertion during their reasoning. We validate our approach through experiments on three multi-hop datasets, employing both proprietary and open-source models, and demonstrate its efficacy and resilience. Furthermore, we explore methods to augment reasoning capabilities via fine-tuning and offer an attribution-annotated dataset and a specialized training strategy. Our fine-tuned model achieves competitive performance on multi-hop reasoning benchmarks, closely paralleling proprietary LMs such as ChatGPT and Claude-instant.
VL-PET: Vision-and-Language Parameter-Efficient Tuning via Granularity Control
Aug 18, 2023



As the model size of pre-trained language models (PLMs) grows rapidly, full fine-tuning becomes prohibitively expensive for model training and storage. In vision-and-language (VL), parameter-efficient tuning (PET) techniques are proposed to integrate modular modifications (e.g., Adapter and LoRA) into encoder-decoder PLMs. By tuning a small set of trainable parameters, these techniques perform on par with full fine-tuning. However, excessive modular modifications and neglecting the functionality gap between the encoders and decoders can lead to performance degradation, while existing PET techniques (e.g., VL-Adapter) overlook these critical issues. In this paper, we propose a Vision-and-Language Parameter-Efficient Tuning (VL-PET) framework to impose effective control over modular modifications via a novel granularity-controlled mechanism. Considering different granularity-controlled matrices generated by this mechanism, a variety of model-agnostic VL-PET modules can be instantiated from our framework for better efficiency and effectiveness trade-offs. We further propose lightweight PET module designs to enhance VL alignment and modeling for the encoders and maintain text generation for the decoders. Extensive experiments conducted on four image-text tasks and four video-text tasks demonstrate the efficiency, effectiveness and transferability of our VL-PET framework. In particular, our VL-PET-large with lightweight PET module designs significantly outperforms VL-Adapter by 2.92% (3.41%) and LoRA by 3.37% (7.03%) with BART-base (T5-base) on image-text tasks. Furthermore, we validate the enhanced effect of employing our VL-PET designs on existing PET techniques, enabling them to achieve significant performance improvements. Our code is available at https://github.com/HenryHZY/VL-PET.
CLEVA: Chinese Language Models EVAluation Platform
Aug 09, 2023



With the continuous emergence of Chinese Large Language Models (LLMs), how to evaluate a model's capabilities has become an increasingly significant issue. The absence of a comprehensive Chinese benchmark that thoroughly assesses a model's performance, the unstandardized and incomparable prompting procedure, and the prevalent risk of contamination pose major challenges in the current evaluation of Chinese LLMs. We present CLEVA, a user-friendly platform crafted to holistically evaluate Chinese LLMs. Our platform employs a standardized workflow to assess LLMs' performance across various dimensions, regularly updating a competitive leaderboard. To alleviate contamination, CLEVA curates a significant proportion of new data and develops a sampling strategy that guarantees a unique subset for each leaderboard round. Empowered by an easy-to-use interface that requires just a few mouse clicks and a model API, users can conduct a thorough evaluation with minimal coding. Large-scale experiments featuring 23 influential Chinese LLMs have validated CLEVA's efficacy.
Multi-Path Transformer is Better: A Case Study on Neural Machine Translation
May 10, 2023



For years the model performance in machine learning obeyed a power-law relationship with the model size. For the consideration of parameter efficiency, recent studies focus on increasing model depth rather than width to achieve better performance. In this paper, we study how model width affects the Transformer model through a parameter-efficient multi-path structure. To better fuse features extracted from different paths, we add three additional operations to each sublayer: a normalization at the end of each path, a cheap operation to produce more features, and a learnable weighted mechanism to fuse all features flexibly. Extensive experiments on 12 WMT machine translation tasks show that, with the same number of parameters, the shallower multi-path model can achieve similar or even better performance than the deeper model. It reveals that we should pay more attention to the multi-path structure, and there should be a balance between the model depth and width to train a better large-scale Transformer.
SPRING: Situated Conversation Agent Pretrained with Multimodal Questions from Incremental Layout Graph
Jan 05, 2023



Existing multimodal conversation agents have shown impressive abilities to locate absolute positions or retrieve attributes in simple scenarios, but they fail to perform well when complex relative positions and information alignments are involved, which poses a bottleneck in response quality. In this paper, we propose a Situated Conversation Agent Petrained with Multimodal Questions from INcremental Layout Graph (SPRING) with abilities of reasoning multi-hops spatial relations and connecting them with visual attributes in crowded situated scenarios. Specifically, we design two types of Multimodal Question Answering (MQA) tasks to pretrain the agent. All QA pairs utilized during pretraining are generated from novel Incremental Layout Graphs (ILG). QA pair difficulty labels automatically annotated by ILG are used to promote MQA-based Curriculum Learning. Experimental results verify the SPRING's effectiveness, showing that it significantly outperforms state-of-the-art approaches on both SIMMC 1.0 and SIMMC 2.0 datasets.