 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIM4-ASR: Towards Efficient, Robust, and Customizable Real-Time LLM-Based ASR
Apr 20, 2026Integrating large language models (LLMs) into automatic speech recognition (ASR) has become a mainstream paradigm in recent years. Although existing LLM-based ASR models demonstrate impressive performance on public benchmarks, their training remains predominantly data-driven, leaving key practical challenges insufficiently addressed -- particularly limited downward scalability in resource-constrained deployments and hallucinations under acoustically challenging conditions. To address these issues, we present NIM4-ASR, a production-oriented LLM-based ASR framework optimized for both efficiency and robustness. Grounded in a principled delineation of functional roles between the encoder and the LLM, we redesign the multi-stage training paradigm to align each module with its intended capability boundary. Specifically, we reformulate the pre-training architecture and objective to mitigate the modality gap and improve parameter efficiency; introduce an iterative asynchronous SFT stage to preserve acoustic fidelity and constrain representation drift; and design an ASR-specialized reinforcement learning stage to further enhance recognition quality and robustness. We additionally incorporate a suite of production-oriented optimizations, including robustness under noisy and silent conditions, real-time streaming inference, and hotword customization via retrieval-augmented generation (RAG). Experiments show that NIM4-ASR achieves state-of-the-art performance on multiple public benchmarks with merely 2.3B parameters, while substantially outperforming larger-scale competitors on internal benchmarks -- particularly in entity-intensive real-world scenarios. NIM4-ASR further supports million-scale hotword customization via RAG with sub-millisecond retrieval latency, enabling efficient adaptation to emerging entities and personalized user requirements.
Rethinking Entropy Allocation in LLM-based ASR: Understanding the Dynamics between Speech Encoders and LLMs
Apr 09, 2026Integrating large language models (LLMs) into automatic speech recognition (ASR) has become a dominant paradigm. Although recent LLM-based ASR models have shown promising performance on public benchmarks, it remains challenging to balance recognition quality with latency and overhead, while hallucinations further limit real-world deployment. In this study, we revisit LLM-based ASR from an entropy allocation perspective and introduce three metrics to characterize how training paradigms allocate entropy reduction between the speech encoder and the LLM. To remedy entropy-allocation inefficiencies in prevailing approaches, we propose a principled multi-stage training strategy grounded in capability-boundary awareness, optimizing parameter efficiency and hallucination robustness. Specifically, we redesign the pretraining strategy to alleviate the speech-text modality gap, and further introduce an iterative asynchronous SFT stage between alignment and joint SFT to preserve functional decoupling and constrain encoder representation drift. Experiments on Mandarin and English benchmarks show that our method achieves competitive performance with state-of-the-art models using only 2.3B parameters, while also effectively mitigating hallucinations through our decoupling-oriented design.
Agents Play Thousands of 3D Video Games
Mar 17, 2025We present PORTAL, a novel framework for developing artificial intelligence agents capable of playing thousands of 3D video games through language-guided policy generation. By transforming decision-making problems into language modeling tasks, our approach leverages large language models (LLMs) to generate behavior trees represented in domain-specific language (DSL). This method eliminates the computational burden associated with traditional reinforcement learning approaches while preserving strategic depth and rapid adaptability. Our framework introduces a hybrid policy structure that combines rule-based nodes with neural network components, enabling both high-level strategic reasoning and precise low-level control. A dual-feedback mechanism incorporating quantitative game metrics and vision-language model analysis facilitates iterative policy improvement at both tactical and strategic levels. The resulting policies are instantaneously deployable, human-interpretable, and capable of generalizing across diverse gaming environments. Experimental results demonstrate PORTAL's effectiveness across thousands of first-person shooter (FPS) games, showcasing significant improvements in development efficiency, policy generalization, and behavior diversity compared to traditional approaches. PORTAL represents a significant advancement in game AI development, offering a practical solution for creating sophisticated agents that can operate across thousands of commercial video games with minimal development overhead. Experiment results on the 3D video games are best viewed on https://zhongwen.one/projects/portal .
Enhancing Human Experience in Human-Agent Collaboration: A Human-Centered Modeling Approach Based on Positive Human Gain
Jan 28, 2024



