 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniPlan: An Adaptive Framework for Timely and Near-Optimal Network Planning Optimization
Jun 17, 2026Network planning optimization is a fundamental problem across diverse domains, including transportation systems, communication networks, and power grids. It requires simultaneous optimization of multiple competing objectives under complex constraints. Existing network planning optimization frameworks rely on mixed integer programming (MIP) solvers, heuristics, and deep reinforcement learning (DRL) models to compute planning decisions. However, they lack effective adaptability to diverse and dynamic user intents, thus leading to the trade-off between execution time and optimality. In this paper, we propose OmniPlan, an adaptive framework that achieves both timeliness and near-optimality in network planning optimization. To achieve the adaptability lacking in existing solutions, OmniPlan employs a large language model (LLM)-based interpreter to convert heterogeneous natural-language intents into a unified and quantifiable user-preference vector. Then it employs a mixture-of-experts architecture that integrates MIP solvers, heuristics, and DRL models as specialized experts, where OmniPlan adapts to diverse intents by dynamically selecting timely and near-optimal experts. Finally, it incorporates a DRL-based expert configuration module that fine-tunes optimization objective weights to align planning decisions with user-specific preferences. We evaluate OmniPlan with a representative real-world workload, i.e., distributed machine learning (ML), where we leverage OmniPlan to offload a wide spectrum of ML inference tasks, e.g., decision trees, SVM, naive Bayes, XGBoost, and random forests, onto a network of hardware devices. Our experiments on a real-world testbed indicate that OmniPlan achieves near-optimal and low-execution-time offloading for real-world ML inference tasks, reducing latency by up to 97.8\% and network device resource consumption by up to 11.5\%.
AIoT-based Continuous, Contextualized, and Explainable Driving Assessment for Older Adults
Feb 28, 2026The world is undergoing a major demographic shift as older adults become a rapidly growing share of the population, creating new challenges for driving safety. In car-dependent regions such as the United States, driving remains essential for independence, access to services, and social participation. At the same time, aging can introduce gradual changes in vision, attention, reaction time, and driving control that quietly reduce safety. Today's assessment methods rely largely on infrequent clinic visits or simple screening tools, offering only a brief snapshot and failing to reflect how an older adult actually drives on the road. Our work starts from the observation that everyday driving provides a continuous record of functional ability and captures how a driver responds to traffic, navigates complex roads, and manages routine behavior. Leveraging this insight, we propose AURA, an Artificial Intelligence of Things (AIoT) framework for continuous, real-world assessment of driving safety among older adults. AURA integrates richer in-vehicle sensing, multi-scale behavioral modeling, and context-aware analysis to extract detailed indicators of driving performance from routine trips. It organizes fine-grained actions into longer behavioral trajectories and separates age-related performance changes from situational factors such as traffic, road design, or weather. By integrating sensing, modeling, and interpretation within a privacy-preserving edge architecture, AURA provides a foundation for proactive, individualized support that helps older adults drive safely. This paper outlines the design principles, challenges, and research opportunities needed to build reliable, real-world monitoring systems that promote safer aging behind the wheel.
LatentChem: From Textual CoT to Latent Thinking in Chemical Reasoning
Feb 06, 2026Chemical large language models (LLMs) predominantly rely on explicit Chain-of-Thought (CoT) in natural language to perform complex reasoning. However, chemical reasoning is inherently continuous and structural, and forcing it into discrete linguistic tokens introduces a fundamental representation mismatch that constrains both efficiency and performance. We introduce LatentChem, a latent reasoning interface that decouples chemical computation from textual generation, enabling models to perform multi-step reasoning directly in continuous latent space while emitting language only for final outputs. Remarkably, we observe a consistent emergent behavior: when optimized solely for task success, models spontaneously internalize reasoning, progressively abandoning verbose textual derivations in favor of implicit latent computation. This shift is not merely stylistic but computationally advantageous. Across diverse chemical reasoning benchmarks, LatentChem achieves a 59.88\% non-tie win rate over strong CoT-based baselines on ChemCoTBench, while delivering a 10.84$\times$ average inference speedup. Our results provide empirical evidence that chemical reasoning is more naturally and effectively realized as continuous latent dynamics rather than discretized linguistic trajectories.
CoDoL: Conditional Domain Prompt Learning for Out-of-Distribution Generalization
Sep 18, 2025Recent advances in pre-training vision-language models (VLMs), e.g., contrastive language-image pre-training (CLIP) methods, have shown great potential in learning out-of-distribution (OOD) representations. Despite showing competitive performance, the prompt-based CLIP methods still suffer from: i) inaccurate text descriptions, which leads to degraded accuracy and robustness, and poses a challenge for zero-shot CLIP methods. ii) limited vision-language embedding alignment, which significantly affects the generalization performance. To tackle the above issues, this paper proposes a novel Conditional Domain prompt Learning (CoDoL) method, which utilizes readily-available domain information to form prompts and improves the vision-language embedding alignment for improving OOD generalization. To capture both instance-specific and domain-specific information, we further propose a lightweight Domain Meta Network (DMN) to generate input-conditional tokens for images in each domain. Extensive experiments on four OOD benchmarks (PACS, VLCS, OfficeHome and DigitDG) validate the effectiveness of our proposed CoDoL in terms of improving the vision-language embedding alignment as well as the out-of-distribution generalization performance.
