 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Uniform Token-Level Trust Region in LLM Reinforcement Learning
Jun 09, 2026Reinforcement learning with verifiable rewards (RLVR) has become standard for improving LLM reasoning. However, existing PPO-style trust-region mechanisms remain position-agnostic by enforcing uniform thresholds across all tokens independently. This pointwise treatment conflicts with autoregressive generation in two critical ways. First, uniform thresholds ignore autoregressive asymmetry. Early-stage deviations produce compounding sequence-level drift, causing static thresholds to under-regulate early divergence and excessively constrain late-stage exploration. Second, evaluating token-level divergence in isolation overlooks cumulative prefix drift, granting the same divergence allowance regardless of how far the conditioning history has already deviated from the rollout policy. To address this limitation, we propose CPPO (Cumulative Prefix-divergence Policy Optimization), a token-level masking rule that aligns updates with a finite-horizon policy-improvement bound via two coupled mechanisms. First, a position-weighted threshold imposes stricter limits at early positions whose effects persist longer, relaxing constraints for late-stage tokens. Second, a cumulative prefix budget tracks historical deviations, dynamically restricting further token-level deviation to prevent compounding errors along the prefix. Empirically, CPPO enhances training stability and significantly improves reasoning accuracy across various model scales.
Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
Jun 09, 2026Recent work has demonstrated that online reinforcement learning (RL) can substantially improve the quality and alignment of flow matching models for image and video generation. Methods such as Flow-GRPO and CPS cast the denoising process as a Markov Decision Process and apply PPO-style ratio clipping to enforce a trust region. However, we argue that ratio clipping is structurally ill-suited for flow models: the probability ratio between new and old policies is a noisy, single-sample estimate of the true policy divergence, leading to over-constraining in some regions of the trajectory and under-constraining in others. We propose Flow-DPPO (Flow Divergence Proximal Policy Optimization), which replaces ratio clipping with a divergence proximal constraint. A key observation is that the per-step policy in flow models is Gaussian, enabling exact and cheap computation of the KL divergence between old and new policies. Flow-DPPO employs an asymmetric divergence mask that blocks gradient updates only when they simultaneously move away from the trusted region and violate the divergence threshold. Experiments show that Flow-DPPO achieves higher rewards with better KL-proximal efficiency, alleviates catastrophic forgetting, promotes balanced multi-objective optimization, and enables stable multi-epoch training where ratio clipping degrades. Code and models are available at https://github.com/Tencent-Hunyuan/UniRL/tree/main/FlowDPPO.
Exploring the Design Space of Reward Backpropagation for Flow Matching
Jun 09, 2026Aligning text-to-image flow matching models with human preferences via direct reward backpropagation is sample-efficient but hampered by two well-known pathologies: activations cannot be stored across the full sampling trajectory at modern model scale, and chained Jacobian products across steps inflate the reward gradient as it travels back to early indices. Connector-based methods, such as LeapAlign, address these issues by replacing the full backward trajectory with a short pinned path, highlighting a useful decoupling between sampling and optimization. However, the quality of the resulting gradient depends on how accurately this short path approximates the full rollout, especially over long intervals. We propose FlowBP, a unified surrogate-trajectory framework that treats the backward trajectory itself as the design object. FlowBP keeps a no-gradient cached rollout for sampling, then builds a lightweight backward surrogate from cached and selectively re-forwarded velocities. This view separates four choices: the reward-model input, active set, integration weights, and bridge coupling, and recovers prior direct-gradient methods as particular settings. Within this framework, we instantiate three variants: FlowBP-Sparse uses sparse Euler reconstruction, FlowBP-Bridge adds controlled bridge coupling, and FlowBP-Lagrange raises the order of leap quadrature. All three bound memory by the active-set size and limit gradient chaining to at most one Jacobian factor. Across SD3.5-M, FLUX.1-dev, and FLUX.2-Klein-base on preference, quality, and compositional metrics, the three variants improve over direct-gradient baselines on most metrics.
