 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity6K: A Large Open-Domain Evaluation Dataset for Real-World Entity Recognition
Mar 19, 2024



Open-domain real-world entity recognition is essential yet challenging, involving identifying various entities in diverse environments. The lack of a suitable evaluation dataset has been a major obstacle in this field due to the vast number of entities and the extensive human effort required for data curation. We introduce Entity6K, a comprehensive dataset for real-world entity recognition, featuring 5,700 entities across 26 categories, each supported by 5 human-verified images with annotations. Entity6K offers a diverse range of entity names and categorizations, addressing a gap in existing datasets. We conducted benchmarks with existing models on tasks like image captioning, object detection, zero-shot classification, and dense captioning to demonstrate Entity6K's effectiveness in evaluating models' entity recognition capabilities. We believe Entity6K will be a valuable resource for advancing accurate entity recognition in open-domain settings.
StrokeNUWA: Tokenizing Strokes for Vector Graphic Synthesis
Jan 30, 2024To leverage LLMs for visual synthesis, traditional methods convert raster image information into discrete grid tokens through specialized visual modules, while disrupting the model's ability to capture the true semantic representation of visual scenes. This paper posits that an alternative representation of images, vector graphics, can effectively surmount this limitation by enabling a more natural and semantically coherent segmentation of the image information. Thus, we introduce StrokeNUWA, a pioneering work exploring a better visual representation ''stroke tokens'' on vector graphics, which is inherently visual semantics rich, naturally compatible with LLMs, and highly compressed. Equipped with stroke tokens, StrokeNUWA can significantly surpass traditional LLM-based and optimization-based methods across various metrics in the vector graphic generation task. Besides, StrokeNUWA achieves up to a 94x speedup in inference over the speed of prior methods with an exceptional SVG code compression ratio of 6.9%.
Bring Metric Functions into Diffusion Models
Jan 04, 2024



We introduce a Cascaded Diffusion Model (Cas-DM) that improves a Denoising Diffusion Probabilistic Model (DDPM) by effectively incorporating additional metric functions in training. Metric functions such as the LPIPS loss have been proven highly effective in consistency models derived from the score matching. However, for the diffusion counterparts, the methodology and efficacy of adding extra metric functions remain unclear. One major challenge is the mismatch between the noise predicted by a DDPM at each step and the desired clean image that the metric function works well on. To address this problem, we propose Cas-DM, a network architecture that cascades two network modules to effectively apply metric functions to the diffusion model training. The first module, similar to a standard DDPM, learns to predict the added noise and is unaffected by the metric function. The second cascaded module learns to predict the clean image, thereby facilitating the metric function computation. Experiment results show that the proposed diffusion model backbone enables the effective use of the LPIPS loss, leading to state-of-the-art image quality (FID, sFID, IS) on various established benchmarks.
COSMO: COntrastive Streamlined MultimOdal Model with Interleaved Pre-Training
Jan 01, 2024In the evolution of Vision-Language Pre-training, shifting from short-text comprehension to encompassing extended textual contexts is pivotal. Recent autoregressive vision-language models like \cite{flamingo, palme}, leveraging the long-context capability of Large Language Models, have excelled in few-shot text generation tasks but face challenges in alignment tasks. Addressing this gap, we introduce the contrastive loss into text generation models, presenting the COntrastive-Streamlined MultimOdal framework (\ModelName), strategically partitioning the language model into dedicated unimodal text processing and adept multimodal data handling components. \ModelName, our unified framework, merges unimodal and multimodal elements, enhancing model performance for tasks involving textual and visual data while notably reducing learnable parameters. However, these models demand extensive long-text datasets, yet the availability of high-quality long-text video datasets remains limited. To bridge this gap, this work introduces \VideoDatasetName, an inaugural interleaved video-text dataset featuring comprehensive captions, marking a significant step forward. Demonstrating its impact, we illustrate how \VideoDatasetName{} enhances model performance in image-text tasks. With 34% learnable parameters and utilizing 72\% of the available data, our model demonstrates significant superiority over OpenFlamingo~\cite{openflamingo}. For instance, in the 4-shot flickr captioning task, performance notably improves from 57.2% to 65.\%. The contributions of \ModelName{} and \VideoDatasetName{} are underscored by notable performance gains across 14 diverse downstream datasets encompassing both image-text and video-text tasks.
InfoVisDial: An Informative Visual Dialogue Dataset by Bridging Large Multimodal and Language Models
Dec 21, 2023In this paper, we build a visual dialogue dataset, named InfoVisDial, which provides rich informative answers in each round even with external knowledge related to the visual content. Different from existing datasets where the answer is compact and short, InfoVisDial contains long free-form answers with rich information in each round of dialogue. For effective data collection, the key idea is to bridge the large-scale multimodal model (e.g., GIT) and the language models (e.g., GPT-3). GIT can describe the image content even with scene text, while GPT-3 can generate informative dialogue based on the image description and appropriate prompting techniques. With such automatic pipeline, we can readily generate informative visual dialogue data at scale. Then, we ask human annotators to rate the generated dialogues to filter the low-quality conversations.Human analyses show that InfoVisDial covers informative and diverse dialogue topics: $54.4\%$ of the dialogue rounds are related to image scene texts, and $36.7\%$ require external knowledge. Each round's answer is also long and open-ended: $87.3\%$ of answers are unique with an average length of $8.9$, compared with $27.37\%$ and $2.9$ in VisDial. Last, we propose a strong baseline by adapting the GIT model for the visual dialogue task and fine-tune the model on InfoVisDial. Hopefully, our work can motivate more effort on this direction.
Interfacing Foundation Models' Embeddings
Dec 12, 2023



