 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERE: Similarity-based Expert Re-routing for Efficient Batch Decoding in MoE Models
Feb 07, 2026Mixture-of-Experts (MoE) architectures employ sparse activation to deliver faster training and inference with higher accuracy than dense LLMs. However, in production serving, MoE models require batch inference to optimize hardware efficiency, which may cause excessive expert activation and thus slow the memory-bound decoding stage. To address the fundamental tension between batch decoding and expert sparsity, we present SERE, a Similarity-based Expert Re-routing method for Efficient batch decoding in MoE models. SERE dynamically reduces the number of active experts in an input-aware manner by re-routing tokens from secondary experts to their most similar primary counterparts. It also leverages similarity patterns to identify and preserve critical experts, thereby preventing capability loss. Notably, SERE avoids static expert pruning or merging, instead enabling dynamic expert skipping based on batch-level expert redundancy. Additionally, we provide an efficient custom CUDA kernel for SERE, enabling plug-and-play use in vLLM with only a single-line code change. Extensive experiments on various complex reasoning benchmarks demonstrate that SERE achieves up to 2.0x speedup with minimal quality loss, providing a practical solution for cost-efficient and latency-sensitive large-scale MoE deployment. Code implementation of SERE can be found in https://github.com/JL-Cheng/SERE.
LatentChem: From Textual CoT to Latent Thinking in Chemical Reasoning
Feb 06, 2026Chemical large language models (LLMs) predominantly rely on explicit Chain-of-Thought (CoT) in natural language to perform complex reasoning. However, chemical reasoning is inherently continuous and structural, and forcing it into discrete linguistic tokens introduces a fundamental representation mismatch that constrains both efficiency and performance. We introduce LatentChem, a latent reasoning interface that decouples chemical computation from textual generation, enabling models to perform multi-step reasoning directly in continuous latent space while emitting language only for final outputs. Remarkably, we observe a consistent emergent behavior: when optimized solely for task success, models spontaneously internalize reasoning, progressively abandoning verbose textual derivations in favor of implicit latent computation. This shift is not merely stylistic but computationally advantageous. Across diverse chemical reasoning benchmarks, LatentChem achieves a 59.88\% non-tie win rate over strong CoT-based baselines on ChemCoTBench, while delivering a 10.84$\times$ average inference speedup. Our results provide empirical evidence that chemical reasoning is more naturally and effectively realized as continuous latent dynamics rather than discretized linguistic trajectories.
iFSQ: Improving FSQ for Image Generation with 1 Line of Code
Jan 27, 2026The field of image generation is currently bifurcated into autoregressive (AR) models operating on discrete tokens and diffusion models utilizing continuous latents. This divide, rooted in the distinction between VQ-VAEs and VAEs, hinders unified modeling and fair benchmarking. Finite Scalar Quantization (FSQ) offers a theoretical bridge, yet vanilla FSQ suffers from a critical flaw: its equal-interval quantization can cause activation collapse. This mismatch forces a trade-off between reconstruction fidelity and information efficiency. In this work, we resolve this dilemma by simply replacing the activation function in original FSQ with a distribution-matching mapping to enforce a uniform prior. Termed iFSQ, this simple strategy requires just one line of code yet mathematically guarantees both optimal bin utilization and reconstruction precision. Leveraging iFSQ as a controlled benchmark, we uncover two key insights: (1) The optimal equilibrium between discrete and continuous representations lies at approximately 4 bits per dimension. (2) Under identical reconstruction constraints, AR models exhibit rapid initial convergence, whereas diffusion models achieve a superior performance ceiling, suggesting that strict sequential ordering may limit the upper bounds of generation quality. Finally, we extend our analysis by adapting Representation Alignment (REPA) to AR models, yielding LlamaGen-REPA. Codes is available at https://github.com/Tencent-Hunyuan/iFSQ
Agentic reinforcement learning empowers next-generation chemical language models for molecular design and synthesis