Rethinking the Divergence Regularization in LLM RL
Jun 08, 2026Reinforcement learning (RL) has become a key component of post-training large language models (LLMs). In practice, LLM RL is often off-policy because of training-inference mismatch and policy staleness, making trust-region control essential for stable optimization. Mainstream methods such as PPO and GRPO approximate this control with a ratio-clipping mechanism, but the importance ratio can be a poor proxy for distributional shift in long-tailed vocabularies. Recent work such as DPPO addresses this mismatch by replacing ratio-based clipping with a divergence-based mask, yielding a trust region defined by the sampled token's absolute probability shift. However, DPPO still relies on a hard mask: once a token crosses the trust-region boundary in a harmful direction, its gradient is discarded rather than corrected. To address this, we propose Divergence Regularized Policy Optimization (DRPO), which replaces the hard mask with a smooth advantage-weighted quadratic regularizer on policy shift. DRPO preserves the same trust-region geometry as DPPO while inducing bounded, continuous gradient weights that attenuate diverging updates and provide corrective signals beyond the boundary. Experiments across model scales, architectures, and precision settings show that DRPO improves the stability and efficiency of LLM RL training.
Reinforcing Few-step Generators via Reward-Tilted Distribution Matching
May 28, 2026Recent advances in few-step diffusion distillation have enabled efficient image generation, yet aligning these models with human preferences remains challenging. We propose Reward-Tilted Distribution Matching Distillation (RTDMD), a two-stage framework that unifies distribution matching distillation with reward-guided reinforcement learning for few-step flow generators. We show that minimizing the KL divergence to a reward-tilted teacher distribution naturally decomposes into a distribution matching term and a reward maximization term. In the first stage, we introduce Ambient-Consistent Distribution Matching Distillation (AC-DMD), which performs subinterval-wise distribution matching and augments the fake score objective with a consistency regularizer to help the fake score model track the shifting generator distribution under limited updates. In the second stage, we jointly optimize both terms: for the reward maximization term, we derive a hybrid policy gradient that combines a GRPO-style estimator for the stochastic intermediate transitions with direct reward backpropagation through the deterministic final step, and further introduce step-subset GRPO (SubGRPO) to reduce variance. Experiments on SD3, SD3.5, and FLUX.2 demonstrate that RTDMD establishes new state-of-the-art results across preference, aesthetic, and compositional metrics with only 4 inference steps, outperforming previous few-step text-to-image generation methods. Code and models are available at https://github.com/Harahan/RTDMD.
h-MINT: Modeling Pocket-Ligand Binding with Hierarchical Molecular Interaction Network
Apr 25, 2026Accurate molecular representations are critical for drug discovery, and a central challenge lies in capturing the chemical environment of molecular fragments, as key interactions, such as H-bond and π stacking, occur only under specific local conditions. Most existing approaches represent molecules as atom-level graphs; however, atom-level representations can hardly express higher-order chemical context (e.g., stereochemistry, lone pairs, conjugation). Fragment-based methods (e.g., principal subgraph, predefined functional groups) fail to preserve essential information such as chirality, aromaticity, and ionic states. This work addresses these limitations from two aspects. (i) OverlapBPE tokenization. We propose a novel data-driven molecule tokenization method. Unlike existing approaches, our method allows overlapping fragments, reflecting the inherently fuzzy boundaries of small-molecule substructures and, together with enriched chemical information at the token level, thereby preserving a more complete chemical context. (ii) h-MINT model. OverlapBPE induces many-to-many atom-fragment mappings, which necessitate a new hierarchical architecture. We therefore develop a hierarchical molecular interaction network capable of jointly modeling interactions at both atom and fragment levels. By supporting fragment overlaps, the model naturally accommodates the many-to-many atom-fragment mappings introduced by the OverlapBPE scheme. Extensive evaluation against state-of-the-art methods shows our method improves binding affinity prediction by 2-4% Pearson/Spearman correlation on PDBBind and LBA, enhances virtual screening by 1-3% in key metrics on DUD-E and LIT-PCBA, and achieves the best overall HTS performance on PubChem assays. Further analysis demonstrates that our method effectively captures interactive information while maintaining good generalization.
