 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Value Models for Robotic Manipulation
Jun 23, 2026Generalist value models play a pivotal role in scaling robotic policy learning from large-scale, mixed-quality data. Mathematically, accurate value estimation demands deep temporal understanding, requiring models to both ground the current belief using historical context and plan over future outcomes. However, most existing robotic value models are built on Vision-Language Model (VLM) backbones that are pretrained primarily on static or temporally sparse visual observations, lacking the requisite temporal modeling capabilities for value estimation. Unlike VLMs, world models naturally excel at temporal modeling and future planning, making them ideal foundations for learning generalizable value functions. Driven by this insight, we marry world models with value estimation to construct a new generalist robotic value model, World Value Model (WVM), that offers accurate task progressions to assess data quality. On standard benchmarks, WVM delivers state-of-the-art (SOTA) Value-Order Correlation (VOC) results. Complementing standard evaluation suites that contains only expert data, we further introduce Suboptimal-Value-Bench, a multi-embodiment benchmark consisting of 800 suboptimal trajectories with high-fidelity, human-labeled frame annotations. Our evaluations show that WVM maintains its SOTA performance on Suboptimal-Value-Bench, establishing its robustness in handling both expert and suboptimal data. When deployed for policy learning, WVM improves manipulation performance across various policy extraction approaches in both simulated and real-world deployment, providing robust guidance for learning from mixed-quality data.
Ling and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
SAFE-QAQ: End-to-End Slow-Thinking Audio-Text Fraud Detection via Reinforcement Learning
Jan 04, 2026Existing fraud detection methods predominantly rely on transcribed text, suffering from ASR errors and missing crucial acoustic cues like vocal tone and environmental context. This limits their effectiveness against complex deceptive strategies. To address these challenges, we first propose \textbf{SAFE-QAQ}, an end-to-end comprehensive framework for audio-based slow-thinking fraud detection. First, the SAFE-QAQ framework eliminates the impact of transcription errors on detection performance. Secondly, we propose rule-based slow-thinking reward mechanisms that systematically guide the system to identify fraud-indicative patterns by accurately capturing fine-grained audio details, through hierarchical reasoning processes. Besides, our framework introduces a dynamic risk assessment framework during live calls, enabling early detection and prevention of fraud. Experiments on the TeleAntiFraud-Bench demonstrate that SAFE-QAQ achieves dramatic improvements over existing methods in multiple key dimensions, including accuracy, inference efficiency, and real-time processing capabilities. Currently deployed and analyzing over 70,000 calls daily, SAFE-QAQ effectively automates complex fraud detection, reducing human workload and financial losses. Code: https://anonymous.4open.science/r/SAFE-QAQ.
Dichotomous Diffusion Policy Optimization
Dec 31, 2025Diffusion-based policies have gained growing popularity in solving a wide range of decision-making tasks due to their superior expressiveness and controllable generation during inference. However, effectively training large diffusion policies using reinforcement learning (RL) remains challenging. Existing methods either suffer from unstable training due to directly maximizing value objectives, or face computational issues due to relying on crude Gaussian likelihood approximation, which requires a large amount of sufficiently small denoising steps. In this work, we propose DIPOLE (Dichotomous diffusion Policy improvement), a novel RL algorithm designed for stable and controllable diffusion policy optimization. We begin by revisiting the KL-regularized objective in RL, which offers a desirable weighted regression objective for diffusion policy extraction, but often struggles to balance greediness and stability. We then formulate a greedified policy regularization scheme, which naturally enables decomposing the optimal policy into a pair of stably learned dichotomous policies: one aims at reward maximization, and the other focuses on reward minimization. Under such a design, optimized actions can be generated by linearly combining the scores of dichotomous policies during inference, thereby enabling flexible control over the level of greediness.Evaluations in offline and offline-to-online RL settings on ExORL and OGBench demonstrate the effectiveness of our approach. We also use DIPOLE to train a large vision-language-action (VLA) model for end-to-end autonomous driving (AD) and evaluate it on the large-scale real-world AD benchmark NAVSIM, highlighting its potential for complex real-world applications.
MVAR: MultiVariate AutoRegressive Air Pollutants Forecasting Model
Jul 16, 2025Air pollutants pose a significant threat to the environment and human health, thus forecasting accurate pollutant concentrations is essential for pollution warnings and policy-making. Existing studies predominantly focus on single-pollutant forecasting, neglecting the interactions among different pollutants and their diverse spatial responses. To address the practical needs of forecasting multivariate air pollutants, we propose MultiVariate AutoRegressive air pollutants forecasting model (MVAR), which reduces the dependency on long-time-window inputs and boosts the data utilization efficiency. We also design the Multivariate Autoregressive Training Paradigm, enabling MVAR to achieve 120-hour long-term sequential forecasting. Additionally, MVAR develops Meteorological Coupled Spatial Transformer block, enabling the flexible coupling of AI-based meteorological forecasts while learning the interactions among pollutants and their diverse spatial responses. As for the lack of standardized datasets in air pollutants forecasting, we construct a comprehensive dataset covering 6 major pollutants across 75 cities in North China from 2018 to 2023, including ERA5 reanalysis data and FuXi-2.0 forecast data. Experimental results demonstrate that the proposed model outperforms state-of-the-art methods and validate the effectiveness of the proposed architecture.
