 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Multimodal LLM with Human Preference: A Survey
Mar 18, 2025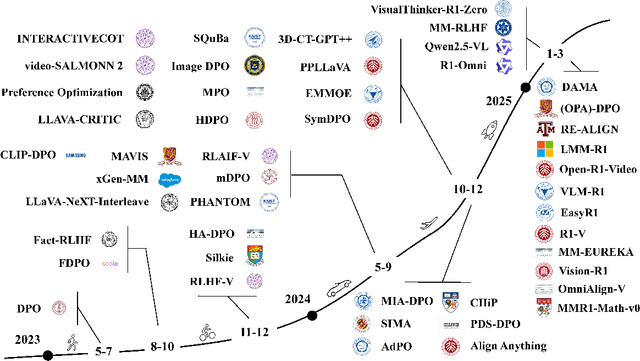
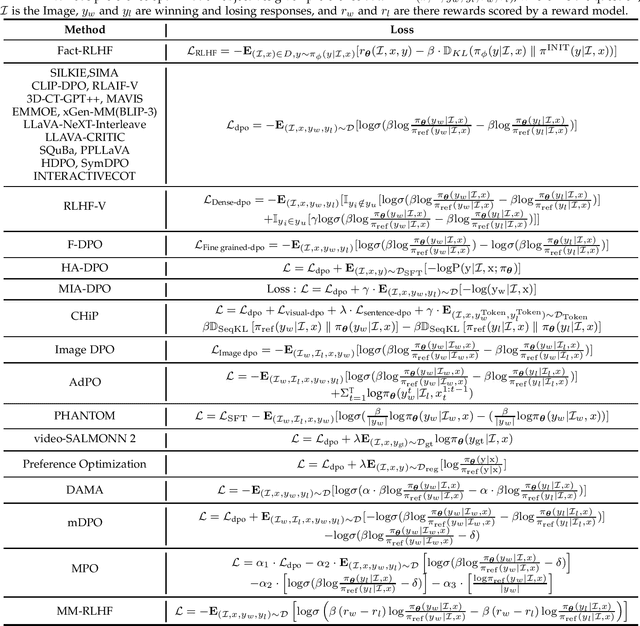
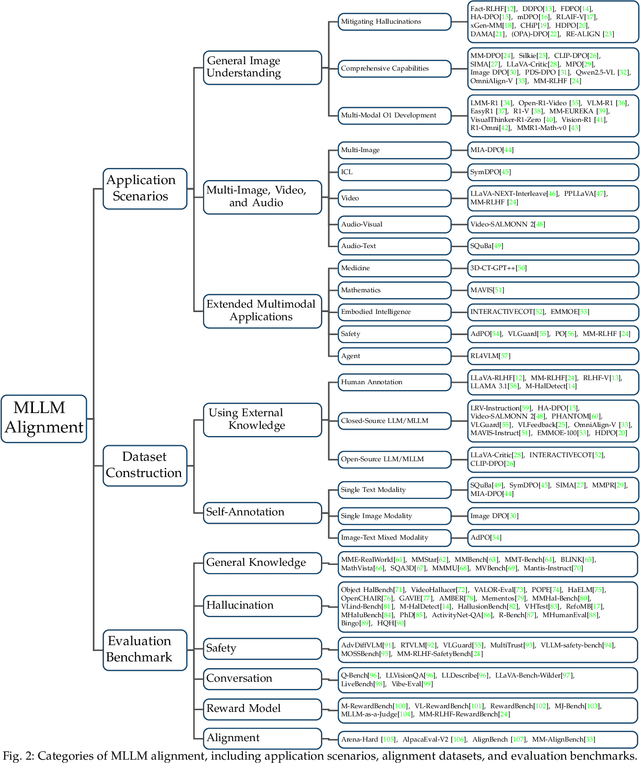

Large language models (LLMs) can handle a wide variety of general tasks with simple prompts, without the need for task-specific training. Multimodal Large Language Models (MLLMs), built upon LLMs, have demonstrated impressive potential in tackling complex tasks involving visual, auditory, and textual data. However, critical issues related to truthfulness, safety, o1-like reasoning, and alignment with human preference remain insufficiently addressed. This gap has spurred the emergence of various alignment algorithms, each targeting different application scenarios and optimization goals. Recent studies have shown that alignment algorithms are a powerful approach to resolving the aforementioned challenges. In this paper, we aim to provide a comprehensive and systematic review of alignment algorithms for MLLMs. Specifically, we explore four key aspects: (1) the application scenarios covered by alignment algorithms, including general image understanding, multi-image, video, and audio, and extended multimodal applications; (2) the core factors in constructing alignment datasets, including data sources, model responses, and preference annotations; (3) the benchmarks used to evaluate alignment algorithms; and (4) a discussion of potential future directions for the development of alignment algorithms. This work seeks to help researchers organize current advancements in the field and inspire better alignment methods. The project page of this paper is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment.
DPC: Dual-Prompt Collaboration for Tuning Vision-Language Models
Mar 17, 2025



