 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Policy-Adaptive Image Guardrail: Benchmark and Method
Mar 01, 2026Accurate rejection of sensitive or harmful visual content, i.e., harmful image guardrail, is critical in many application scenarios. This task must continuously adapt to the evolving safety policies and content across various domains and over time. However, traditional classifiers, confined to fixed categories, require frequent retraining when new policies are introduced. Vision-language models (VLMs) offer a more adaptable and generalizable foundation for dynamic safety guardrails. Despite this potential, existing VLM-based safeguarding methods are typically trained and evaluated under only a fixed safety policy. We find that these models are heavily overfitted to the seen policy, fail to generalize to unseen policies, and even lose the basic instruction-following ability and general knowledge. To address this issue, in this paper we make two key contributions. First, we benchmark the cross-policy generalization performance of existing VLMs with SafeEditBench, a new evaluation suite. SafeEditBench leverages image-editing models to convert unsafe images into safe counterparts, producing policy-aligned datasets where each safe-unsafe image pair remains visually similar except for localized regions violating specific safety rules. Human annotators then provide accurate safe/unsafe labels under five distinct policies, enabling fine-grained assessment of policy-aware generalization. Second, we introduce SafeGuard-VL, a reinforcement learning-based method with verifiable rewards (RLVR) for robust unsafe-image guardrails. Instead of relying solely on supervised fine-tuning (SFT) under fixed policies, SafeGuard-VL explicitly optimizes the model with policy-grounded rewards, promoting verifiable adaptation across evolving policies. Extensive experiments verify the effectiveness of our method for unsafe image guardrails across various policies.
MIRROR: Manifold Ideal Reference ReconstructOR for Generalizable AI-Generated Image Detection
Feb 02, 2026High-fidelity generative models have narrowed the perceptual gap between synthetic and real images, posing serious threats to media security. Most existing AI-generated image (AIGI) detectors rely on artifact-based classification and struggle to generalize to evolving generative traces. In contrast, human judgment relies on stable real-world regularities, with deviations from the human cognitive manifold serving as a more generalizable signal of forgery. Motivated by this insight, we reformulate AIGI detection as a Reference-Comparison problem that verifies consistency with the real-image manifold rather than fitting specific forgery cues. We propose MIRROR (Manifold Ideal Reference ReconstructOR), a framework that explicitly encodes reality priors using a learnable discrete memory bank. MIRROR projects an input into a manifold-consistent ideal reference via sparse linear combination, and uses the resulting residuals as robust detection signals. To evaluate whether detectors reach the "superhuman crossover" required to replace human experts, we introduce the Human-AIGI benchmark, featuring a psychophysically curated human-imperceptible subset. Across 14 benchmarks, MIRROR consistently outperforms prior methods, achieving gains of 2.1% on six standard benchmarks and 8.1% on seven in-the-wild benchmarks. On Human-AIGI, MIRROR reaches 89.6% accuracy across 27 generators, surpassing both lay users and visual experts, and further approaching the human perceptual limit as pretrained backbones scale. The code is publicly available at: https://github.com/349793927/MIRROR
Agentic reinforcement learning empowers next-generation chemical language models for molecular design and synthesis
Jan 25, 2026Language models are revolutionizing the biochemistry domain, assisting scientists in drug design and chemical synthesis with high efficiency. Yet current approaches struggle between small language models prone to hallucination and limited knowledge retention, and large cloud-based language models plagued by privacy risks and high inference costs. To bridge this gap, we introduce ChemCRAFT, a novel framework leveraging agentic reinforcement learning to decouple chemical reasoning from knowledge storage. Instead of forcing the model to memorize vast chemical data, our approach empowers the language model to interact with a sandbox for precise information retrieval. This externalization of knowledge allows a locally deployable small model to achieve superior performance with minimal inference costs. To enable small language models for agent-calling ability, we build an agentic trajectory construction pipeline and a comprehensive chemical-agent sandbox. Based on sandbox interactions, we constructed ChemToolDataset, the first large-scale chemical tool trajectory dataset. Simultaneously, we propose SMILES-GRPO to build a dense chemical reward function, promoting the model's ability to call chemical agents. Evaluations across diverse aspects of drug design show that ChemCRAFT outperforms current cloud-based LLMs in molecular structure analysis, molecular optimization, and synthesis pathway prediction, demonstrating that scientific reasoning is not solely an emergent ability of model scale, but a learnable policy of tool orchestration. This work establishes a cost-effective and privacy-preserving paradigm for AI-aided chemistry, opening new avenues for accelerating molecular discovery with locally deployable agents.