Jan 25, 2026Language models are revolutionizing the biochemistry domain, assisting scientists in drug design and chemical synthesis with high efficiency. Yet current approaches struggle between small language models prone to hallucination and limited knowledge retention, and large cloud-based language models plagued by privacy risks and high inference costs. To bridge this gap, we introduce ChemCRAFT, a novel framework leveraging agentic reinforcement learning to decouple chemical reasoning from knowledge storage. Instead of forcing the model to memorize vast chemical data, our approach empowers the language model to interact with a sandbox for precise information retrieval. This externalization of knowledge allows a locally deployable small model to achieve superior performance with minimal inference costs. To enable small language models for agent-calling ability, we build an agentic trajectory construction pipeline and a comprehensive chemical-agent sandbox. Based on sandbox interactions, we constructed ChemToolDataset, the first large-scale chemical tool trajectory dataset. Simultaneously, we propose SMILES-GRPO to build a dense chemical reward function, promoting the model's ability to call chemical agents. Evaluations across diverse aspects of drug design show that ChemCRAFT outperforms current cloud-based LLMs in molecular structure analysis, molecular optimization, and synthesis pathway prediction, demonstrating that scientific reasoning is not solely an emergent ability of model scale, but a learnable policy of tool orchestration. This work establishes a cost-effective and privacy-preserving paradigm for AI-aided chemistry, opening new avenues for accelerating molecular discovery with locally deployable agents.
SAFE-QAQ: End-to-End Slow-Thinking Audio-Text Fraud Detection via Reinforcement Learning
Jan 04, 2026Existing fraud detection methods predominantly rely on transcribed text, suffering from ASR errors and missing crucial acoustic cues like vocal tone and environmental context. This limits their effectiveness against complex deceptive strategies. To address these challenges, we first propose \textbf{SAFE-QAQ}, an end-to-end comprehensive framework for audio-based slow-thinking fraud detection. First, the SAFE-QAQ framework eliminates the impact of transcription errors on detection performance. Secondly, we propose rule-based slow-thinking reward mechanisms that systematically guide the system to identify fraud-indicative patterns by accurately capturing fine-grained audio details, through hierarchical reasoning processes. Besides, our framework introduces a dynamic risk assessment framework during live calls, enabling early detection and prevention of fraud. Experiments on the TeleAntiFraud-Bench demonstrate that SAFE-QAQ achieves dramatic improvements over existing methods in multiple key dimensions, including accuracy, inference efficiency, and real-time processing capabilities. Currently deployed and analyzing over 70,000 calls daily, SAFE-QAQ effectively automates complex fraud detection, reducing human workload and financial losses. Code: https://anonymous.4open.science/r/SAFE-QAQ.
UltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement
Dec 24, 2025In this report, we introduce UltraShape 1.0, a scalable 3D diffusion framework for high-fidelity 3D geometry generation. The proposed approach adopts a two-stage generation pipeline: a coarse global structure is first synthesized and then refined to produce detailed, high-quality geometry. To support reliable 3D generation, we develop a comprehensive data processing pipeline that includes a novel watertight processing method and high-quality data filtering. This pipeline improves the geometric quality of publicly available 3D datasets by removing low-quality samples, filling holes, and thickening thin structures, while preserving fine-grained geometric details. To enable fine-grained geometry refinement, we decouple spatial localization from geometric detail synthesis in the diffusion process. We achieve this by performing voxel-based refinement at fixed spatial locations, where voxel queries derived from coarse geometry provide explicit positional anchors encoded via RoPE, allowing the diffusion model to focus on synthesizing local geometric details within a reduced, structured solution space. Our model is trained exclusively on publicly available 3D datasets, achieving strong geometric quality despite limited training resources. Extensive evaluations demonstrate that UltraShape 1.0 performs competitively with existing open-source methods in both data processing quality and geometry generation. All code and trained models will be released to support future research.
