 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDH-RAG: A Dynamic Historical Context-Powered Retrieval-Augmented Generation Method for Multi-Turn Dialogue
Feb 19, 2025Retrieval-Augmented Generation (RAG) systems have shown substantial benefits in applications such as question answering and multi-turn dialogue \citep{lewis2020retrieval}. However, traditional RAG methods, while leveraging static knowledge bases, often overlook the potential of dynamic historical information in ongoing conversations. To bridge this gap, we introduce DH-RAG, a Dynamic Historical Context-Powered Retrieval-Augmented Generation Method for Multi-Turn Dialogue. DH-RAG is inspired by human cognitive processes that utilize both long-term memory and immediate historical context in conversational responses \citep{stafford1987conversational}. DH-RAG is structured around two principal components: a History-Learning based Query Reconstruction Module, designed to generate effective queries by synthesizing current and prior interactions, and a Dynamic History Information Updating Module, which continually refreshes historical context throughout the dialogue. The center of DH-RAG is a Dynamic Historical Information database, which is further refined by three strategies within the Query Reconstruction Module: Historical Query Clustering, Hierarchical Matching, and Chain of Thought Tracking. Experimental evaluations show that DH-RAG significantly surpasses conventional models on several benchmarks, enhancing response relevance, coherence, and dialogue quality.
Corrupted but Not Broken: Rethinking the Impact of Corrupted Data in Visual Instruction Tuning
Feb 18, 2025Visual Instruction Tuning (VIT) enhances Multimodal Large Language Models (MLLMs) but it is hindered by corrupted datasets containing hallucinated content, incorrect responses, and poor OCR quality. While prior works focus on dataset refinement through high-quality data collection or rule-based filtering, they are costly or limited to specific types of corruption. To deeply understand how corrupted data affects MLLMs, in this paper, we systematically investigate this issue and find that while corrupted data degrades the performance of MLLMs, its effects are largely superficial in that the performance of MLLMs can be largely restored by either disabling a small subset of parameters or post-training with a small amount of clean data. Additionally, corrupted MLLMs exhibit improved ability to distinguish clean samples from corrupted ones, enabling the dataset cleaning without external help. Based on those insights, we propose a corruption-robust training paradigm combining self-validation and post-training, which significantly outperforms existing corruption mitigation strategies.
UnitCoder: Scalable Iterative Code Synthesis with Unit Test Guidance
Feb 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks, yet code generation remains a major challenge. Current approaches for obtaining high-quality code data primarily focus on (i) collecting large-scale pre-training data and (ii) synthesizing instruction data through prompt engineering with powerful models. While pre-training data faces quality consistency issues, instruction-based synthesis suffers from limited instruction diversity and inherent biases of LLMs. To address this gap, we introduce UnitCoder, a systematic pipeline leveraging model-generated unit tests to both guide and validate the code generation process. Combined with large-scale package-based retrieval from pre-training corpus, we generate a dataset of 500K+ verifiable programs containing diverse API calls. Evaluations on multiple Python benchmarks (BigCodeBench, HumanEval, MBPP) demonstrate that models fine-tuned on our synthetic data exhibit consistent performance improvements. Notably, Llama3.1-8B and InternLM2.5-7B improve from 31\% and 28\% to 40\% and 39\% success rates on BigCodeBench, respectively. Our work presents a scalable approach that leverages model-generated unit tests to guide the synthesis of high-quality code data from pre-training corpora, demonstrating the potential for producing diverse and high-quality post-training data at scale. All code and data will be released (https://github.com).
