 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoEval: Autonomous Evaluation of Generalist Robot Manipulation Policies in the Real World
Mar 31, 2025Scalable and reproducible policy evaluation has been a long-standing challenge in robot learning. Evaluations are critical to assess progress and build better policies, but evaluation in the real world, especially at a scale that would provide statistically reliable results, is costly in terms of human time and hard to obtain. Evaluation of increasingly generalist robot policies requires an increasingly diverse repertoire of evaluation environments, making the evaluation bottleneck even more pronounced. To make real-world evaluation of robotic policies more practical, we propose AutoEval, a system to autonomously evaluate generalist robot policies around the clock with minimal human intervention. Users interact with AutoEval by submitting evaluation jobs to the AutoEval queue, much like how software jobs are submitted with a cluster scheduling system, and AutoEval will schedule the policies for evaluation within a framework supplying automatic success detection and automatic scene resets. We show that AutoEval can nearly fully eliminate human involvement in the evaluation process, permitting around the clock evaluations, and the evaluation results correspond closely to ground truth evaluations conducted by hand. To facilitate the evaluation of generalist policies in the robotics community, we provide public access to multiple AutoEval scenes in the popular BridgeData robot setup with WidowX robot arms. In the future, we hope that AutoEval scenes can be set up across institutions to form a diverse and distributed evaluation network.
Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models
Feb 26, 2025Generalist robots that can perform a range of different tasks in open-world settings must be able to not only reason about the steps needed to accomplish their goals, but also process complex instructions, prompts, and even feedback during task execution. Intricate instructions (e.g., "Could you make me a vegetarian sandwich?" or "I don't like that one") require not just the ability to physically perform the individual steps, but the ability to situate complex commands and feedback in the physical world. In this