Rethinking the Trust Region in LLM Reinforcement Learning
Feb 04, 2026Reinforcement learning (RL) has become a cornerstone for fine-tuning Large Language Models (LLMs), with Proximal Policy Optimization (PPO) serving as the de facto standard algorithm. Despite its ubiquity, we argue that the core ratio clipping mechanism in PPO is structurally ill-suited for the large vocabularies inherent to LLMs. PPO constrains policy updates based on the probability ratio of sampled tokens, which serves as a noisy single-sample Monte Carlo estimate of the true policy divergence. This creates a sub-optimal learning dynamic: updates to low-probability tokens are aggressively over-penalized, while potentially catastrophic shifts in high-probability tokens are under-constrained, leading to training inefficiency and instability. To address this, we propose Divergence Proximal Policy Optimization (DPPO), which substitutes heuristic clipping with a more principled constraint based on a direct estimate of policy divergence (e.g., Total Variation or KL). To avoid huge memory footprint, we introduce the efficient Binary and Top-K approximations to capture the essential divergence with negligible overhead. Extensive empirical evaluations demonstrate that DPPO achieves superior training stability and efficiency compared to existing methods, offering a more robust foundation for RL-based LLM fine-tuning.
Defeating the Training-Inference Mismatch via FP16
Oct 30, 2025Reinforcement learning (RL) fine-tuning of large language models (LLMs) often suffers from instability due to the numerical mismatch between the training and inference policies. While prior work has attempted to mitigate this issue through algorithmic corrections or engineering alignments, we show that its root cause lies in the floating point precision itself. The widely adopted BF16, despite its large dynamic range, introduces large rounding errors that breaks the consistency between training and inference. In this work, we demonstrate that simply reverting to \textbf{FP16} effectively eliminates this mismatch. The change is simple, fully supported by modern frameworks with only a few lines of code change, and requires no modification to the model architecture or learning algorithm. Our results suggest that using FP16 uniformly yields more stable optimization, faster convergence, and stronger performance across diverse tasks, algorithms and frameworks. We hope these findings motivate a broader reconsideration of precision trade-offs in RL fine-tuning.
Variational Reasoning for Language Models
Sep 26, 2025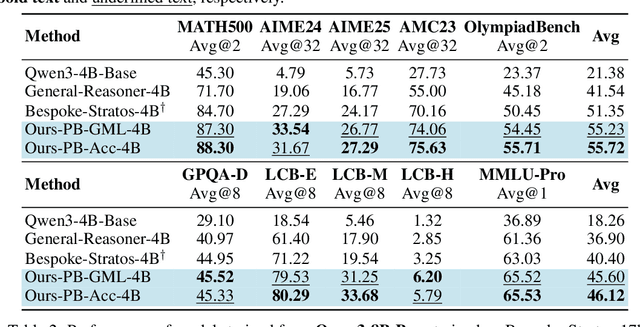
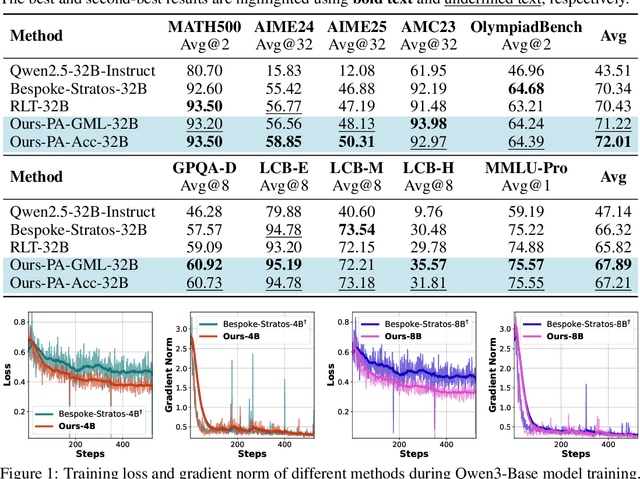
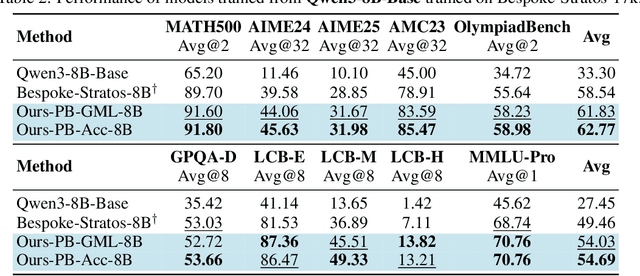
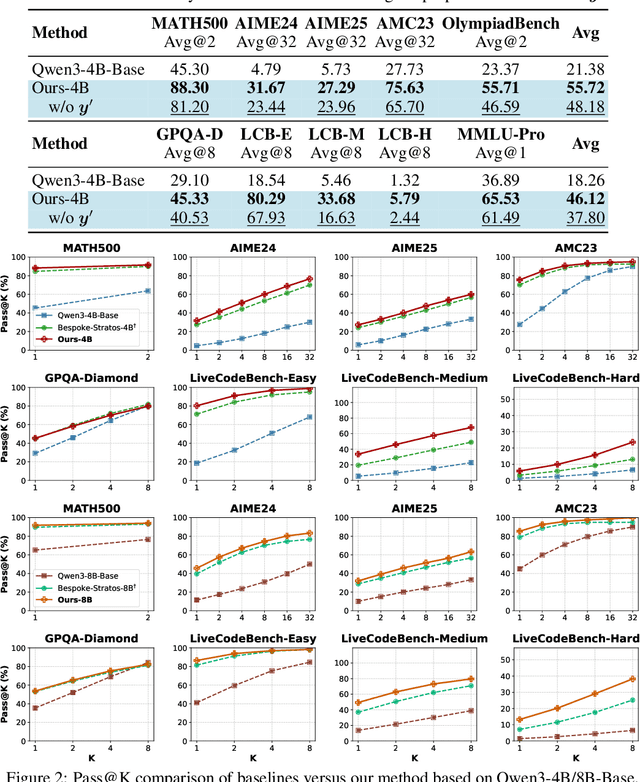
