 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialWorld: Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks
Jun 08, 2026Spatial reasoning is a foundational capability for multimodal large language models (MLLMs) to perceive and operate within the physical world. However, existing benchmarks predominantly rely on passive evaluation (e.g., static VQA) or simulator-specific pipelines, failing to assess general interactive spatial understanding. We introduce SpatialWorld, a unified benchmark designed specifically for evaluating the interactive spatial understanding of multimodal agents in complex real-world tasks. Integrating eight heterogeneous simulation backends under a shared, simulator-agnostic protocol, SpatialWorld features 760 human-annotated tasks across diverse domains (e.g., household routines, travel, social collaboration). Agents must solve tasks under vision-only partial observability, actively gathering egocentric visual evidence and expressing decisions via a unified, text-based action interface native to MLLMs. For reliable evaluation, each task includes a human-validated initial state, a reference trajectory, and a terminal-state verifier. Evaluating 15 advanced agents reveals that robust spatial task solving remains challenging: the strongest model, GPT-5, achieves an average task success rate (TSR) of only 17.4%, while the leading open-source model, Qwen-3.5, reaches 14.1%. Further analysis exposes a clear mismatch between task success and execution efficiency, alongside substantial domain-specific performance variations. These bottlenecks in active exploration and long-horizon planning position SpatialWorld as a rigorous testbed for future spatial agents.
Thinking with Novel Views: A Systematic Analysis of Generative-Augmented Spatial Intelligence
May 11, 2026Current Large Multimodal Models (LMMs) struggle with spatial reasoning tasks requiring viewpoint-dependent understanding, largely because they are confined to a single, static observation. We propose Thinking with Novel Views (TwNV), a paradigm that integrates generative novel-view synthesis into the reasoning loop: a Reasoner LMM identifies spatial ambiguity, instructs a Painter to synthesize an alternative viewpoint, and re-examines the scene with the additional evidence. Through systematic experiments we address three research questions. (1) Instruction format: numerical camera-pose specifications yield more reliable view control than free-form language. (2) Generation fidelity: synthesized view quality is tightly coupled with downstream spatial accuracy. (3) Inference-time visual scaling: iterative multi-turn view refinement further improves performance, echoing recent scaling trends in language reasoning. Across four spatial subtask categories and four LMM architectures (both closed- and open-source), TwNV consistently improves accuracy by +1.3 to +3.9 pp, with the largest gains on viewpoint-sensitive subtasks. These results establish novel-view generation as a practical lever for advancing spatial intelligence of LMMs.
Awaking Spatial Intelligence in Unified Multimodal Understanding and Generation
May 05, 2026We present JoyAI-Image, a unified multimodal foundation model for visual understanding, text-to-image generation, and instruction-guided image editing. JoyAI-Image couples a spatially enhanced Multimodal Large Language Model (MLLM) with a Multimodal Diffusion Transformer (MMDiT), allowing perception and generation to interact through a shared multimodal interface. Around this architecture, we build a scalable training recipe that combines unified instruction tuning, long-text rendering supervision, spatially grounded data, and both general and spatial editing signals. This design gives the model broad multimodal capability while strengthening geometry-aware reasoning and controllable visual synthesis. Experiments across understanding, generation, long-text rendering, and editing benchmarks show that JoyAI-Image achieves state-of-the-art or highly competitive performance. More importantly, the bidirectional loop between enhanced understanding, controllable spatial editing, and novel-view-assisted reasoning enables the model to move beyond general visual competence toward stronger spatial intelligence. These results suggest a promising path for unified visual models in downstream applications such as vision-language-action systems and world models.
OpenSpatial: A Principled Data Engine for Empowering Spatial Intelligence
Apr 09, 2026Spatial understanding is a fundamental cornerstone of human-level intelligence. Nonetheless, current research predominantly focuses on domain-specific data production, leaving a critical void: the absence of a principled, open-source engine capable of fully unleashing the potential of high-quality spatial data. To bridge this gap, we elucidate the design principles of a robust data generation system and introduce OpenSpatial -- an open-source data engine engineered for high quality, extensive scalability, broad task diversity, and optimized efficiency. OpenSpatial adopts 3D bounding boxes as the fundamental primitive to construct a comprehensive data hierarchy across five foundational tasks: Spatial Measurement (SM), Spatial Relationship (SR), Camera Perception (CP), Multi-view Consistency (MC), and Scene-Aware Reasoning (SAR). Leveraging this scalable infrastructure, we curate OpenSpatial-3M, a large-scale dataset comprising 3 million high-fidelity samples. Extensive evaluations demonstrate that versatile models trained on our dataset achieve state-of-the-art performance across a wide spectrum of spatial reasoning benchmarks. Notably, the best-performing model exhibits a substantial average improvement of 19 percent, relatively. Furthermore, we provide a systematic analysis of how data attributes influence spatial perception. By open-sourcing both the engine and the 3M-scale dataset, we provide a robust foundation to accelerate future research in spatial intelligence.
MC-MoE: Mixture Compressor for Mixture-of-Experts LLMs Gains More
Oct 08, 2024