Breaking the Vicious Cycle: Coherent 3D Gaussian Splatting from Sparse and Motion-Blurred Views
Dec 11, 20253D Gaussian Splatting (3DGS) has emerged as a state-of-the-art method for novel view synthesis. However, its performance heavily relies on dense, high-quality input imagery, an assumption that is often violated in real-world applications, where data is typically sparse and motion-blurred. These two issues create a vicious cycle: sparse views ignore the multi-view constraints necessary to resolve motion blur, while motion blur erases high-frequency details crucial for aligning the limited views. Thus, reconstruction often fails catastrophically, with fragmented views and a low-frequency bias. To break this cycle, we introduce CoherentGS, a novel framework for high-fidelity 3D reconstruction from sparse and blurry images. Our key insight is to address these compound degradations using a dual-prior strategy. Specifically, we combine two pre-trained generative models: a specialized deblurring network for restoring sharp details and providing photometric guidance, and a diffusion model that offers geometric priors to fill in unobserved regions of the scene. This dual-prior strategy is supported by several key techniques, including a consistency-guided camera exploration module that adaptively guides the generative process, and a depth regularization loss that ensures geometric plausibility. We evaluate CoherentGS through both quantitative and qualitative experiments on synthetic and real-world scenes, using as few as 3, 6, and 9 input views. Our results demonstrate that CoherentGS significantly outperforms existing methods, setting a new state-of-the-art for this challenging task. The code and video demos are available at https://potatobigroom.github.io/CoherentGS/.
Can Understanding and Generation Truly Benefit Together -- or Just Coexist?
Sep 11, 2025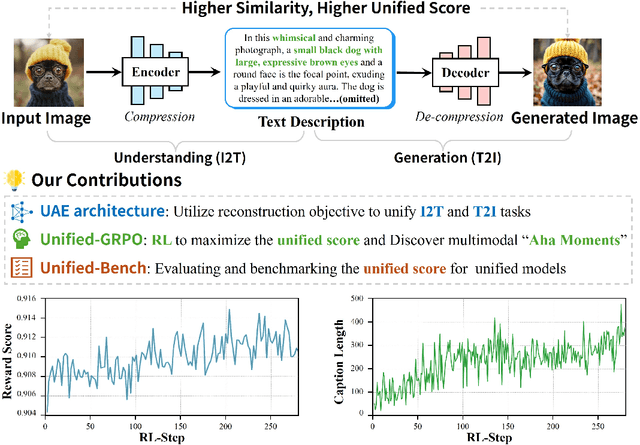
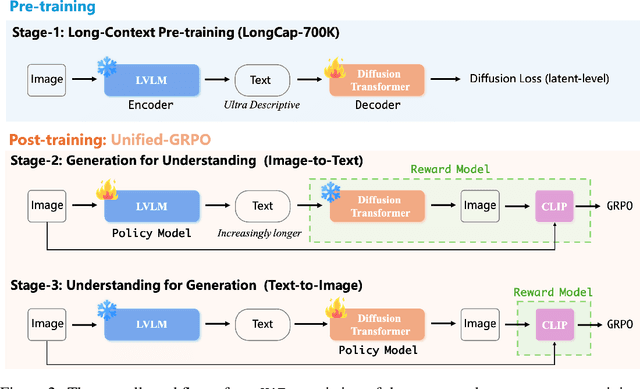
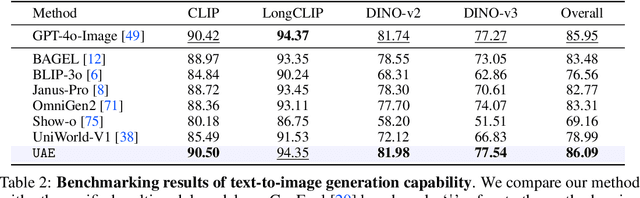
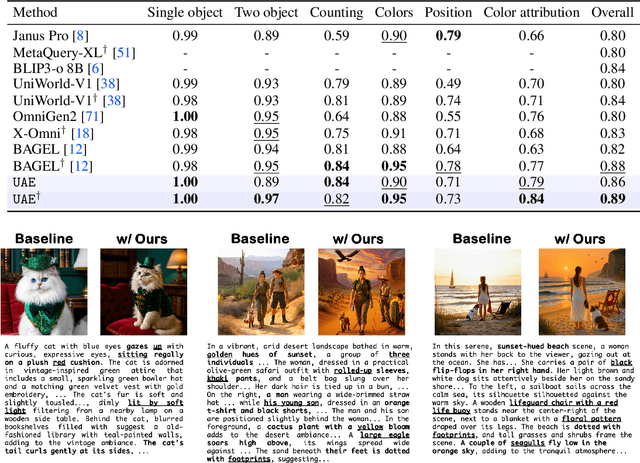
In this paper, we introduce an insightful paradigm through the Auto-Encoder lens-understanding as the encoder (I2T) that compresses images into text, and generation as the decoder (T2I) that reconstructs images from that text. Using reconstruction fidelity as the unified training objective, we enforce the coherent bidirectional information flow between the understanding and generation processes, bringing mutual gains. To implement this, we propose UAE, a novel framework for unified multimodal learning. We begin by pre-training the decoder with large-scale long-context image captions to capture fine-grained semantic and complex spatial relationships. We then propose Unified-GRPO via reinforcement learning (RL), which covers three stages: (1) A cold-start phase to gently initialize both encoder and decoder with a semantic reconstruction loss; (2) Generation for Understanding, where the encoder is trained to generate informative captions that maximize the decoder's reconstruction quality, enhancing its visual understanding; (3) Understanding for Generation, where the decoder is refined to reconstruct from these captions, forcing it to leverage every detail and improving its long-context instruction following and generation fidelity. For evaluation, we introduce Unified-Bench, the first benchmark tailored to assess the degree of unification of the UMMs. A surprising "aha moment" arises within the multimodal learning domain: as RL progresses, the encoder autonomously produces more descriptive captions, while the decoder simultaneously demonstrates a profound ability to understand these intricate descriptions, resulting in reconstructions of striking fidelity.