Hydra-Bench: A Benchmark for Multi-Modal Leaf Wetness Sensing
Jul 30, 2025Leaf wetness detection is a crucial task in agricultural monitoring, as it directly impacts the prediction and protection of plant diseases. However, existing sensing systems suffer from limitations in robustness, accuracy, and environmental resilience when applied to natural leaves under dynamic real-world conditions. To address these challenges, we introduce a new multi-modal dataset specifically designed for evaluating and advancing machine learning algorithms in leaf wetness detection. Our dataset comprises synchronized mmWave raw data, Synthetic Aperture Radar (SAR) images, and RGB images collected over six months from five diverse plant species in both controlled and outdoor field environments. We provide detailed benchmarks using the Hydra model, including comparisons against single modality baselines and multiple fusion strategies, as well as performance under varying scan distances. Additionally, our dataset can serve as a benchmark for future SAR imaging algorithm optimization, enabling a systematic evaluation of detection accuracy under diverse conditions.
A Dual-Fusion Cognitive Diagnosis Framework for Open Student Learning Environments
Oct 19, 2024



Cognitive diagnosis model (CDM) is a fundamental and upstream component in intelligent education. It aims to infer students' mastery levels based on historical response logs. However, existing CDMs usually follow the ID-based embedding paradigm, which could often diminish the effectiveness of CDMs in open student learning environments. This is mainly because they can hardly directly infer new students' mastery levels or utilize new exercises or knowledge without retraining. Textual semantic information, due to its unified feature space and easy accessibility, can help alleviate this issue. Unfortunately, directly incorporating semantic information may not benefit CDMs, since it does not capture response-relevant features and thus discards the individual characteristics of each student. To this end, this paper proposes a dual-fusion cognitive diagnosis framework (DFCD) to address the challenge of aligning two different modalities, i.e., textual semantic features and response-relevant features. Specifically, in DFCD, we first propose the exercise-refiner and concept-refiner to make the exercises and knowledge concepts more coherent and reasonable via large language models. Then, DFCD encodes the refined features using text embedding models to obtain the semantic information. For response-related features, we propose a novel response matrix to fully incorporate the information within the response logs. Finally, DFCD designs a dual-fusion module to merge the two modal features. The ultimate representations possess the capability of inference in open student learning environments and can be also plugged in existing CDMs. Extensive experiments across real-world datasets show that DFCD achieves superior performance by integrating different modalities and strong adaptability in open student learning environments.
LocoVR: Multiuser Indoor Locomotion Dataset in Virtual Reality
Oct 09, 2024Understanding human locomotion is crucial for AI agents such as robots, particularly in complex indoor home environments. Modeling human trajectories in these spaces requires insight into how individuals maneuver around physical obstacles and manage social navigation dynamics. These dynamics include subtle behaviors influenced by proxemics - the social use of space, such as stepping aside to allow others to pass or choosing longer routes to avoid collisions. Previous research has developed datasets of human motion in indoor scenes, but these are often limited in scale and lack the nuanced social navigation dynamics common in home environments. To address this, we present LocoVR, a dataset of 7000+ two-person trajectories captured in virtual reality from over 130 different indoor home environments. LocoVR provides full body pose data and precise spatial information, along with rich examples of socially-motivated movement behaviors. For example, the dataset captures instances of individuals navigating around each other in narrow spaces, adjusting paths to respect personal boundaries in living areas, and coordinating movements in high-traffic zones like entryways and kitchens. Our evaluation shows that LocoVR significantly enhances model performance in three practical indoor tasks utilizing human trajectories, and demonstrates predicting socially-aware navigation patterns in home environments.
SiCo: A Size-Controllable Virtual Try-On Approach for Informed Decision-Making
Aug 05, 2024



Virtual try-on (VTO) applications aim to improve the online shopping experience by allowing users to preview garments, before making purchase decisions. However, many VTO tools fail to consider the crucial relationship between a garment's size and the user's body size, often employing a one-size-fits-all approach when visualizing a clothing item. This results in poor size recommendations and purchase decisions leading to increased return rates. To address this limitation, we introduce SiCo, an online VTO system, where users can upload images of themselves and visualize how different sizes of clothing would look on their body to help make better-informed purchase decisions. Our user study shows SiCo's superiority over baseline VTO. The results indicate that our approach significantly enhances user ability to gauge the appearance of outfits on their bodies and boosts their confidence in selecting clothing sizes that match desired goals. Based on our evaluation, we believe our VTO design has the potential to reduce return rates and enhance the online clothes shopping experience. Our code is available at https://github.com/SherryXTChen/SiCo.
