 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior Injection: Preparing Language Models for Reinforcement Learning
May 25, 2025Reinforcement fine-tuning (RFT) has emerged as a powerful post-training technique to incentivize the reasoning ability of large language models (LLMs). However, LLMs can respond very inconsistently to RFT: some show substantial performance gains, while others plateau or even degrade. To understand this divergence, we analyze the per-step influence of the RL objective and identify two key conditions for effective post-training: (1) RL-informative rollout accuracy, and (2) strong data co-influence, which quantifies how much the training data affects performance on other samples. Guided by these insights, we propose behavior injection, a task-agnostic data-augmentation scheme applied prior to RL. Behavior injection enriches the supervised finetuning (SFT) data by seeding exploratory and exploitative behaviors, effectively making the model more RL-ready. We evaluate our method across two reasoning benchmarks with multiple base models. The results demonstrate that our theoretically motivated augmentation can significantly increases the performance gain from RFT over the pre-RL model.
Signal, Image, or Symbolic: Exploring the Best Input Representation for Electrocardiogram-Language Models Through a Unified Framework
May 24, 2025Recent advances have increasingly applied large language models (LLMs) to electrocardiogram (ECG) interpretation, giving rise to Electrocardiogram-Language Models (ELMs). Conditioned on an ECG and a textual query, an ELM autoregressively generates a free-form textual response. Unlike traditional classification-based systems, ELMs emulate expert cardiac electrophysiologists by issuing diagnoses, analyzing waveform morphology, identifying contributing factors, and proposing patient-specific action plans. To realize this potential, researchers are curating instruction-tuning datasets that pair ECGs with textual dialogues and are training ELMs on these resources. Yet before scaling ELMs further, there is a fundamental question yet to be explored: What is the most effective ECG input representation? In recent works, three candidate representations have emerged-raw time-series signals, rendered images, and discretized symbolic sequences. We present the first comprehensive benchmark of these modalities across 6 public datasets and 5 evaluation metrics. We find symbolic representations achieve the greatest number of statistically significant wins over both signal and image inputs. We further ablate the LLM backbone, ECG duration, and token budget, and we evaluate robustness to signal perturbations. We hope that our findings offer clear guidance for selecting input representations when developing the next generation of ELMs.
Feature-EndoGaussian: Feature Distilled Gaussian Splatting in Surgical Deformable Scene Reconstruction
Mar 08, 2025



Minimally invasive surgery (MIS) has transformed clinical practice by reducing recovery times, minimizing complications, and enhancing precision. Nonetheless, MIS inherently relies on indirect visualization and precise instrument control, posing unique challenges. Recent advances in artificial intelligence have enabled real-time surgical scene understanding through techniques such as image classification, object detection, and segmentation, with scene reconstruction emerging as a key element for enhanced intraoperative guidance. Although neural radiance fields (NeRFs) have been explored for this purpose, their substantial data requirements and slow rendering inhibit real-time performance. In contrast, 3D Gaussian Splatting (3DGS) offers a more efficient alternative, achieving state-of-the-art performance in dynamic surgical scene reconstruction. In this work, we introduce Feature-EndoGaussian (FEG), an extension of 3DGS that integrates 2D segmentation cues into 3D rendering to enable real-time semantic and scene reconstruction. By leveraging pretrained segmentation foundation models, FEG incorporates semantic feature distillation within the Gaussian deformation framework, thereby enhancing both reconstruction fidelity and segmentation accuracy. On the EndoNeRF dataset, FEG achieves superior performance (SSIM of 0.97, PSNR of 39.08, and LPIPS of 0.03) compared to leading methods. Additionally, on the EndoVis18 dataset, FEG demonstrates competitive class-wise segmentation metrics while balancing model size and real-time performance.
Safety is Not Only About Refusal: Reasoning-Enhanced Fine-tuning for Interpretable LLM Safety
Mar 06, 2025