Rainbow Artifacts from Electromagnetic Signal Injection Attacks on Image Sensors
Jul 10, 2025
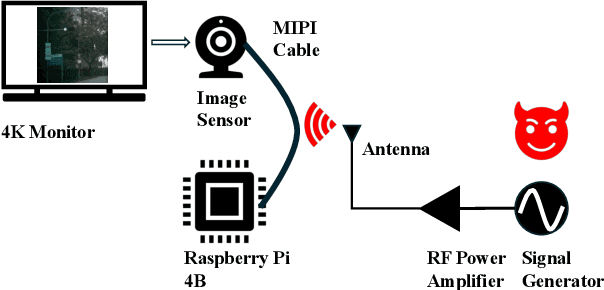


Image sensors are integral to a wide range of safety- and security-critical systems, including surveillance infrastructure, autonomous vehicles, and industrial automation. These systems rely on the integrity of visual data to make decisions. In this work, we investigate a novel class of electromagnetic signal injection attacks that target the analog domain of image sensors, allowing adversaries to manipulate raw visual inputs without triggering conventional digital integrity checks. We uncover a previously undocumented attack phenomenon on CMOS image sensors: rainbow-like color artifacts induced in images captured by image sensors through carefully tuned electromagnetic interference. We further evaluate the impact of these attacks on state-of-the-art object detection models, showing that the injected artifacts propagate through the image signal processing pipeline and lead to significant mispredictions. Our findings highlight a critical and underexplored vulnerability in the visual perception stack, highlighting the need for more robust defenses against physical-layer attacks in such systems.
A Novel ViDAR Device With Visual Inertial Encoder Odometry and Reinforcement Learning-Based Active SLAM Method
Jun 16, 2025In the field of multi-sensor fusion for simultaneous localization and mapping (SLAM), monocular cameras and IMUs are widely used to build simple and effective visual-inertial systems. However, limited research has explored the integration of motor-encoder devices to enhance SLAM performance. By incorporating such devices, it is possible to significantly improve active capability and field of view (FOV) with minimal additional cost and structural complexity. This paper proposes a novel visual-inertial-encoder tightly coupled odometry (VIEO) based on a ViDAR (Video Detection and Ranging) device. A ViDAR calibration method is introduced to ensure accurate initialization for VIEO. In addition, a platform motion decoupled active SLAM method based on deep reinforcement learning (DRL) is proposed. Experimental data demonstrate that the proposed ViDAR and the VIEO algorithm significantly increase cross-frame co-visibility relationships compared to its corresponding visual-inertial odometry (VIO) algorithm, improving state estimation accuracy. Additionally, the DRL-based active SLAM algorithm, with the ability to decouple from platform motion, can increase the diversity weight of the feature points and further enhance the VIEO algorithm's performance. The proposed methodology sheds fresh insights into both the updated platform design and decoupled approach of active SLAM systems in complex environments.
* 12 pages, 13 figures
An Empirical Study of Federated Prompt Learning for Vision Language Model
May 29, 2025The Vision Language Model (VLM) excels in aligning vision and language representations, and prompt learning has emerged as a key technique for adapting such models to downstream tasks. However, the application of prompt learning with VLM in federated learning (\fl{}) scenarios remains underexplored. This paper systematically investigates the behavioral differences between language prompt learning (LPT) and vision prompt learning (VPT) under data heterogeneity challenges, including label skew and domain shift. We conduct extensive experiments to evaluate the impact of various \fl{} and prompt configurations, such as client scale, aggregation strategies, and prompt length, to assess the robustness of Federated Prompt Learning (FPL). Furthermore, we explore strategies for enhancing prompt learning in complex scenarios where label skew and domain shift coexist, including leveraging both prompt types when computational resources allow. Our findings offer practical insights into optimizing prompt learning in federated settings, contributing to the broader deployment of VLMs in privacy-preserving environments.
Stereographic Multi-Try Metropolis Algorithms for Heavy-tailed Sampling
May 18, 2025Markov chain Monte Carlo (MCMC) methods for sampling from heavy-tailed distributions present unique challenges, particularly in high dimensions. Multi-proposal MCMC algorithms have recently gained attention for their potential to improve performance, especially through parallel implementation on modern hardware. This paper introduces a novel family of gradient-free MCMC algorithms that combine the multi-try Metropolis (MTM) with stereographic MCMC framework, specifically designed for efficient sampling from heavy-tailed targets. The proposed stereographic multi-try Metropolis (SMTM) algorithm not only outperforms traditional Euclidean MTM and existing stereographic random-walk Metropolis methods, but also avoids the pathological convergence behavior often observed in MTM and demonstrates strong robustness to tuning. These properties are supported by scaling analysis and extensive simulation studies.
Efficient Robotic Policy Learning via Latent Space Backward Planning
May 11, 2025Current robotic planning methods often rely on predicting multi-frame images with full pixel details. While this fine-grained approach can serve as a generic world model, it introduces two significant challenges for downstream policy learning: substantial computational costs that hinder real-time deployment, and accumulated inaccuracies that can mislead action extraction. Planning with coarse-grained subgoals partially alleviates efficiency issues. However, their forward planning schemes can still result in off-task predictions due to accumulation errors, leading to misalignment with long-term goals. This raises a critical question: Can robotic planning be both efficient and accurate enough for real-time control in long-horizon, multi-stage tasks? To address this, we propose a Latent Space Backward Planning scheme (LBP), which begins by grounding the task into final latent goals, followed by recursively predicting intermediate subgoals closer to the current state. The grounded final goal enables backward subgoal planning to always remain aware of task completion, facilitating on-task prediction along the entire planning horizon. The subgoal-conditioned policy incorporates a learnable token to summarize the subgoal sequences and determines how each subgoal guides action extraction. Through extensive simulation and real-robot long-horizon experiments, we show that LBP outperforms existing fine-grained and forward planning methods, achieving SOTA performance. Project Page: https://lbp-authors.github.io