Existing game AI research mainly focuses on enhancing agents' abilities to win games, but this does not inherently make humans have a better experience when collaborating with these agents. For example, agents may dominate the collaboration and exhibit unintended or detrimental behaviors, leading to poor experiences for their human partners. In other words, most game AI agents are modeled in a "self-centered" manner. In this paper, we propose a "human-centered" modeling scheme for collaborative agents that aims to enhance the experience of humans. Specifically, we model the experience of humans as the goals they expect to achieve during the task. We expect that agents should learn to enhance the extent to which humans achieve these goals while maintaining agents' original abilities (e.g., winning games). To achieve this, we propose the Reinforcement Learning from Human Gain (RLHG) approach. The RLHG approach introduces a "baseline", which corresponds to the extent to which humans primitively achieve their goals, and encourages agents to learn behaviors that can effectively enhance humans in achieving their goals better. We evaluate the RLHG agent in the popular Multi-player Online Battle Arena (MOBA) game, Honor of Kings, by conducting real-world human-agent tests. Both objective performance and subjective preference results show that the RLHG agent provides participants better gaming experience.
Towards Effective and Interpretable Human-Agent Collaboration in MOBA Games: A Communication Perspective
Apr 23, 2023



MOBA games, e.g., Dota2 and Honor of Kings, have been actively used as the testbed for the recent AI research on games, and various AI systems have been developed at the human level so far. However, these AI systems mainly focus on how to compete with humans, less on exploring how to collaborate with humans. To this end, this paper makes the first attempt to investigate human-agent collaboration in MOBA games. In this paper, we propose to enable humans and agents to collaborate through explicit communication by designing an efficient and interpretable Meta-Command Communication-based framework, dubbed MCC, for accomplishing effective human-agent collaboration in MOBA games. The MCC framework consists of two pivotal modules: 1) an interpretable communication protocol, i.e., the Meta-Command, to bridge the communication gap between humans and agents; 2) a meta-command value estimator, i.e., the Meta-Command Selector, to select a valuable meta-command for each agent to achieve effective human-agent collaboration. Experimental results in Honor of Kings demonstrate that MCC agents can collaborate reasonably well with human teammates and even generalize to collaborate with different levels and numbers of human teammates. Videos are available at https://sites.google.com/view/mcc-demo.
A Real-time Speaker Diarization System Based on Spatial Spectrum
Jul 20, 2021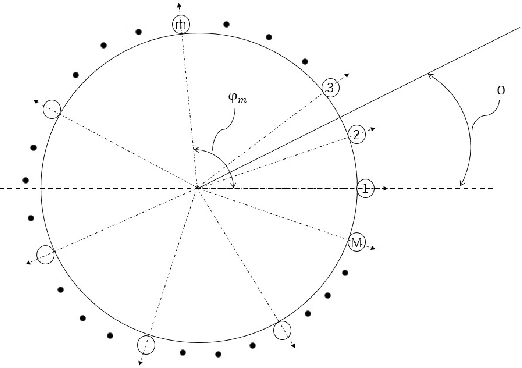

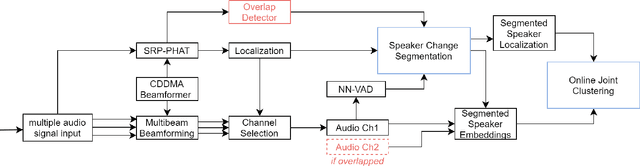

In this paper we describe a speaker diarization system that enables localization and identification of all speakers present in a conversation or meeting. We propose a novel systematic approach to tackle several long-standing challenges in speaker diarization tasks: (1) to segment and separate overlapping speech from two speakers; (2) to estimate the number of speakers when participants may enter or leave the conversation at any time; (3) to provide accurate speaker identification on short text-independent utterances; (4) to track down speakers movement during the conversation; (5) to detect speaker change incidence real-time. First, a differential directional microphone array-based approach is exploited to capture the target speakers' voice in far-field adverse environment. Second, an online speaker-location joint clustering approach is proposed to keep track of speaker location. Third, an instant speaker number detector is developed to trigger the mechanism that separates overlapped speech. The results suggest that our system effectively incorporates spatial information and achieves significant gains.