We present FIND, a generalized interface for aligning foundation models' embeddings. As shown in teaser figure, a lightweight transformer interface without tuning any foundation model weights is enough for a unified image (segmentation) and dataset-level (retrieval) understanding. The proposed interface has the following favorable attributes: (1) Generalizable. It applies to various tasks spanning retrieval, segmentation, \textit{etc.}, under the same architecture and weights. (2) Prototypable. Different tasks are able to be implemented through prototyping attention masks and embedding types. (3) Extendable. The proposed interface is adaptive to new tasks, and new models. (4) Interleavable. With the benefit of multi-task multi-modal training, the proposed interface creates an interleaved shared embedding space. In light of the interleaved embedding space, we introduce the FIND-Bench, which introduces new training and evaluation annotations to the COCO dataset for interleave segmentation and retrieval. Our approach achieves state-of-the-art performance on FIND-Bench and competitive performance on standard retrieval and segmentation settings. The training, evaluation, and demo code as well as the dataset have been released at https://github.com/UX-Decoder/FIND.
Segment and Caption Anything
Dec 01, 2023



We propose a method to efficiently equip the Segment Anything Model (SAM) with the ability to generate regional captions. SAM presents strong generalizability to segment anything while is short for semantic understanding. By introducing a lightweight query-based feature mixer, we align the region-specific features with the embedding space of language models for later caption generation. As the number of trainable parameters is small (typically in the order of tens of millions), it costs less computation, less memory usage, and less communication bandwidth, resulting in both fast and scalable training. To address the scarcity problem of regional caption data, we propose to first pre-train our model on objection detection and segmentation tasks. We call this step weak supervision pretraining since the pre-training data only contains category names instead of full-sentence descriptions. The weak supervision pretraining allows us to leverage many publicly available object detection and segmentation datasets. We conduct extensive experiments to demonstrate the superiority of our method and validate each design choice. This work serves as a stepping stone towards scaling up regional captioning data and sheds light on exploring efficient ways to augment SAM with regional semantics. The project page, along with the associated code, can be accessed via the following https://xk-huang.github.io/segment-caption-anything/.
MM-Narrator: Narrating Long-form Videos with Multimodal In-Context Learning
Nov 29, 2023
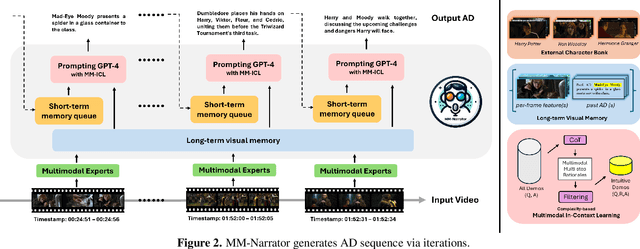


We present MM-Narrator, a novel system leveraging GPT-4 with multimodal in-context learning for the generation of audio descriptions (AD). Unlike previous methods that primarily focused on downstream fine-tuning with short video clips, MM-Narrator excels in generating precise audio descriptions for videos of extensive lengths, even beyond hours, in an autoregressive manner. This capability is made possible by the proposed memory-augmented generation process, which effectively utilizes both the short-term textual context and long-term visual memory through an efficient register-and-recall mechanism. These contextual memories compile pertinent past information, including storylines and character identities, ensuring an accurate tracking and depicting of story-coherent and character-centric audio descriptions. Maintaining the training-free design of MM-Narrator, we further propose a complexity-based demonstration selection strategy to largely enhance its multi-step reasoning capability via few-shot multimodal in-context learning (MM-ICL). Experimental results on MAD-eval dataset demonstrate that MM-Narrator consistently outperforms both the existing fine-tuning-based approaches and LLM-based approaches in most scenarios, as measured by standard evaluation metrics. Additionally, we introduce the first segment-based evaluator for recurrent text generation. Empowered by GPT-4, this evaluator comprehensively reasons and marks AD generation performance in various extendable dimensions.
GPT-4V in Wonderland: Large Multimodal Models for Zero-Shot Smartphone GUI Navigation
Nov 13, 2023



We present MM-Navigator, a GPT-4V-based agent for the smartphone graphical user interface (GUI) navigation task. MM-Navigator can interact with a smartphone screen as human users, and determine subsequent actions to fulfill given instructions. Our findings demonstrate that large multimodal models (LMMs), specifically GPT-4V, excel in zero-shot GUI navigation through its advanced screen interpretation, action reasoning, and precise action localization capabilities. We first benchmark MM-Navigator on our collected iOS screen dataset. According to human assessments, the system exhibited a 91\% accuracy rate in generating reasonable action descriptions and a 75\% accuracy rate in executing the correct actions for single-step instructions on iOS. Additionally, we evaluate the model on a subset of an Android screen navigation dataset, where the model outperforms previous GUI navigators in a zero-shot fashion. Our benchmark and detailed analyses aim to lay a robust groundwork for future research into the GUI navigation task. The project page is at https://github.com/zzxslp/MM-Navigator.
MM-VID: Advancing Video Understanding with GPT-4V
Oct 30, 2023



We present MM-VID, an integrated system that harnesses the capabilities of GPT-4V, combined with specialized tools in vision, audio, and speech, to facilitate advanced video understanding. MM-VID is designed to address the challenges posed by long-form videos and intricate tasks such as reasoning within hour-long content and grasping storylines spanning multiple episodes. MM-VID uses a video-to-script generation with GPT-4V to transcribe multimodal elements into a long textual script. The generated script details character movements, actions, expressions, and dialogues, paving the way for large language models (LLMs) to achieve video understanding. This enables advanced capabilities, including audio description, character identification, and multimodal high-level comprehension. Experimental results demonstrate the effectiveness of MM-VID in handling distinct video genres with various video lengths. Additionally, we showcase its potential when applied to interactive environments, such as video games and graphic user interfaces.