Your One-Stop Solution for AI-Generated Video Detection
Jan 16, 2026Recent advances in generative modeling can create remarkably realistic synthetic videos, making it increasingly difficult for humans to distinguish them from real ones and necessitating reliable detection methods. However, two key limitations hinder the development of this field. \textbf{From the dataset perspective}, existing datasets are often limited in scale and constructed using outdated or narrowly scoped generative models, making it difficult to capture the diversity and rapid evolution of modern generative techniques. Moreover, the dataset construction process frequently prioritizes quantity over quality, neglecting essential aspects such as semantic diversity, scenario coverage, and technological representativeness. \textbf{From the benchmark perspective}, current benchmarks largely remain at the stage of dataset creation, leaving many fundamental issues and in-depth analysis yet to be systematically explored. Addressing this gap, we propose AIGVDBench, a benchmark designed to be comprehensive and representative, covering \textbf{31} state-of-the-art generation models and over \textbf{440,000} videos. By executing more than \textbf{1,500} evaluations on \textbf{33} existing detectors belonging to four distinct categories. This work presents \textbf{8 in-depth analyses} from multiple perspectives and identifies \textbf{4 novel findings} that offer valuable insights for future research. We hope this work provides a solid foundation for advancing the field of AI-generated video detection. Our benchmark is open-sourced at https://github.com/LongMa-2025/AIGVDBench.
Beyond Artifacts: Real-Centric Envelope Modeling for Reliable AI-Generated Image Detection
Dec 24, 2025The rapid progress of generative models has intensified the need for reliable and robust detection under real-world conditions. However, existing detectors often overfit to generator-specific artifacts and remain highly sensitive to real-world degradations. As generative architectures evolve and images undergo multi-round cross-platform sharing and post-processing (chain degradations), these artifact cues become obsolete and harder to detect. To address this, we propose Real-centric Envelope Modeling (REM), a new paradigm that shifts detection from learning generator artifacts to modeling the robust distribution of real images. REM introduces feature-level perturbations in self-reconstruction to generate near-real samples, and employs an envelope estimator with cross-domain consistency to learn a boundary enclosing the real image manifold. We further build RealChain, a comprehensive benchmark covering both open-source and commercial generators with simulated real-world degradation. Across eight benchmark evaluations, REM achieves an average improvement of 7.5% over state-of-the-art methods, and notably maintains exceptional generalization on the severely degraded RealChain benchmark, establishing a solid foundation for synthetic image detection under real-world conditions. The code and the RealChain benchmark will be made publicly available upon acceptance of the paper.
Can Understanding and Generation Truly Benefit Together -- or Just Coexist?
Sep 11, 2025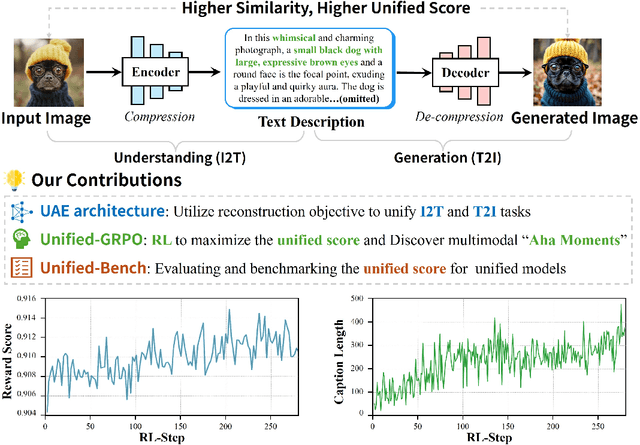
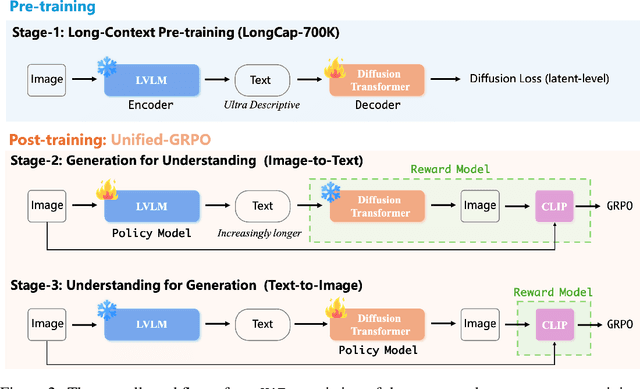
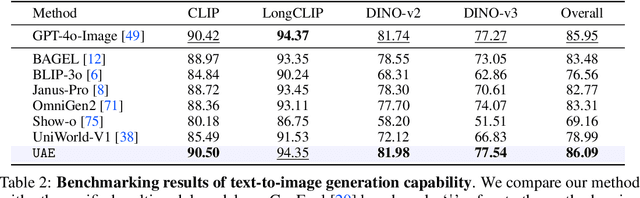
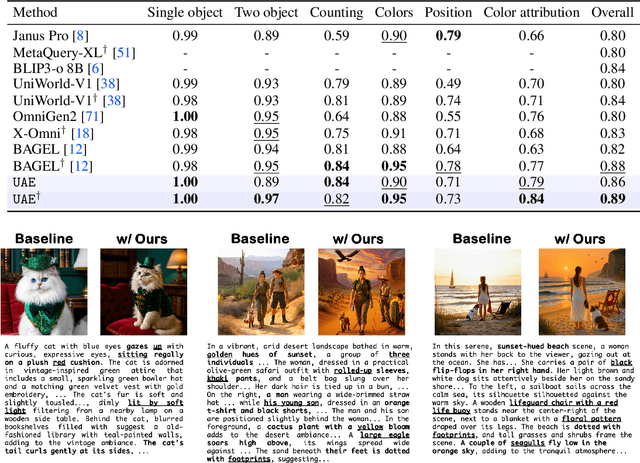
In this paper, we introduce an insightful paradigm through the Auto-Encoder lens-understanding as the encoder (I2T) that compresses images into text, and generation as the decoder (T2I) that reconstructs images from that text. Using reconstruction fidelity as the unified training objective, we enforce the coherent bidirectional information flow between the understanding and generation processes, bringing mutual gains. To implement this, we propose UAE, a novel framework for unified multimodal learning. We begin by pre-training the decoder with large-scale long-context image captions to capture fine-grained semantic and complex spatial relationships. We then propose Unified-GRPO via reinforcement learning (RL), which covers three stages: (1) A cold-start phase to gently initialize both encoder and decoder with a semantic reconstruction loss; (2) Generation for Understanding, where the