 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighlightBench: Benchmarking Markup-Driven Table Reasoning in Scientific Documents
Mar 25, 2026Visual markups such as highlights, underlines, and bold text are common in table-centric documents. Although multimodal large language models (MLLMs) have made substantial progress in document understanding, their ability to treat such cues as explicit logical directives remains under-explored. More importantly, existing evaluations cannot distinguish whether a model fails to see the markup or fails to reason with it. This creates a key blind spot in assessing markup-conditioned behavior over tables. To address this gap, we introduce HighlightBench, a diagnostic benchmark for markup-driven table understanding that decomposes evaluation into five task families: Markup Grounding, Constrained Retrieval, Local Relations, Aggregation \& Comparison, and Consistency \& Missingness. We further provide a reference pipeline that makes intermediate decisions explicit, enabling reproducible baselines and finer-grained attribution of errors along the perception-to-execution chain. Experiments show that even strong models remain unstable when visual cues must be consistently aligned with symbolic reasoning under structured output constraints.
Prism-$Δ$: Differential Subspace Steering for Prompt Highlighting in Large Language Models
Mar 11, 2026Prompt highlighting steers a large language model to prioritize user-specified text spans during generation. A key challenge is extracting steering directions that capture the difference between relevant and irrelevant contexts, rather than shared structural patterns common to both. We propose PRISM-$Δ$ (Projection-based Relevance-Informed Steering Method), which decomposes the difference between positive and negative cross-covariance matrices to maximize discriminative energy while eliminating shared directions. Each attention head receives a continuous softplus importance weight, letting weak-but-useful heads contribute at reduced strength. The framework extends naturally to Value representations, capturing content-channel signal that Key-only methods leave unused. Across four benchmarks and five models, PRISM-$Δ$ matches or exceeds the best existing method on 19 of 20 configurations, with relative gains up to +10.6%, while halving the fluency cost of steering. PRISM-$Δ$ also scales to long-context retrieval, outperforming the best existing method by up to +4.8% relative gain. PRISM-$Δ$ is compatible with FlashAttention and adds negligible memory overhead.
Gated Differentiable Working Memory for Long-Context Language Modeling
Jan 19, 2026Long contexts challenge transformers: attention scores dilute across thousands of tokens, critical information is often lost in the middle, and models struggle to adapt to novel patterns at inference time. Recent work on test-time adaptation addresses this by maintaining a form of working memory -- transient parameters updated on the current context -- but existing approaches rely on uniform write policies that waste computation on low-utility regions and suffer from high gradient variance across semantically heterogeneous contexts. In this work, we reframe test-time adaptation as a budget-constrained memory consolidation problem, focusing on which parts of the context should be consolidated into working memory under limited computation. We propose Gdwm (Gated Differentiable Working Memory), a framework that introduces a write controller to gate the consolidation process. The controller estimates Contextual Utility, an information-theoretic measure of long-range contextual dependence, and allocates gradient steps accordingly while maintaining global coverage. Experiments on ZeroSCROLLS and LongBench v2 demonstrate that Gdwm achieves comparable or superior performance with 4$\times$ fewer gradient steps than uniform baselines, establishing a new efficiency-performance Pareto frontier for test-time adaptation.
Spatial Blind Spot: Auditory Motion Perception Deficits in Audio LLMs
Nov 17, 2025Large Audio-Language Models (LALMs) have recently shown impressive progress in speech recognition, audio captioning, and auditory question answering. Yet, whether these models can perceive spatial dynamics, particularly the motion of sound sources, remains unclear. In this work, we uncover a systematic motion perception deficit in current ALLMs. To investigate this issue, we introduce AMPBench, the first benchmark explicitly designed to evaluate auditory motion understanding. AMPBench introduces a controlled question-answering benchmark designed to evaluate whether Audio-Language Models (LALMs) can infer the direction and trajectory of moving sound sources from binaural audio. Comprehensive quantitative and qualitative analyses reveal that current models struggle to reliably recognize motion cues or distinguish directional patterns. The average accuracy remains below 50%, underscoring a fundamental limitation in auditory spatial reasoning. Our study highlights a fundamental gap between human and model auditory spatial reasoning, providing both a diagnostic tool and new insight for enhancing spatial cognition in future Audio-Language Models.
Learning-To-Measure: In-context Active Feature Acquisition
Oct 14, 2025