work, we describe a system that uses vision-language models in a hierarchical structure, first reasoning over complex prompts and user feedback to deduce the most appropriate next step to fulfill the task, and then performing that step with low-level actions. In contrast to direct instruction following methods that can fulfill simple commands ("pick up the cup"), our system can reason through complex prompts and incorporate situated feedback during task execution ("that's not trash"). We evaluate our system across three robotic platforms, including single-arm, dual-arm, and dual-arm mobile robots, demonstrating its ability to handle tasks such as cleaning messy tables, making sandwiches, and grocery shopping.
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Jan 16, 2025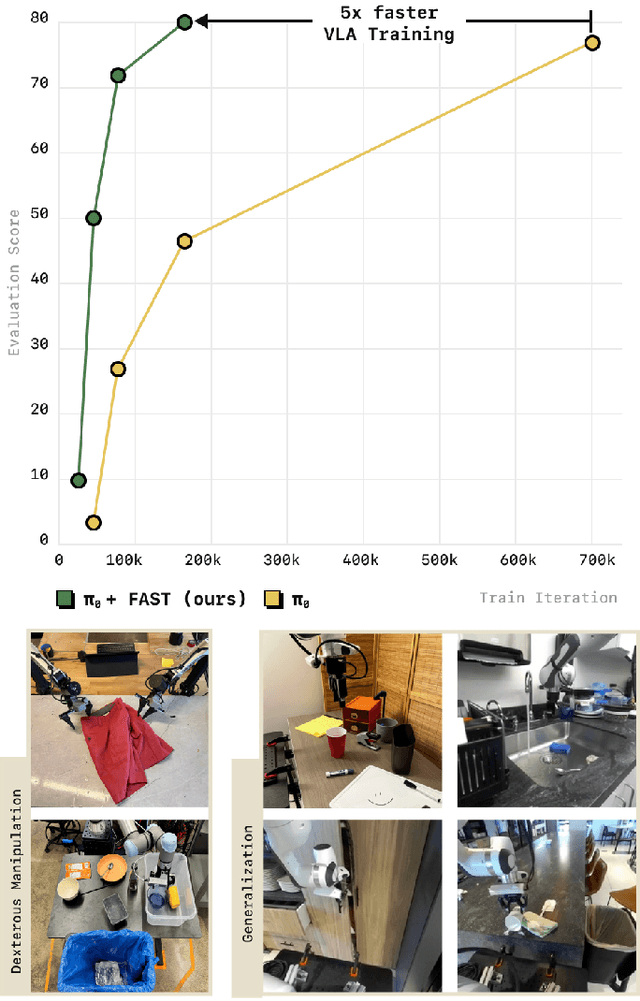

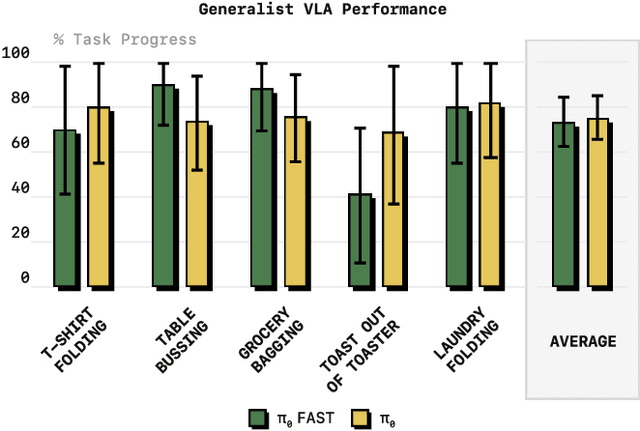
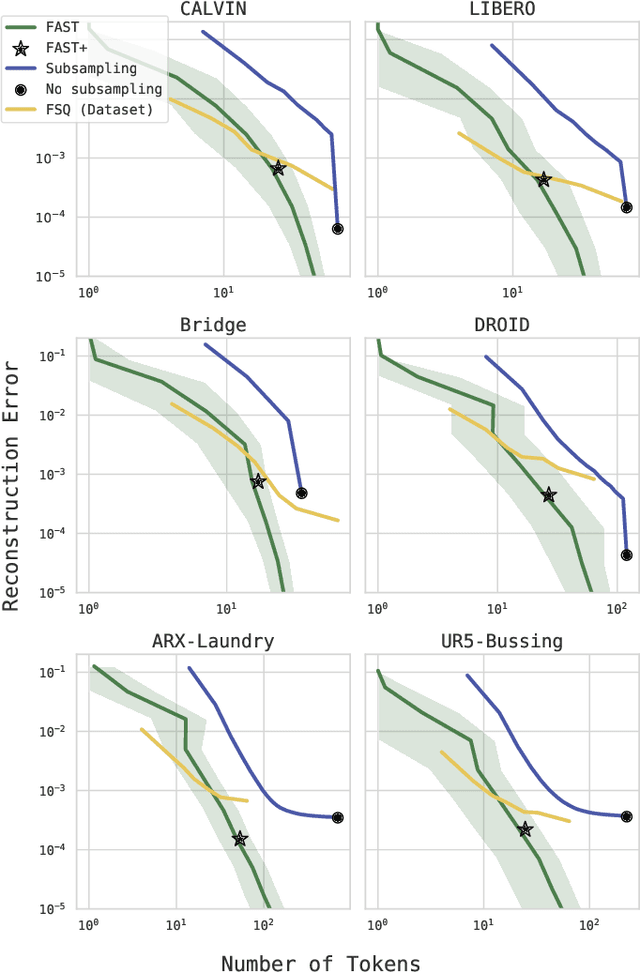
Autoregressive sequence models, such as Transformer-based vision-language action (VLA) policies, can be tremendously effective for capturing complex and generalizable robotic behaviors. However, such models require us to choose a tokenization of our continuous action signals, which determines how the discrete symbols predicted by the model map to continuous robot actions. We find that current approaches for robot action tokenization, based on simple per-dimension, per-timestep binning schemes, typically perform poorly when learning dexterous skills from high-frequency robot data. To address this challenge, we propose a new compression-based tokenization scheme for robot actions, based on the discrete cosine transform. Our tokenization approach, Frequency-space Action Sequence Tokenization (FAST), enables us to train autoregressive VLAs for highly dexterous and high-frequency tasks where standard discretization methods fail completely. Based on FAST, we release FAST+, a universal robot action tokenizer, trained on 1M real robot action trajectories. It can be used as a black-box tokenizer for a wide range of robot action sequences, with diverse action spaces and control frequencies. Finally, we show that, when combined with the pi0 VLA, our method can scale to training on 10k hours of robot data and match the performance of diffusion VLAs, while reducing training time by up to 5x.
