 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Effect Memory Pretraining for Robot Manipulation
Jun 10, 2026We present AEM, an Action-Effect Memory pretraining framework for robot manipulation that learns compact temporal representations from vision-action history. Unlike prior robot representation pretraining methods that mainly focus on single-frame visual encoding, AEM targets the temporal nature of manipulation, where the current observation alone is often insufficient under partial observability. AEM models manipulation as an action-driven interaction process by interleaving visual and action features and applying masked modeling to recover missing content from incomplete histories, thereby learning action-conditioned state evolution. The Mamba-encoded output of the final vision token is used as a compact history representation, serving as the global context for decoding and downstream control. This design preserves a single-vector temporal bottleneck while keeping inference efficient. We evaluate AEM with Diffusion Policy and Flow Policy. AEM consistently improves manipulation performance in both simulation and real-world settings, outperforming baselines across clean scenes, cluttered and random scenes, and non-Markovian tasks. Ablation studies further show that history-aware pretraining surpasses single-frame pretraining and direct frame stacking, while reducing inference latency and computational cost.
Online Skill Learning for Web Agents via State-Grounded Dynamic Retrieval
Jun 03, 2026Language agents increasingly rely on reusable skills to improve multi-step web automation across related tasks. A growing line of work studies online skill learning, where agents continually induce skills from previous task trajectories and reuse them in future tasks on the fly. However, existing methods mainly reuse skills at the task-level: a fixed set of skills is retrieved based on the initial task instruction and then held fixed throughout execution. This static strategy is misaligned with web execution, where the appropriate next action depends not only on the task goal but also on the current webpage state, which often transitions into situations that the initial skills fail to cover. To address this gap, we propose State-Grounded Dynamic Retrieval (SGDR), an online skill learning method that enables stepwise skill reuse for web agents. SGDR consists of three components: a sliding-window extraction process that turns completed trajectories into reusable sub-procedures invokable at intermediate execution states, a dual text-code representation that connects skill retrieval with executable action, and a state-grounded dynamic retrieval mechanism that matches skills to both the task goal and the current webpage state. Experiments on WebArena across five domains show that SGDR consistently outperforms strong baselines, achieving average success rates of 37.5% with GPT-4.1 and 24.3% with Qwen3-4B, corresponding to relative gains of 10.6% and 10.0% over the strongest baseline, respectively. The code is available at https://github.com/plusnli/skill-dynamic-retrieval.
ELAS: Efficient Pre-Training of Low-Rank Large Language Models via 2:4 Activation Sparsity
May 05, 2026Large Language Models (LLMs) have achieved remarkable capabilities, but their immense computational demands during training remain a critical bottleneck for widespread adoption. Low-rank training has received attention in recent years due to its ability to significantly reduce training memory usage. Meanwhile, applying 2:4 structured sparsity to weights and activations to leverage NVIDIA GPU support for 2:4 structured sparse format has become a promising direction. However, existing low-rank methods often leave activation matrices in full-rank, which dominates memory consumption and limits throughput during large-batch training. Furthermore, directly applying sparsity to weights often leads to non-negligible performance degradation. To achieve efficient pre-training of LLMs, this paper proposes ELAS: Efficient pre-training of Low-rank LLMs via 2:4 Activation Sparsity, a novel framework for low-rank models via 2:4 activation sparsity. ELAS applies squared ReLU activation functions to the feed-forward networks in low-rank models and implements 2:4 structured sparsity on the activations after the squared ReLU operation. We evaluated ELAS through pre-training experiments on LLaMA models ranging from 60M to 1B parameters. The results demonstrate that ELAS maintains performance with minimal degradation after applying 2:4 activation sparsity, while achieving training and inference acceleration. Moreover, ELAS reduces activation memory overhead, particularly with large batch sizes. Code is available at ELAS Repo.