Txt2Vid: Ultra-Low Bitrate Compression of Talking-Head Videos via Text
Jun 26, 2021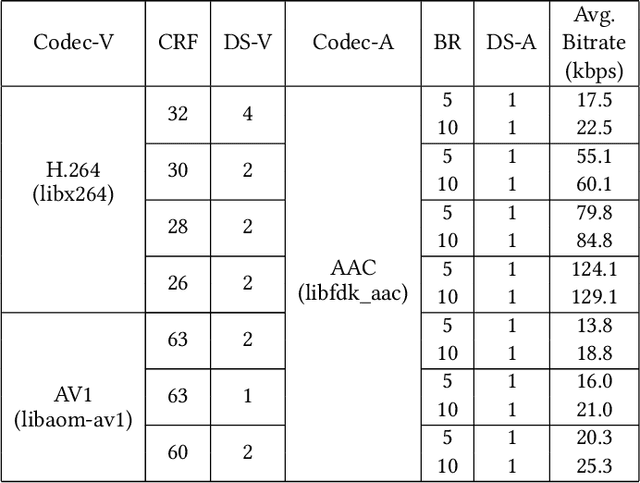
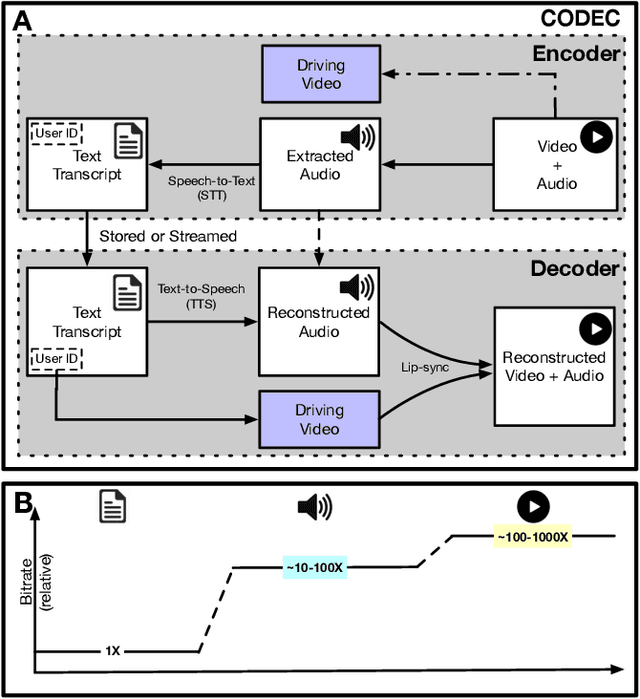
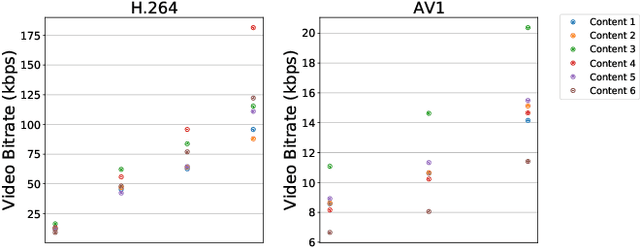
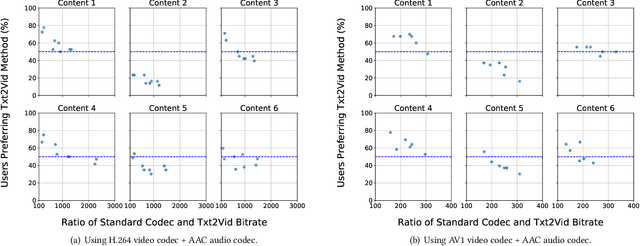
Video represents the majority of internet traffic today leading to a continuous technological arms race between generating higher quality content, transmitting larger file sizes and supporting network infrastructure. Adding to this is the recent COVID-19 pandemic fueled surge in the use of video conferencing tools. Since videos take up substantial bandwidth (~100 Kbps to few Mbps), improved video compression can have a substantial impact on network performance for live and pre-recorded content, providing broader access to multimedia content worldwide. In this work, we present a novel video compression pipeline, called Txt2Vid, which substantially reduces data transmission rates by compressing webcam videos ("talking-head videos") to a text transcript. The text is transmitted and decoded into a realistic reconstruction of the original video using recent advances in deep learning based voice cloning and lip syncing models. Our generative pipeline achieves two to three orders of magnitude reduction in the bitrate as compared to the standard audio-video codecs (encoders-decoders), while maintaining equivalent Quality-of-Experience based on a subjective evaluation by users (n=242) in an online study. The code for this work is available at https://github.com/tpulkit/txt2vid.git.