encoder is trained to generate informative captions that maximize the decoder's reconstruction quality, enhancing its visual understanding; (3) Understanding for Generation, where the decoder is refined to reconstruct from these captions, forcing it to leverage every detail and improving its long-context instruction following and generation fidelity. For evaluation, we introduce Unified-Bench, the first benchmark tailored to assess the degree of unification of the UMMs. A surprising "aha moment" arises within the multimodal learning domain: as RL progresses, the encoder autonomously produces more descriptive captions, while the decoder simultaneously demonstrates a profound ability to understand these intricate descriptions, resulting in reconstructions of striking fidelity.
Echo-4o: Harnessing the Power of GPT-4o Synthetic Images for Improved Image Generation
Aug 13, 2025



Recently, GPT-4o has garnered significant attention for its strong performance in image generation, yet open-source models still lag behind. Several studies have explored distilling image data from GPT-4o to enhance open-source models, achieving notable progress. However, a key question remains: given that real-world image datasets already constitute a natural source of high-quality data, why should we use GPT-4o-generated synthetic data? In this work, we identify two key advantages of synthetic images. First, they can complement rare scenarios in real-world datasets, such as surreal fantasy or multi-reference image generation, which frequently occur in user queries. Second, they provide clean and controllable supervision. Real-world data often contains complex background noise and inherent misalignment between text descriptions and image content, whereas synthetic images offer pure backgrounds and long-tailed supervision signals, facilitating more accurate text-to-image alignment. Building on these insights, we introduce Echo-4o-Image, a 180K-scale synthetic dataset generated by GPT-4o, harnessing the power of synthetic image data to address blind spots in real-world coverage. Using this dataset, we fine-tune the unified multimodal generation baseline Bagel to obtain Echo-4o. In addition, we propose two new evaluation benchmarks for a more accurate and challenging assessment of image generation capabilities: GenEval++, which increases instruction complexity to mitigate score saturation, and Imagine-Bench, which focuses on evaluating both the understanding and generation of imaginative content. Echo-4o demonstrates strong performance across standard benchmarks. Moreover, applying Echo-4o-Image to other foundation models (e.g., OmniGen2, BLIP3-o) yields consistent performance gains across multiple metrics, highlighting the datasets strong transferability.
Beyond Chemical QA: Evaluating LLM's Chemical Reasoning with Modular Chemical Operations
May 27, 2025While large language models (LLMs) with Chain-of-Thought (CoT) reasoning excel in mathematics and coding, their potential for systematic reasoning in chemistry, a domain demanding rigorous structural analysis for real-world tasks like drug design and reaction engineering, remains untapped. Current benchmarks focus on simple knowledge retrieval, neglecting step-by-step reasoning required for complex tasks such as molecular optimization and reaction prediction. To address this, we introduce ChemCoTBench, a reasoning framework that bridges molecular structure understanding with arithmetic-inspired operations, including addition, deletion, and substitution, to formalize chemical problem-solving into transparent, step-by-step workflows. By treating molecular transformations as modular "chemical operations", the framework enables slow-thinking reasoning, mirroring the logic of mathematical proofs while grounding solutions in real-world chemical constraints. We evaluate models on two high-impact tasks: Molecular Property Optimization and Chemical Reaction Prediction. These tasks mirror real-world challenges while providing structured evaluability. By providing annotated datasets, a reasoning taxonomy, and baseline evaluations, ChemCoTBench bridges the gap between abstract reasoning methods and practical chemical discovery, establishing a foundation for advancing LLMs as tools for AI-driven scientific innovation.