Building a Precise Video Language with Human-AI Oversight
Apr 22, 2026Video-language models (VLMs) learn to reason about the dynamic visual world through natural language. We introduce a suite of open datasets, benchmarks, and recipes for scalable oversight that enable precise video captioning. First, we define a structured specification for describing subjects, scenes, motion, spatial, and camera dynamics, grounded by hundreds of carefully defined visual primitives developed with professional video creators such as filmmakers. Next, to curate high-quality captions, we introduce CHAI (Critique-based Human-AI Oversight), a framework where trained experts critique and revise model-generated pre-captions into improved post-captions. This division of labor improves annotation accuracy and efficiency by offloading text generation to models, allowing humans to better focus on verification. Additionally, these critiques and preferences between pre- and post-captions provide rich supervision for improving open-source models (Qwen3-VL) on caption generation, reward modeling, and critique generation through SFT, DPO, and inference-time scaling. Our ablations show that critique quality in precision, recall, and constructiveness, ensured by our oversight framework, directly governs downstream performance. With modest expert supervision, the resulting model outperforms closed-source models such as Gemini-3.1-Pro. Finally, we apply our approach to re-caption large-scale professional videos (e.g., films, commercials, games) and fine-tune video generation models such as Wan to better follow detailed prompts of up to 400 words, achieving finer control over cinematography including camera motion, angle, lens, focus, point of view, and framing. Our results show that precise specification and human-AI oversight are key to professional-level video understanding and generation. Data and code are available on our project page: https://linzhiqiu.github.io/papers/chai/
MOVA: Towards Scalable and Synchronized Video-Audio Generation
Feb 09, 2026Audio is indispensable for real-world video, yet generation models have largely overlooked audio components. Current approaches to producing audio-visual content often rely on cascaded pipelines, which increase cost, accumulate errors, and degrade overall quality. While systems such as Veo 3 and Sora 2 emphasize the value of simultaneous generation, joint multimodal modeling introduces unique challenges in architecture, data, and training. Moreover, the closed-source nature of existing systems limits progress in the field. In this work, we introduce MOVA (MOSS Video and Audio), an open-source model capable of generating high-quality, synchronized audio-visual content, including realistic lip-synced speech, environment-aware sound effects, and content-aligned music. MOVA employs a Mixture-of-Experts (MoE) architecture, with a total of 32B parameters, of which 18B are active during inference. It supports IT2VA (Image-Text to Video-Audio) generation task. By releasing the model weights and code, we aim to advance research and foster a vibrant community of creators. The released codebase features comprehensive support for efficient inference, LoRA fine-tuning, and prompt enhancement.
Automating Expert-Level Medical Reasoning Evaluation of Large Language Models
Jul 10, 2025As large language models (LLMs) become increasingly integrated into clinical decision-making, ensuring transparent and trustworthy reasoning is essential. However, existing evaluation strategies of LLMs' medical reasoning capability either suffer from unsatisfactory assessment or poor scalability, and a rigorous benchmark remains lacking. To address this, we introduce MedThink-Bench, a benchmark designed for rigorous, explainable, and scalable assessment of LLMs' medical reasoning. MedThink-Bench comprises 500 challenging questions across ten medical domains, each annotated with expert-crafted step-by-step rationales. Building on this, we propose LLM-w-Ref, a novel evaluation framework that leverages fine-grained rationales and LLM-as-a-Judge mechanisms to assess intermediate reasoning with expert-level fidelity while maintaining scalability. Experiments show that LLM-w-Ref exhibits a strong positive correlation with expert judgments. Benchmarking twelve state-of-the-art LLMs, we find that smaller models (e.g., MedGemma-27B) can surpass larger proprietary counterparts (e.g., OpenAI-o3). Overall, MedThink-Bench offers a foundational tool for evaluating LLMs' medical reasoning, advancing their safe and responsible deployment in clinical practice.
Mitigating Hallucination Through Theory-Consistent Symmetric Multimodal Preference Optimization
Jun 13, 2025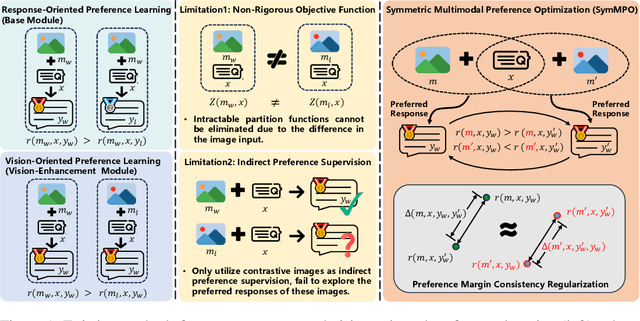


Direct Preference Optimization (DPO) has emerged as an effective approach for mitigating hallucination in Multimodal Large Language Models (MLLMs). Although existing methods have achieved significant progress by utilizing vision-oriented contrastive objectives for enhancing MLLMs' attention to visual inputs and hence reducing hallucination, they suffer from non-rigorous optimization objective function and indirect preference supervision. To address these limitations, we propose a Symmetric Multimodal Preference Optimization (SymMPO), which conducts symmetric preference learning with direct preference supervision (i.e., response pairs) for visual understanding enhancement, while maintaining rigorous theoretical alignment with standard DPO. In addition to conventional ordinal preference learning, SymMPO introduces a preference margin consistency loss to quantitatively regulate the preference gap between symmetric preference pairs. Comprehensive evaluation across five benchmarks demonstrate SymMPO's superior performance, validating its effectiveness in hallucination mitigation of MLLMs.