Mixture-of-Experts large language models (MoE-LLMs) marks a significant step forward of language models, however, they encounter two critical challenges in practice: 1) expert parameters lead to considerable memory consumption and loading latency; and 2) the current activated experts are redundant, as many tokens may only require a single expert. Motivated by these issues, we investigate the MoE-LLMs and make two key observations: a) different experts exhibit varying behaviors on activation reconstruction error, routing scores, and activated frequencies, highlighting their differing importance, and b) not all tokens are equally important -- only a small subset is critical. Building on these insights, we propose MC-MoE, a training-free Mixture-Compressor for MoE-LLMs, which leverages the significance of both experts and tokens to achieve an extreme compression. First, to mitigate storage and loading overheads, we introduce Pre-Loading Mixed-Precision Quantization, which formulates the adaptive bit-width allocation as a Linear Programming problem, where the objective function balances multi-factors reflecting the importance of each expert. Additionally, we develop Online Dynamic Pruning, which identifies important tokens to retain and dynamically select activated experts for other tokens during inference to optimize efficiency while maintaining performance. Our MC-MoE integrates static quantization and dynamic pruning to collaboratively achieve extreme compression for MoE-LLMs with less accuracy loss, ensuring an optimal trade-off between performance and efficiency. Extensive experiments confirm the effectiveness of our approach. For instance, at 2.54 bits, MC-MoE compresses 76.6% of the model, with only a 3.8% average accuracy loss. During dynamic inference, we further reduce activated parameters by 15%, with a performance drop of less than 0.6%.
MarS3D: A Plug-and-Play Motion-Aware Model for Semantic Segmentation on Multi-Scan 3D Point Clouds
Jul 18, 20233D semantic segmentation on multi-scan large-scale point clouds plays an important role in autonomous systems. Unlike the single-scan-based semantic segmentation task, this task requires distinguishing the motion states of points in addition to their semantic categories. However, methods designed for single-scan-based segmentation tasks perform poorly on the multi-scan task due to the lacking of an effective way to integrate temporal information. We propose MarS3D, a plug-and-play motion-aware module for semantic segmentation on multi-scan 3D point clouds. This module can be flexibly combined with single-scan models to allow them to have multi-scan perception abilities. The model encompasses two key designs: the Cross-Frame Feature Embedding module for enriching representation learning and the Motion-Aware Feature Learning module for enhancing motion awareness. Extensive experiments show that MarS3D can improve the performance of the baseline model by a large margin. The code is available at https://github.com/CVMI-Lab/MarS3D.
Prior-free Category-level Pose Estimation with Implicit Space Transformation
Mar 23, 2023



Category-level 6D pose estimation aims to predict the poses and sizes of unseen objects from a specific category. Thanks to prior deformation, which explicitly adapts a category-specific 3D prior (i.e., a 3D template) to a given object instance, prior-based methods attained great success and have become a major research stream. However, obtaining category-specific priors requires collecting a large amount of 3D models, which is labor-consuming and often not accessible in practice. This motivates us to investigate whether priors are necessary to make prior-based methods effective. Our empirical study shows that the 3D prior itself is not the credit to the high performance. The keypoint actually is the explicit deformation process, which aligns camera and world coordinates supervised by world-space 3D models (also called canonical space). Inspired by these observation, we introduce a simple prior-free implicit space transformation network, namely IST-Net, to transform camera-space features to world-space counterparts and build correspondence between them in an implicit manner without relying on 3D priors. Besides, we design camera- and world-space enhancers to enrich the features with pose-sensitive information and geometrical constraints, respectively. Albeit simple, IST-Net becomes the first prior-free method that achieves state-of-the-art performance, with top inference speed on the REAL275 dataset. Our code and models will be publicly available.
Spherical Transformer for LiDAR-based 3D Recognition
Mar 22, 2023