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Feb 10, 2025Reasoning abilities, especially those for solving complex math problems, are crucial components of general intelligence. Recent advances by proprietary companies, such as o-series models of OpenAI, have made remarkable progress on reasoning tasks. However, the complete technical details remain unrevealed, and the techniques that are believed certainly to be adopted are only reinforcement learning (RL) and the long chain of thoughts. This paper proposes a new RL framework, termed OREAL, to pursue the performance limit that can be achieved through \textbf{O}utcome \textbf{RE}w\textbf{A}rd-based reinforcement \textbf{L}earning for mathematical reasoning tasks, where only binary outcome rewards are easily accessible. We theoretically prove that behavior cloning on positive trajectories from best-of-N (BoN) sampling is sufficient to learn the KL-regularized optimal policy in binary feedback environments. This formulation further implies that the rewards of negative samples should be reshaped to ensure the gradient consistency between positive and negative samples. To alleviate the long-existing difficulties brought by sparse rewards in RL, which are even exacerbated by the partial correctness of the long chain of thought for reasoning tasks, we further apply a token-level reward model to sample important tokens in reasoning trajectories for learning. With OREAL, for the first time, a 7B model can obtain 94.0 pass@1 accuracy on MATH-500 through RL, being on par with 32B models. OREAL-32B also surpasses previous 32B models trained by distillation with 95.0 pass@1 accuracy on MATH-500. Our investigation also indicates the importance of initial policy models and training queries for RL. Code, models, and data will be released to benefit future research\footnote{https://github.com/InternLM/OREAL}.
Emilia: A Large-Scale, Extensive, Multilingual, and Diverse Dataset for Speech Generation
Jan 27, 2025Recent advancements in speech generation have been driven by the large-scale training datasets. However, current models fall short of capturing the spontaneity and variability inherent in real-world human speech, due to their reliance on audiobook datasets limited to formal read-aloud speech styles. To bridge this gap, we introduce Emilia-Pipe, an open-source preprocessing pipeline to extract high-quality training data from valuable yet underexplored in-the-wild data that capture spontaneous human speech in real-world contexts. By leveraging Emilia-Pipe, we construct Emilia, the first multilingual speech generation dataset derived from in-the-wild speech data. This dataset comprises over 101k hours of speech across six languages: English, Chinese, German, French, Japanese, and Korean. Besides, we expand Emilia to Emilia-Large, a dataset exceeding 216k hours, making it the largest open-source speech generation dataset available. Extensive experiments demonstrate that Emilia significantly outperforms traditional audiobook datasets in generating spontaneous and human-like speech, showcasing superior performance in capturing diverse speaker timbre and speaking styles of real-world human speech. Furthermore, this work underscores the importance of scaling dataset size to advance speech generation research and validates the effectiveness of Emilia for both multilingual and crosslingual speech generation.
LoRAGuard: An Effective Black-box Watermarking Approach for LoRAs
Jan 26, 2025LoRA (Low-Rank Adaptation) has achieved remarkable success in the parameter-efficient fine-tuning of large models. The trained LoRA matrix can be integrated with the base model through addition or negation operation to improve performance on downstream tasks. However, the unauthorized use of LoRAs to generate harmful content highlights the need for effective mechanisms to trace their usage. A natural solution is to embed watermarks into LoRAs to detect unauthorized misuse. However, existing methods struggle when multiple LoRAs are combined or negation operation is applied, as these can significantly degrade watermark performance. In this paper, we introduce LoRAGuard, a novel black-box watermarking technique for detecting unauthorized misuse of LoRAs. To support both addition and negation operations, we propose the Yin-Yang watermark technique, where the Yin watermark is verified during negation operation and the Yang watermark during addition operation. Additionally, we propose a shadow-model-based watermark training approach that significantly improves effectiveness in scenarios involving multiple integrated LoRAs. Extensive experiments on both language and diffusion models show that LoRAGuard achieves nearly 100% watermark verification success and demonstrates strong effectiveness.