$π_0$: A Vision-Language-Action Flow Model for General Robot Control
Oct 31, 2024



Robot learning holds tremendous promise to unlock the full potential of flexible, general, and dexterous robot systems, as well as to address some of the deepest questions in artificial intelligence. However, bringing robot learning to the level of generality required for effective real-world systems faces major obstacles in terms of data, generalization, and robustness. In this paper, we discuss how generalist robot policies (i.e., robot foundation models) can address these challenges, and how we can design effective generalist robot policies for complex and highly dexterous tasks. We propose a novel flow matching architecture built on top of a pre-trained vision-language model (VLM) to inherit Internet-scale semantic knowledge. We then discuss how this model can be trained on a large and diverse dataset from multiple dexterous robot platforms, including single-arm robots, dual-arm robots, and mobile manipulators. We evaluate our model in terms of its ability to perform tasks in zero shot after pre-training, follow language instructions from people and from a high-level VLM policy, and its ability to acquire new skills via fine-tuning. Our results cover a wide variety of tasks, such as laundry folding, table cleaning, and assembling boxes.
Re-Mix: Optimizing Data Mixtures for Large Scale Imitation Learning
Aug 26, 2024



Increasingly large imitation learning datasets are being collected with the goal of training foundation models for robotics. However, despite the fact that data selection has been of utmost importance in vision and natural language processing, little work in robotics has questioned what data such models should actually be trained on. In this work we investigate how to weigh different subsets or ``domains'' of robotics datasets for robot foundation model pre-training. Concrete, we use distributionally robust optimization (DRO) to maximize worst-case performance across all possible downstream domains. Our method, Re-Mix, addresses the wide range of challenges that arise when applying DRO to robotics datasets including variability in action spaces and dynamics across different datasets. Re-Mix employs early stopping, action normalization, and discretization to counteract these issues. Through extensive experimentation on the largest open-source robot manipulation dataset, the Open X-Embodiment dataset, we demonstrate that data curation can have an outsized impact on downstream performance. Specifically, domain weights learned by Re-Mix outperform uniform weights by 38\% on average and outperform human-selected weights by 32\% on datasets used to train existing generalist robot policies, specifically the RT-X models.
Affordance-Guided Reinforcement Learning via Visual Prompting
Jul 14, 2024Robots equipped with reinforcement learning (RL) have the potential to learn a wide range of skills solely from a reward signal. However, obtaining a robust and dense reward signal for general manipulation tasks remains a challenge. Existing learning-based approaches require significant data, such as demonstrations or examples of success and failure, to learn task-specific reward functions. Recently, there is also a growing adoption of large multi-modal foundation models for robotics. These models can perform visual reasoning in physical contexts and generate coarse robot motions for various manipulation tasks. Motivated by this range of capability, in this work, we propose and study rewards shaped by vision-language models (VLMs). State-of-the-art VLMs have demonstrated an impressive ability to reason about affordances through keypoints in zero-shot, and we leverage this to define dense rewards for robotic learning. On a real-world manipulation task specified by natural language description, we find that these rewards improve the sample efficiency of autonomous RL and enable successful completion of the task in 20K online finetuning steps. Additionally, we demonstrate the robustness of the approach to reductions in the number of in-domain demonstrations used for pretraining, reaching comparable performance in 35K online finetuning steps.
OpenVLA: An Open-Source Vision-Language-Action Model
Jun 13, 2024



Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new behaviors from scratch, we can fine-tune such vision-language-action (VLA) models to obtain robust, generalizable policies for visuomotor control. Yet, widespread adoption of VLAs for robotics has been challenging as 1) existing VLAs are largely closed and inaccessible to the public, and 2) prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption. Addressing these challenges, we introduce OpenVLA, a 7B-parameter open-source VLA trained on a diverse collection of 970k real-world robot demonstrations. OpenVLA builds on a Llama 2 language model combined with a visual encoder that fuses pretrained features from DINOv2 and SigLIP. As a product of the added data diversity and new model components, OpenVLA demonstrates strong results for generalist manipulation, outperforming closed models such as RT-2-X (55B) by 16.5% in absolute task success rate across 29 tasks and multiple robot embodiments, with 7x fewer parameters. We further show that we can effectively fine-tune OpenVLA for new settings, with especially strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities, and outperform expressive from-scratch imitation learning methods such as Diffusion Policy by 20.4%. We also explore compute efficiency; as a separate contribution, we show that OpenVLA can be fine-tuned on consumer GPUs via modern low-rank adaptation methods and served efficiently via quantization without a hit to downstream success rate. Finally, we release model checkpoints, fine-tuning notebooks, and our PyTorch codebase with built-in support for training VLAs at scale on Open X-Embodiment datasets.