Active feature acquisition (AFA) is a sequential decision-making problem where the goal is to improve model performance for test instances by adaptively selecting which features to acquire. In practice, AFA methods often learn from retrospective data with systematic missingness in the features and limited task-specific labels. Most prior work addresses acquisition for a single predetermined task, limiting scalability. To address this limitation, we formalize the meta-AFA problem, where the goal is to learn acquisition policies across various tasks. We introduce Learning-to-Measure (L2M), which consists of i) reliable uncertainty quantification over unseen tasks, and ii) an uncertainty-guided greedy feature acquisition agent that maximizes conditional mutual information. We demonstrate a sequence-modeling or autoregressive pre-training approach that underpins reliable uncertainty quantification for tasks with arbitrary missingness. L2M operates directly on datasets with retrospective missingness and performs the meta-AFA task in-context, eliminating per-task retraining. Across synthetic and real-world tabular benchmarks, L2M matches or surpasses task-specific baselines, particularly under scarce labels and high missingness.
A Survey of Vibe Coding with Large Language Models
Oct 14, 2025The advancement of large language models (LLMs) has catalyzed a paradigm shift from code generation assistance to autonomous coding agents, enabling a novel development methodology termed "Vibe Coding" where developers validate AI-generated implementations through outcome observation rather than line-by-line code comprehension. Despite its transformative potential, the effectiveness of this emergent paradigm remains under-explored, with empirical evidence revealing unexpected productivity losses and fundamental challenges in human-AI collaboration. To address this gap, this survey provides the first comprehensive and systematic review of Vibe Coding with large language models, establishing both theoretical foundations and practical frameworks for this transformative development approach. Drawing from systematic analysis of over 1000 research papers, we survey the entire vibe coding ecosystem, examining critical infrastructure components including LLMs for coding, LLM-based coding agent, development environment of coding agent, and feedback mechanisms. We first introduce Vibe Coding as a formal discipline by formalizing it through a Constrained Markov Decision Process that captures the dynamic triadic relationship among human developers, software projects, and coding agents. Building upon this theoretical foundation, we then synthesize existing practices into five distinct development models: Unconstrained Automation, Iterative Conversational Collaboration, Planning-Driven, Test-Driven, and Context-Enhanced Models, thus providing the first comprehensive taxonomy in this domain. Critically, our analysis reveals that successful Vibe Coding depends not merely on agent capabilities but on systematic context engineering, well-established development environments, and human-agent collaborative development models.
A Survey of Context Engineering for Large Language Models
Jul 17, 2025The performance of Large Language Models (LLMs) is fundamentally determined by the contextual information provided during inference. This survey introduces Context Engineering, a formal discipline that transcends simple prompt design to encompass the systematic optimization of information payloads for LLMs. We present a comprehensive taxonomy decomposing Context Engineering into its foundational components and the sophisticated implementations that integrate them into intelligent systems. We first examine the foundational components: context retrieval and generation, context processing and context management. We then explore how these components are architecturally integrated to create sophisticated system implementations: retrieval-augmented generation (RAG), memory systems and tool-integrated reasoning, and multi-agent systems. Through this systematic analysis of over 1300 research papers, our survey not only establishes a technical roadmap for the field but also reveals a critical research gap: a fundamental asymmetry exists between model capabilities. While current models, augmented by advanced context engineering, demonstrate remarkable proficiency in understanding complex contexts, they exhibit pronounced limitations in generating equally sophisticated, long-form outputs. Addressing this gap is a defining priority for future research. Ultimately, this survey provides a unified framework for both researchers and engineers advancing context-aware AI.
AsFT: Anchoring Safety During LLM Fine-Tuning Within Narrow Safety Basin
Jun 11, 2025