E-4DGS: High-Fidelity Dynamic Reconstruction from the Multi-view Event Cameras
Aug 13, 2025Novel view synthesis and 4D reconstruction techniques predominantly rely on RGB cameras, thereby inheriting inherent limitations such as the dependence on adequate lighting, susceptibility to motion blur, and a limited dynamic range. Event cameras, offering advantages of low power, high temporal resolution and high dynamic range, have brought a new perspective to addressing the scene reconstruction challenges in high-speed motion and low-light scenes. To this end, we propose E-4DGS, the first event-driven dynamic Gaussian Splatting approach, for novel view synthesis from multi-view event streams with fast-moving cameras. Specifically, we introduce an event-based initialization scheme to ensure stable training and propose event-adaptive slicing splatting for time-aware reconstruction. Additionally, we employ intensity importance pruning to eliminate floating artifacts and enhance 3D consistency, while incorporating an adaptive contrast threshold for more precise optimization. We design a synthetic multi-view camera setup with six moving event cameras surrounding the object in a 360-degree configuration and provide a benchmark multi-view event stream dataset that captures challenging motion scenarios. Our approach outperforms both event-only and event-RGB fusion baselines and paves the way for the exploration of multi-view event-based reconstruction as a novel approach for rapid scene capture.
AsFT: Anchoring Safety During LLM Fine-Tuning Within Narrow Safety Basin
Jun 11, 2025



Large language models (LLMs) are vulnerable to safety risks during fine-tuning, where small amounts of malicious or harmless data can compromise safeguards. In this paper, building on the concept of alignment direction -- defined by the weight difference between aligned and unaligned models -- we observe that perturbations along this direction preserve model safety. In contrast, perturbations along directions orthogonal to this alignment are strongly linked to harmful direction perturbations, rapidly degrading safety and framing the parameter space as a narrow safety basin. Based on this insight, we propose a methodology for safety fine-tuning called AsFT (Anchoring Safety in Fine-Tuning), which integrates a regularization term into the training objective. This term uses the alignment direction as an anchor to suppress updates in harmful directions, ensuring that fine-tuning is constrained within the narrow safety basin. Extensive experiments on multiple datasets show that AsFT outperforms Safe LoRA, reducing harmful behavior by 7.60 percent, improving model performance by 3.44 percent, and maintaining robust performance across various experimental settings. Code is available at https://github.com/PKU-YuanGroup/AsFT