Octo: An Open-Source Generalist Robot Policy
May 20, 2024



Large policies pretrained on diverse robot datasets have the potential to transform robotic learning: instead of training new policies from scratch, such generalist robot policies may be finetuned with only a little in-domain data, yet generalize broadly. However, to be widely applicable across a range of robotic learning scenarios, environments, and tasks, such policies need to handle diverse sensors and action spaces, accommodate a variety of commonly used robotic platforms, and finetune readily and efficiently to new domains. In this work, we aim to lay the groundwork for developing open-source, widely applicable, generalist policies for robotic manipulation. As a first step, we introduce Octo, a large transformer-based policy trained on 800k trajectories from the Open X-Embodiment dataset, the largest robot manipulation dataset to date. It can be instructed via language commands or goal images and can be effectively finetuned to robot setups with new sensory inputs and action spaces within a few hours on standard consumer GPUs. In experiments across 9 robotic platforms, we demonstrate that Octo serves as a versatile policy initialization that can be effectively finetuned to new observation and action spaces. We also perform detailed ablations of design decisions for the Octo model, from architecture to training data, to guide future research on building generalist robot models.
Evaluating Real-World Robot Manipulation Policies in Simulation
May 09, 2024



The field of robotics has made significant advances towards generalist robot manipulation policies. However, real-world evaluation of such policies is not scalable and faces reproducibility challenges, which are likely to worsen as policies broaden the spectrum of tasks they can perform. We identify control and visual disparities between real and simulated environments as key challenges for reliable simulated evaluation and propose approaches for mitigating these gaps without needing to craft full-fidelity digital twins of real-world environments. We then employ these approaches to create SIMPLER, a collection of simulated environments for manipulation policy evaluation on common real robot setups. Through paired sim-and-real evaluations of manipulation policies, we demonstrate strong correlation between policy performance in SIMPLER environments and in the real world. Additionally, we find that SIMPLER evaluations accurately reflect real-world policy behavior modes such as sensitivity to various distribution shifts. We open-source all SIMPLER environments along with our workflow for creating new environments at https://simpler-env.github.io to facilitate research on general-purpose manipulation policies and simulated evaluation frameworks.
Yell At Your Robot: Improving On-the-Fly from Language Corrections
Mar 19, 2024Hierarchical policies that combine language and low-level control have been shown to perform impressively long-horizon robotic tasks, by leveraging either zero-shot high-level planners like pretrained language and vision-language models (LLMs/VLMs) or models trained on annotated robotic demonstrations. However, for complex and dexterous skills, attaining high success rates on long-horizon tasks still represents a major challenge -- the longer the task is, the more likely it is that some stage will fail. Can humans help the robot to continuously improve its long-horizon task performance through intuitive and natural feedback? In this paper, we make the following observation: high-level policies that index into sufficiently rich and expressive low-level language-conditioned skills can be readily supervised with human feedback in the form of language corrections. We show that even fine-grained corrections, such as small movements ("move a bit to the left"), can be effectively incorporated into high-level policies, and that such corrections can be readily obtained from humans observing the robot and making occasional suggestions. This framework enables robots not only to rapidly adapt to real-time language feedback, but also incorporate this feedback into an iterative training scheme that improves the high-level policy's ability to correct errors in both low-level execution and high-level decision-making purely from verbal feedback. Our evaluation on real hardware shows that this leads to significant performance improvement in long-horizon, dexterous manipulation tasks without the need for any additional teleoperation. Videos and code are available at https://yay-robot.github.io/.