Through the Valley: Path to Effective Long CoT Training for Small Language Models
Jun 09, 2025Long chain-of-thought (CoT) supervision has become a common strategy to enhance reasoning in language models. While effective for large models, we identify a phenomenon we call Long CoT Degradation, in which small language models (SLMs; <=3B parameters) trained on limited long CoT data experience significant performance deterioration. Through extensive experiments on the Qwen2.5, LLaMA3 and Gemma3 families, we demonstrate that this degradation is widespread across SLMs. In some settings, models trained on only 8k long CoT examples lose up to 75% of their original performance before fine-tuning. Strikingly, we further observe that for some particularly small models, even training on 220k long CoT examples fails to recover or surpass their original performance prior to fine-tuning. Our analysis attributes this effect to error accumulation: while longer responses increase the capacity for multi-step reasoning, they also amplify the risk of compounding mistakes. Furthermore, we find that Long CoT Degradation may negatively impacts downstream reinforcement learning (RL), although this can be alleviated by sufficiently scaled supervised fine-tuning (SFT). Our findings challenge common assumptions about the benefits of long CoT training for SLMs and offer practical guidance for building more effective small-scale reasoning models.
LogicCat: A Chain-of-Thought Text-to-SQL Benchmark for Multi-Domain Reasoning Challenges
May 24, 2025Text-to-SQL is a fundamental task in natural language processing that seeks to translate natural language questions into meaningful and executable SQL queries. While existing datasets are extensive and primarily focus on business scenarios and operational logic, they frequently lack coverage of domain-specific knowledge and complex mathematical reasoning. To address this gap, we present a novel dataset tailored for complex reasoning and chain-of-thought analysis in SQL inference, encompassing physical, arithmetic, commonsense, and hypothetical reasoning. The dataset consists of 4,038 English questions, each paired with a unique SQL query and accompanied by 12,114 step-by-step reasoning annotations, spanning 45 databases across diverse domains. Experimental results demonstrate that LogicCat substantially increases the difficulty for state-of-the-art models, with the highest execution accuracy reaching only 14.96%. Incorporating our chain-of-thought annotations boosts performance to 33.96%. Benchmarking leading public methods on Spider and BIRD further underscores the unique challenges presented by LogicCat, highlighting the significant opportunities for advancing research in robust, reasoning-driven text-to-SQL systems. We have released our dataset code at https://github.com/Ffunkytao/LogicCat.
Casual Inference via Style Bias Deconfounding for Domain Generalization
Mar 21, 2025



Deep neural networks (DNNs) often struggle with out-of-distribution data, limiting their reliability in diverse realworld applications. To address this issue, domain generalization methods have been developed to learn domain-invariant features from single or multiple training domains, enabling generalization to unseen testing domains. However, existing approaches usually overlook the impact of style frequency within the training set. This oversight predisposes models to capture spurious visual correlations caused by style confounding factors, rather than learning truly causal representations, thereby undermining inference reliability. In this work, we introduce Style Deconfounding Causal Learning (SDCL), a novel causal inference-based framework designed to explicitly address style as a confounding factor. Our approaches begins with constructing a structural causal model (SCM) tailored to the domain generalization problem and applies a backdoor adjustment strategy to account for style influence. Building on this foundation, we design a style-guided expert module (SGEM) to adaptively clusters style distributions during training, capturing the global confounding style. Additionally, a back-door causal learning module (BDCL) performs causal interventions during feature extraction, ensuring fair integration of global confounding styles into sample predictions, effectively reducing style bias. The SDCL framework is highly versatile and can be seamlessly integrated with state-of-the-art data augmentation techniques. Extensive experiments across diverse natural and medical image recognition tasks validate its efficacy, demonstrating superior performance in both multi-domain and the more challenging single-domain generalization scenarios.