We introduce a variational reasoning framework for language models that treats thinking traces as latent variables and optimizes them through variational inference. Starting from the evidence lower bound (ELBO), we extend it to a multi-trace objective for tighter bounds and propose a forward-KL formulation that stabilizes the training of the variational posterior. We further show that rejection sampling finetuning and binary-reward RL, including GRPO, can be interpreted as local forward-KL objectives, where an implicit weighting by model accuracy naturally arises from the derivation and reveals a previously unnoticed bias toward easier questions. We empirically validate our method on the Qwen 2.5 and Qwen 3 model families across a wide range of reasoning tasks. Overall, our work provides a principled probabilistic perspective that unifies variational inference with RL-style methods and yields stable objectives for improving the reasoning ability of language models. Our code is available at https://github.com/sail-sg/variational-reasoning.
ChemBOMAS: Accelerated BO in Chemistry with LLM-Enhanced Multi-Agent System
Sep 10, 2025The efficiency of Bayesian optimization (BO) in chemistry is often hindered by sparse experimental data and complex reaction mechanisms. To overcome these limitations, we introduce ChemBOMAS, a new framework named LLM-Enhanced Multi-Agent System for accelerating BO in chemistry. ChemBOMAS's optimization process is enhanced by LLMs and synergistically employs two strategies: knowledge-driven coarse-grained optimization and data-driven fine-grained optimization. First, in the knowledge-driven coarse-grained optimization stage, LLMs intelligently decompose the vast search space by reasoning over existing chemical knowledge to identify promising candidate regions. Subsequently, in the data-driven fine-grained optimization stage, LLMs enhance the BO process within these candidate regions by generating pseudo-data points, thereby improving data utilization efficiency and accelerating convergence. Benchmark evaluations** further confirm that ChemBOMAS significantly enhances optimization effectiveness and efficiency compared to various BO algorithms. Importantly, the practical utility of ChemBOMAS was validated through wet-lab experiments conducted under pharmaceutical industry protocols, targeting conditional optimization for a previously unreported and challenging chemical reaction. In the wet experiment, ChemBOMAS achieved an optimal objective value of 96%. This was substantially higher than the 15% achieved by domain experts. This real-world success, together with strong performance on benchmark evaluations, highlights ChemBOMAS as a powerful tool to accelerate chemical discovery.