Large Language Models (LLMs) are vulnerable to jailbreak attacks that exploit weaknesses in traditional safety alignment, which often relies on rigid refusal heuristics or representation engineering to block harmful outputs. While they are effective for direct adversarial attacks, they fall short of broader safety challenges requiring nuanced, context-aware decision-making. To address this, we propose Reasoning-enhanced Finetuning for interpretable LLM Safety (Rational), a novel framework that trains models to engage in explicit safe reasoning before response. Fine-tuned models leverage the extensive pretraining knowledge in self-generated reasoning to bootstrap their own safety through structured reasoning, internalizing context-sensitive decision-making. Our findings suggest that safety extends beyond refusal, requiring context awareness for more robust, interpretable, and adaptive responses. Reasoning is not only a core capability of LLMs but also a fundamental mechanism for LLM safety. Rational employs reasoning-enhanced fine-tuning, allowing it to reject harmful prompts while providing meaningful and context-aware responses in complex scenarios.
Your Language Model May Think Too Rigidly: Achieving Reasoning Consistency with Symmetry-Enhanced Training
Feb 25, 2025



Large Language Models (LLMs) have demonstrated strong reasoning capabilities across various tasks. However, even minor variations in query phrasing, despite preserving the underlying semantic meaning, can significantly affect their performance. To address this, we focus on enhancing LLMs' awareness of symmetry in query variations and propose syMmetry-ENhanceD (MEND) Data Augmentation, a data-centric approach that improves the model's ability to extract useful information from context. Unlike existing methods that emphasize reasoning chain augmentation, our approach improves model robustness at the knowledge extraction stage through query augmentations, enabling more data-efficient training and stronger generalization to Out-of-Distribution (OOD) settings. Extensive experiments on both logical and arithmetic reasoning tasks show that MEND enhances reasoning performance across diverse query variations, providing new insight into improving LLM robustness through structured dataset curation.
ECG-Byte: A Tokenizer for End-to-End Generative Electrocardiogram Language Modeling
Dec 18, 2024



Large Language Models (LLMs) have shown remarkable adaptability across domains beyond text, specifically electrocardiograms (ECGs). More specifically, there is a growing body of work exploring the task of generating text from a multi-channeled ECG and corresponding textual prompt. Current approaches typically involve pretraining an ECG-specific encoder with a self-supervised learning (SSL) objective and using the features output by the pretrained encoder to finetune a LLM for natural language generation (NLG). However, these methods are limited by 1) inefficiency from two-stage training and 2) interpretability challenges with encoder-generated features. To address these limitations, we introduce ECG-Byte, an adapted byte pair encoding (BPE) tokenizer pipeline for autoregressive language modeling of ECGs. This approach compresses and encodes ECG signals into tokens, enabling end-to-end LLM training by combining ECG and text tokens directly, while being much more interpretable since the ECG tokens can be directly mapped back to the original signal. Using ECG-Byte, we achieve competitive performance in NLG tasks in only half the time and ~48% of the data required by two-stage approaches.
Evaluating Durability: Benchmark Insights into Multimodal Watermarking
Jun 06, 2024



With the development of large models, watermarks are increasingly employed to assert copyright, verify authenticity, or monitor content distribution. As applications become more multimodal, the utility of watermarking techniques becomes even more critical. The effectiveness and reliability of these watermarks largely depend on their robustness to various disturbances. However, the robustness of these watermarks in real-world scenarios, particularly under perturbations and corruption, is not well understood. To highlight the significance of robustness in watermarking techniques, our study evaluated the robustness of watermarked content generated by image and text generation models against common real-world image corruptions and text perturbations. Our results could pave the way for the development of more robust watermarking techniques in the future. Our project website can be found at \url{https://mmwatermark-robustness.github.io/}.
Entity6K: A Large Open-Domain Evaluation Dataset for Real-World Entity Recognition
Mar 19, 2024