The Base-New Trade-off (BNT) problem universally exists during the optimization of CLIP-based prompt tuning, where continuous fine-tuning on base (target) classes leads to a simultaneous decrease of generalization ability on new (unseen) classes. Existing approaches attempt to regulate the prompt tuning process to balance BNT by appending constraints. However, imposed on the same target prompt, these constraints fail to fully avert the mutual exclusivity between the optimization directions for base and new. As a novel solution to this challenge, we propose the plug-and-play Dual-Prompt Collaboration (DPC) framework, the first that decoupling the optimization processes of base and new tasks at the prompt level. Specifically, we clone a learnable parallel prompt based on the backbone prompt, and introduce a variable Weighting-Decoupling framework to independently control the optimization directions of dual prompts specific to base or new tasks, thus avoiding the conflict in generalization. Meanwhile, we propose a Dynamic Hard Negative Optimizer, utilizing dual prompts to construct a more challenging optimization task on base classes for enhancement. For interpretability, we prove the feature channel invariance of the prompt vector during the optimization process, providing theoretical support for the Weighting-Decoupling of DPC. Extensive experiments on multiple backbones demonstrate that DPC can significantly improve base performance without introducing any external knowledge beyond the base classes, while maintaining generalization to new classes. Code is available at: https://github.com/JREion/DPC.
Agents Play Thousands of 3D Video Games
Mar 17, 2025We present PORTAL, a novel framework for developing artificial intelligence agents capable of playing thousands of 3D video games through language-guided policy generation. By transforming decision-making problems into language modeling tasks, our approach leverages large language models (LLMs) to generate behavior trees represented in domain-specific language (DSL). This method eliminates the computational burden associated with traditional reinforcement learning approaches while preserving strategic depth and rapid adaptability. Our framework introduces a hybrid policy structure that combines rule-based nodes with neural network components, enabling both high-level strategic reasoning and precise low-level control. A dual-feedback mechanism incorporating quantitative game metrics and vision-language model analysis facilitates iterative policy improvement at both tactical and strategic levels. The resulting policies are instantaneously deployable, human-interpretable, and capable of generalizing across diverse gaming environments. Experimental results demonstrate PORTAL's effectiveness across thousands of first-person shooter (FPS) games, showcasing significant improvements in development efficiency, policy generalization, and behavior diversity compared to traditional approaches. PORTAL represents a significant advancement in game AI development, offering a practical solution for creating sophisticated agents that can operate across thousands of commercial video games with minimal development overhead. Experiment results on the 3D video games are best viewed on https://zhongwen.one/projects/portal .
Personalized Text Generation with Contrastive Activation Steering
Mar 07, 2025



Personalized text generation aims to infer users' writing style preferences from their historical texts and generate outputs that faithfully reflect these stylistic characteristics. Existing solutions primarily adopt two paradigms: retrieval-augmented generation (RAG) and parameter-efficient fine-tuning (PEFT). While these approaches have advanced the field, they suffer from two critical limitations: (1) the entanglement of content semantics and stylistic patterns in historical texts impedes accurate modeling of user-specific writing preferences; and (2) scalability challenges arising from both RAG's inference latency by retrieval operations and PEFT's parameter storage requirements for per user model. To overcome these limitations, we propose StyleVector, a training-free framework that disentangles and represents personalized writing style as a vector in LLM's activation space, enabling style-steered generation during inference without requiring costly retrieval or parameter storage. Comprehensive experiments demonstrate that our framework achieves a significant 8% relative improvement in personalized generation while reducing storage requirements by 1700 times over PEFT method.
Integrating Protein Dynamics into Structure-Based Drug Design via Full-Atom Stochastic Flows
Mar 06, 2025The dynamic nature of proteins, influenced by ligand interactions, is essential for comprehending protein function and progressing drug discovery. Traditional structure-based drug design (SBDD) approaches typically target binding sites with rigid structures, limiting their practical application in drug development. While molecular dynamics simulation can theoretically capture all the biologically relevant conformations, the transition rate is dictated by the intrinsic energy barrier between them, making the sampling process computationally expensive. To overcome the aforementioned challenges, we propose to use generative modeling for SBDD considering conformational changes of protein pockets. We curate a dataset of apo and multiple holo states of protein-ligand complexes, simulated by molecular dynamics, and propose a full-atom flow model (and a stochastic version), named DynamicFlow, that learns to transform apo pockets and noisy ligands into holo pockets and corresponding 3D ligand molecules. Our method uncovers promising ligand molecules and corresponding holo conformations of pockets. Additionally, the resultant holo-like states provide superior inputs for traditional SBDD approaches, playing a significant role in practical drug discovery.
A Compact Model for Large-Scale Time Series Forecasting
Feb 28, 2025