ImgEdit: A Unified Image Editing Dataset and Benchmark
May 26, 2025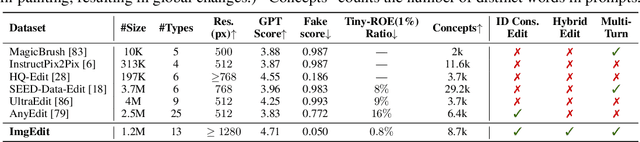
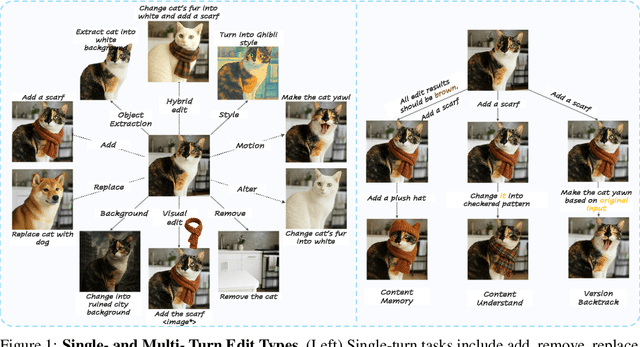
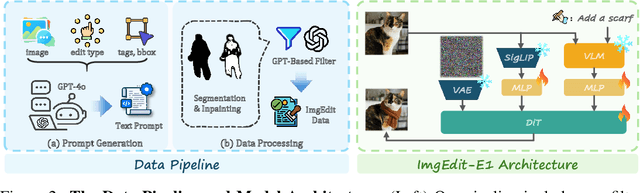

Recent advancements in generative models have enabled high-fidelity text-to-image generation. However, open-source image-editing models still lag behind their proprietary counterparts, primarily due to limited high-quality data and insufficient benchmarks. To overcome these limitations, we introduce ImgEdit, a large-scale, high-quality image-editing dataset comprising 1.2 million carefully curated edit pairs, which contain both novel and complex single-turn edits, as well as challenging multi-turn tasks. To ensure the data quality, we employ a multi-stage pipeline that integrates a cutting-edge vision-language model, a detection model, a segmentation model, alongside task-specific in-painting procedures and strict post-processing. ImgEdit surpasses existing datasets in both task novelty and data quality. Using ImgEdit, we train ImgEdit-E1, an editing model using Vision Language Model to process the reference image and editing prompt, which outperforms existing open-source models on multiple tasks, highlighting the value of ImgEdit and model design. For comprehensive evaluation, we introduce ImgEdit-Bench, a benchmark designed to evaluate image editing performance in terms of instruction adherence, editing quality, and detail preservation. It includes a basic testsuite, a challenging single-turn suite, and a dedicated multi-turn suite. We evaluate both open-source and proprietary models, as well as ImgEdit-E1, providing deep analysis and actionable insights into the current behavior of image-editing models. The source data are publicly available on https://github.com/PKU-YuanGroup/ImgEdit.
Guard Me If You Know Me: Protecting Specific Face-Identity from Deepfakes
May 26, 2025



Securing personal identity against deepfake attacks is increasingly critical in the digital age, especially for celebrities and political figures whose faces are easily accessible and frequently targeted. Most existing deepfake detection methods focus on general-purpose scenarios and often ignore the valuable prior knowledge of known facial identities, e.g., "VIP individuals" whose authentic facial data are already available. In this paper, we propose \textbf{VIPGuard}, a unified multimodal framework designed to capture fine-grained and comprehensive facial representations of a given identity, compare them against potentially fake or similar-looking faces, and reason over these comparisons to make accurate and explainable predictions. Specifically, our framework consists of three main stages. First, fine-tune a multimodal large language model (MLLM) to learn detailed and structural facial attributes. Second, we perform identity-level discriminative learning to enable the model to distinguish subtle differences between highly similar faces, including real and fake variations. Finally, we introduce user-specific customization, where we model the unique characteristics of the target face identity and perform semantic reasoning via MLLM to enable personalized and explainable deepfake detection. Our framework shows clear advantages over previous detection works, where traditional detectors mainly rely on low-level visual cues and provide no human-understandable explanations, while other MLLM-based models often lack a detailed understanding of specific face identities. To facilitate the evaluation of our method, we built a comprehensive identity-aware benchmark called \textbf{VIPBench} for personalized deepfake detection, involving the latest 7 face-swapping and 7 entire face synthesis techniques for generation.