Open-domain real-world entity recognition is essential yet challenging, involving identifying various entities in diverse environments. The lack of a suitable evaluation dataset has been a major obstacle in this field due to the vast number of entities and the extensive human effort required for data curation. We introduce Entity6K, a comprehensive dataset for real-world entity recognition, featuring 5,700 entities across 26 categories, each supported by 5 human-verified images with annotations. Entity6K offers a diverse range of entity names and categorizations, addressing a gap in existing datasets. We conducted benchmarks with existing models on tasks like image captioning, object detection, zero-shot classification, and dense captioning to demonstrate Entity6K's effectiveness in evaluating models' entity recognition capabilities. We believe Entity6K will be a valuable resource for advancing accurate entity recognition in open-domain settings.
Embodied Executable Policy Learning with Language-based Scene Summarization
Jun 09, 2023Large Language models (LLMs) have shown remarkable success in assisting robot learning tasks, i.e., complex household planning. However, the performance of pretrained LLMs heavily relies on domain-specific templated text data, which may be infeasible in real-world robot learning tasks with image-based observations. Moreover, existing LLMs with text inputs lack the capability to evolve with non-expert interactions with environments. In this work, we introduce a novel learning paradigm that generates robots' executable actions in the form of text, derived solely from visual observations, using language-based summarization of these observations as the connecting bridge between both domains. Our proposed paradigm stands apart from previous works, which utilized either language instructions or a combination of language and visual data as inputs. Moreover, our method does not require oracle text summarization of the scene, eliminating the need for human involvement in the learning loop, which makes it more practical for real-world robot learning tasks. Our proposed paradigm consists of two modules: the SUM module, which interprets the environment using visual observations and produces a text summary of the scene, and the APM module, which generates executable action policies based on the natural language descriptions provided by the SUM module. We demonstrate that our proposed method can employ two fine-tuning strategies, including imitation learning and reinforcement learning approaches, to adapt to the target test tasks effectively. We conduct extensive experiments involving various SUM/APM model selections, environments, and tasks across 7 house layouts in the VirtualHome environment. Our experimental results demonstrate that our method surpasses existing baselines, confirming the effectiveness of this novel learning paradigm.
MultiSum: A Dataset for Multimodal Summarization and Thumbnail Generation of Videos
Jun 07, 2023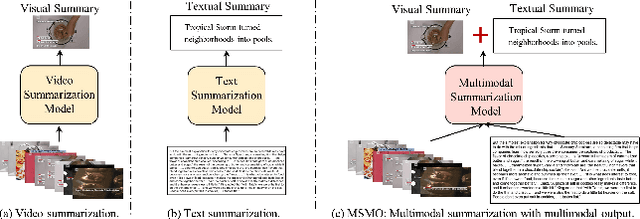
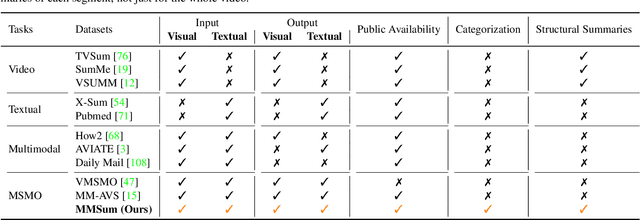
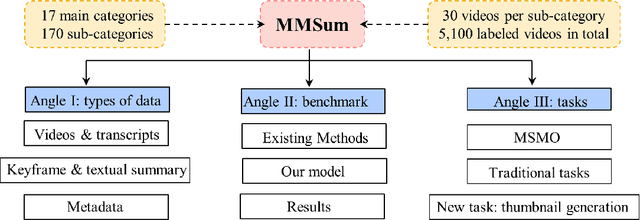
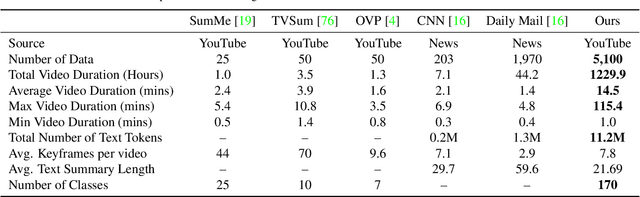
Multimodal summarization with multimodal output (MSMO) has emerged as a promising research direction. Nonetheless, numerous limitations exist within existing public MSMO datasets, including insufficient upkeep, data inaccessibility, limited size, and the absence of proper categorization, which pose significant challenges to effective research. To address these challenges and provide a comprehensive dataset for this new direction, we have meticulously curated the MultiSum dataset. Our new dataset features (1) Human-validated summaries for both video and textual content, providing superior human instruction and labels for multimodal learning. (2) Comprehensively and meticulously arranged categorization, spanning 17 principal categories and 170 subcategories to encapsulate a diverse array of real-world scenarios. (3) Benchmark tests performed on the proposed dataset to assess varied tasks and methods, including video temporal segmentation, video summarization, text summarization, and multimodal summarization. To champion accessibility and collaboration, we release the MultiSum dataset and the data collection tool as fully open-source resources, fostering transparency and accelerating future developments. Our project website can be found at https://multisum-dataset.github.io/.