LiDAR-based 3D point cloud recognition has benefited various applications. Without specially considering the LiDAR point distribution, most current methods suffer from information disconnection and limited receptive field, especially for the sparse distant points. In this work, we study the varying-sparsity distribution of LiDAR points and present SphereFormer to directly aggregate information from dense close points to the sparse distant ones. We design radial window self-attention that partitions the space into multiple non-overlapping narrow and long windows. It overcomes the disconnection issue and enlarges the receptive field smoothly and dramatically, which significantly boosts the performance of sparse distant points. Moreover, to fit the narrow and long windows, we propose exponential splitting to yield fine-grained position encoding and dynamic feature selection to increase model representation ability. Notably, our method ranks 1st on both nuScenes and SemanticKITTI semantic segmentation benchmarks with 81.9% and 74.8% mIoU, respectively. Also, we achieve the 3rd place on nuScenes object detection benchmark with 72.8% NDS and 68.5% mAP. Code is available at https://github.com/dvlab-research/SphereFormer.git.
VoxelNeXt: Fully Sparse VoxelNet for 3D Object Detection and Tracking
Mar 20, 2023



3D object detectors usually rely on hand-crafted proxies, e.g., anchors or centers, and translate well-studied 2D frameworks to 3D. Thus, sparse voxel features need to be densified and processed by dense prediction heads, which inevitably costs extra computation. In this paper, we instead propose VoxelNext for fully sparse 3D object detection. Our core insight is to predict objects directly based on sparse voxel features, without relying on hand-crafted proxies. Our strong sparse convolutional network VoxelNeXt detects and tracks 3D objects through voxel features entirely. It is an elegant and efficient framework, with no need for sparse-to-dense conversion or NMS post-processing. Our method achieves a better speed-accuracy trade-off than other mainframe detectors on the nuScenes dataset. For the first time, we show that a fully sparse voxel-based representation works decently for LIDAR 3D object detection and tracking. Extensive experiments on nuScenes, Waymo, and Argoverse2 benchmarks validate the effectiveness of our approach. Without bells and whistles, our model outperforms all existing LIDAR methods on the nuScenes tracking test benchmark.
Spatial Pruned Sparse Convolution for Efficient 3D Object Detection
Sep 28, 2022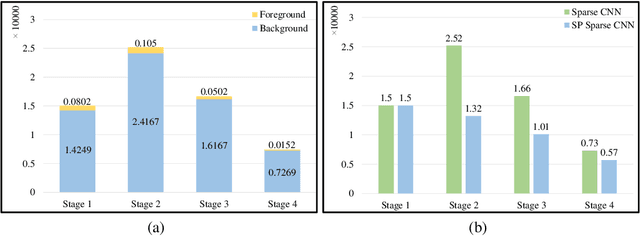
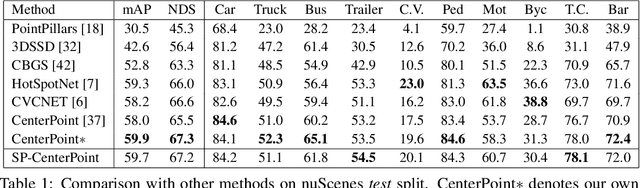
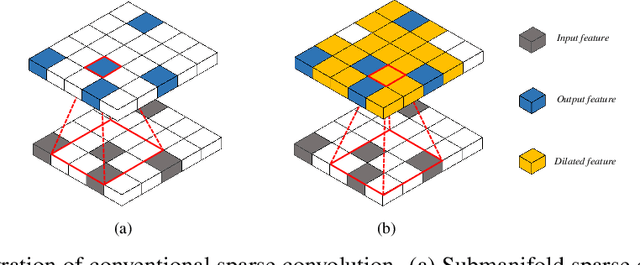

3D scenes are dominated by a large number of background points, which is redundant for the detection task that mainly needs to focus on foreground objects. In this paper, we analyze major components of existing sparse 3D CNNs and find that 3D CNNs ignore the redundancy of data and further amplify it in the down-sampling process, which brings a huge amount of extra and unnecessary computational overhead. Inspired by this, we propose a new convolution operator named spatial pruned sparse convolution (SPS-Conv), which includes two variants, spatial pruned submanifold sparse convolution (SPSS-Conv) and spatial pruned regular sparse convolution (SPRS-Conv), both of which are based on the idea of dynamically determining crucial areas for redundancy reduction. We validate that the magnitude can serve as important cues to determine crucial areas which get rid of the extra computations of learning-based methods. The proposed modules can easily be incorporated into existing sparse 3D CNNs without extra architectural modifications. Extensive experiments on the KITTI, Waymo and nuScenes datasets demonstrate that our method can achieve more than 50% reduction in GFLOPs without compromising the performance.