Spatio-temporal data, which commonly arise in real-world applications such as traffic monitoring, financial transactions, and ride-share demands, represent a special category of multivariate time series. They exhibit two distinct characteristics: high dimensionality and commensurability across spatial locations. These attributes call for computationally efficient modeling approaches and facilitate the use of univariate forecasting models in a channel-independent fashion. SparseTSF, a recently introduced competitive univariate forecasting model, harnesses periodicity to achieve compactness by concentrating on cross-period dynamics, thereby extending the Pareto frontier with respect to model size and predictive performance. Nonetheless, it underperforms on spatio-temporal data due to an inadequate capture of intra-period temporal dependencies. To address this shortcoming, we propose UltraSTF, which integrates a cross-period forecasting module with an ultra-compact shape bank component. Our model effectively detects recurring patterns in time series through the attention mechanism of the shape bank component, thereby strengthening its ability to learn intra-period dynamics. UltraSTF achieves state-of-the-art performance on the LargeST benchmark while employing fewer than 0.2% of the parameters required by the second-best approaches, thus further extending the Pareto frontier of existing methods.
WildLong: Synthesizing Realistic Long-Context Instruction Data at Scale
Feb 23, 2025



Large language models (LLMs) with extended context windows enable tasks requiring extensive information integration but are limited by the scarcity of high-quality, diverse datasets for long-context instruction tuning. Existing data synthesis methods focus narrowly on objectives like fact retrieval and summarization, restricting their generalizability to complex, real-world tasks. WildLong extracts meta-information from real user queries, models co-occurrence relationships via graph-based methods, and employs adaptive generation to produce scalable data. It extends beyond single-document tasks to support multi-document reasoning, such as cross-document comparison and aggregation. Our models, finetuned on 150K instruction-response pairs synthesized using WildLong, surpasses existing open-source long-context-optimized models across benchmarks while maintaining strong performance on short-context tasks without incorporating supplementary short-context data. By generating a more diverse and realistic long-context instruction dataset, WildLong enhances LLMs' ability to generalize to complex, real-world reasoning over long contexts, establishing a new paradigm for long-context data synthesis.
A Survey of Graph Transformers: Architectures, Theories and Applications
Feb 23, 2025



Graph Transformers (GTs) have demonstrated a strong capability in modeling graph structures by addressing the intrinsic limitations of graph neural networks (GNNs), such as over-smoothing and over-squashing. Recent studies have proposed diverse architectures, enhanced explainability, and practical applications for Graph Transformers. In light of these rapid developments, we conduct a comprehensive review of Graph Transformers, covering aspects such as their architectures, theoretical foundations, and applications within this survey. We categorize the architecture of Graph Transformers according to their strategies for processing structural information, including graph tokenization, positional encoding, structure-aware attention and model ensemble. Furthermore, from the theoretical perspective, we examine the expressivity of Graph Transformers in various discussed architectures and contrast them with other advanced graph learning algorithms to discover the connections. Furthermore, we provide a summary of the practical applications where Graph Transformers have been utilized, such as molecule, protein, language, vision traffic, brain and material data. At the end of this survey, we will discuss the current challenges and prospective directions in Graph Transformers for potential future research.
Orchestrating Joint Offloading and Scheduling for Low-Latency Edge SLAM
Feb 23, 2025Visual Simultaneous Localization and Mapping (vSLAM) is a prevailing technology for many emerging robotic applications. Achieving real-time SLAM on mobile robotic systems with limited computational resources is challenging because the complexity of SLAM algorithms increases over time. This restriction can be lifted by offloading computations to edge servers, forming the emerging paradigm of edge-assisted SLAM. Nevertheless, the exogenous and stochastic input processes affect the dynamics of the edge-assisted SLAM system. Moreover, the requirements of clients on SLAM metrics change over time, exerting implicit and time-varying effects on the system. In this paper, we aim to push the limit beyond existing edge-assist SLAM by proposing a new architecture that can handle the input-driven processes and also satisfy clients' implicit and time-varying requirements. The key innovations of our work involve a regional feature prediction method for importance-aware local data processing, a configuration adaptation policy that integrates data compression/decompression and task offloading, and an input-dependent learning framework for task scheduling with constraint satisfaction. Extensive experiments prove that our architecture improves pose estimation accuracy and saves up to 47% of communication costs compared with a popular edge-assisted SLAM system, as well as effectively satisfies the clients' requirements.
MolSpectra: Pre-training 3D Molecular Representation with Multi-modal Energy Spectra
Feb 22, 2025Establishing the relationship between 3D structures and the energy states of molecular systems has proven to be a promising approach for learning 3D molecular representations. However, existing methods are limited to modeling the molecular energy states from classical mechanics. This limitation results in a significant oversight of quantum mechanical effects, such as quantized (discrete) energy level structures, which offer a more accurate estimation of molecular energy and can be experimentally measured through energy spectra. In this paper, we propose to utilize the energy spectra to enhance the pre-training of 3D molecular representations (MolSpectra), thereby infusing the knowledge of quantum mechanics into the molecular representations. Specifically, we propose SpecFormer, a multi-spectrum encoder for encoding molecular spectra via masked patch reconstruction. By further aligning outputs from the 3D encoder and spectrum encoder using a contrastive objective, we enhance the 3D encoder's understanding of molecules. Evaluations on public benchmarks reveal that our pre-trained representations surpass existing methods in predicting molecular properties and modeling dynamics.