Large language models (LLMs) are vulnerable to safety risks during fine-tuning, where small amounts of malicious or harmless data can compromise safeguards. In this paper, building on the concept of alignment direction -- defined by the weight difference between aligned and unaligned models -- we observe that perturbations along this direction preserve model safety. In contrast, perturbations along directions orthogonal to this alignment are strongly linked to harmful direction perturbations, rapidly degrading safety and framing the parameter space as a narrow safety basin. Based on this insight, we propose a methodology for safety fine-tuning called AsFT (Anchoring Safety in Fine-Tuning), which integrates a regularization term into the training objective. This term uses the alignment direction as an anchor to suppress updates in harmful directions, ensuring that fine-tuning is constrained within the narrow safety basin. Extensive experiments on multiple datasets show that AsFT outperforms Safe LoRA, reducing harmful behavior by 7.60 percent, improving model performance by 3.44 percent, and maintaining robust performance across various experimental settings. Code is available at https://github.com/PKU-YuanGroup/AsFT
CANDOR: Counterfactual ANnotated DOubly Robust Off-Policy Evaluation
Dec 11, 2024



Off-policy evaluation (OPE) provides safety guarantees by estimating the performance of a policy before deployment. Recent work introduced IS+, an importance sampling (IS) estimator that uses expert-annotated counterfactual samples to improve behavior dataset coverage. However, IS estimators are known to have high variance; furthermore, the performance of IS+ deteriorates when annotations are imperfect. In this work, we propose a family of OPE estimators inspired by the doubly robust (DR) principle. A DR estimator combines IS with a reward model estimate, known as the direct method (DM), and offers favorable statistical guarantees. We propose three strategies for incorporating counterfactual annotations into a DR-inspired estimator and analyze their properties under various realistic settings. We prove that using imperfect annotations in the DM part of the estimator best leverages the annotations, as opposed to using them in the IS part. To support our theoretical findings, we evaluate the proposed estimators in three contextual bandit environments. Our empirical results show that when the reward model is misspecified and the annotations are imperfect, it is most beneficial to use the annotations only in the DM portion of a DR estimator. Based on these theoretical and empirical insights, we provide a practical guide for using counterfactual annotations in different realistic settings.
Contextual Conservative Q-Learning for Offline Reinforcement Learning
Jan 16, 2023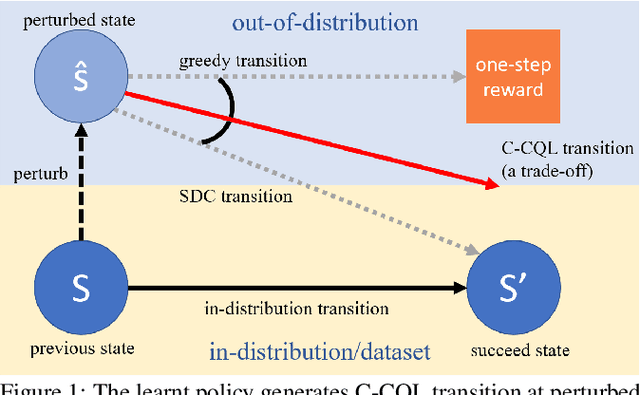

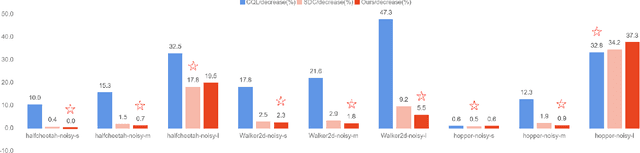

Offline reinforcement learning learns an effective policy on offline datasets without online interaction, and it attracts persistent research attention due to its potential of practical application. However, extrapolation error generated by distribution shift will still lead to the overestimation for those actions that transit to out-of-distribution(OOD) states, which degrades the reliability and robustness of the offline policy. In this paper, we propose Contextual Conservative Q-Learning(C-CQL) to learn a robustly reliable policy through the contextual information captured via an inverse dynamics model. With the supervision of the inverse dynamics model, it tends to learn a policy that generates stable transition at perturbed states, for the fact that pertuebed states are a common kind of OOD states. In this manner, we enable the learnt policy more likely to generate transition that destines to the empirical next state distributions of the offline dataset, i.e., robustly reliable transition. Besides, we theoretically reveal that C-CQL is the generalization of the Conservative Q-Learning(CQL) and aggressive State Deviation Correction(SDC). Finally, experimental results demonstrate the proposed C-CQL achieves the state-of-the-art performance in most environments of offline Mujoco suite and a noisy Mujoco setting.