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Jan 21, 2025


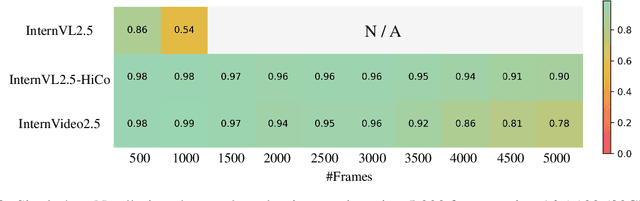
This paper aims to improve the performance of video multimodal large language models (MLLM) via long and rich context (LRC) modeling. As a result, we develop a new version of InternVideo2.5 with a focus on enhancing the original MLLMs' ability to perceive fine-grained details and capture long-form temporal structure in videos. Specifically, our approach incorporates dense vision task annotations into MLLMs using direct preference optimization and develops compact spatiotemporal representations through adaptive hierarchical token compression. Experimental results demonstrate this unique design of LRC greatly improves the results of video MLLM in mainstream video understanding benchmarks (short & long), enabling the MLLM to memorize significantly longer video inputs (at least 6x longer than the original), and master specialized vision capabilities like object tracking and segmentation. Our work highlights the importance of multimodal context richness (length and fineness) in empowering MLLM's innate abilites (focus and memory), providing new insights for future research on video MLLM. Code and models are available at https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2.5
Condor: Enhance LLM Alignment with Knowledge-Driven Data Synthesis and Refinement
Jan 21, 2025



The quality of Supervised Fine-Tuning (SFT) data plays a critical role in enhancing the conversational capabilities of Large Language Models (LLMs). However, as LLMs become more advanced, the availability of high-quality human-annotated SFT data has become a significant bottleneck, necessitating a greater reliance on synthetic training data. In this work, we introduce Condor, a novel two-stage synthetic data generation framework that incorporates World Knowledge Tree and Self-Reflection Refinement to produce high-quality SFT data at scale. Our experimental results demonstrate that a base model fine-tuned on only 20K Condor-generated samples achieves superior performance compared to counterparts. The additional refinement stage in Condor further enables iterative self-improvement for LLMs at various scales (up to 72B), validating the effectiveness of our approach. Furthermore, our investigation into the scaling for synthetic data in post-training reveals substantial unexplored potential for performance improvements, opening promising avenues for future research.
InternLM-XComposer2.5-Reward: A Simple Yet Effective Multi-Modal Reward Model
Jan 21, 2025



Despite the promising performance of Large Vision Language Models (LVLMs) in visual understanding, they occasionally generate incorrect outputs. While reward models (RMs) with reinforcement learning or test-time scaling offer the potential for improving generation quality, a critical gap remains: publicly available multi-modal RMs for LVLMs are scarce, and the implementation details of proprietary models are often unclear. We bridge this gap with InternLM-XComposer2.5-Reward (IXC-2.5-Reward), a simple yet effective multi-modal reward model that aligns LVLMs with human preferences. To ensure the robustness and versatility of IXC-2.5-Reward, we set up a high-quality multi-modal preference corpus spanning text, image, and video inputs across diverse domains, such as instruction following, general understanding, text-rich documents, mathematical reasoning, and video understanding. IXC-2.5-Reward achieves excellent results on the latest multi-modal reward model benchmark and shows competitive performance on text-only reward model benchmarks. We further demonstrate three key applications of IXC-2.5-Reward: (1) Providing a supervisory signal for RL training. We integrate IXC-2.5-Reward with Proximal Policy Optimization (PPO) yields IXC-2.5-Chat, which shows consistent improvements in instruction following and multi-modal open-ended dialogue; (2) Selecting the best response from candidate responses for test-time scaling; and (3) Filtering outlier or noisy samples from existing image and video instruction tuning training data. To ensure reproducibility and facilitate further research, we have open-sourced all model weights and training recipes at https://github.com/InternLM/InternLM-XComposer
SWE-Fixer: Training Open-Source LLMs for Effective and Efficient GitHub Issue Resolution
Jan 09, 2025



Large Language Models (LLMs) have demonstrated remarkable proficiency across a variety of complex tasks. One significant application of LLMs is in tackling software engineering challenges, particularly in resolving real-world tasks on GitHub by fixing code based on the issues reported by the users. However, many current approaches rely on proprietary LLMs, which limits reproducibility, accessibility, and transparency. The critical components of LLMs for addressing software engineering issues and how their capabilities can be effectively enhanced remain unclear. To address these challenges, we introduce SWE-Fixer, a novel open-source LLM designed to effectively and efficiently resolve GitHub issues. SWE-Fixer comprises two essential modules: a code file retrieval module and a code editing module. The retrieval module employs BM25 along with a lightweight LLM model to achieve coarse-to-fine file retrieval. Subsequently, the code editing module utilizes the other LLM model to generate patches for the identified files. Then, to mitigate the lack of publicly available datasets, we compile an extensive dataset that includes 110K GitHub issues along with their corresponding patches, and train the two modules of SWE-Fixer separately. We assess our approach on the SWE-Bench Lite and Verified benchmarks, achieving state-of-the-art performance among open-source models with scores of 23.3% and 30.2%, respectively. These outcomes highlight the efficacy of our approach. We will make our model, dataset, and code publicly available at https://github.com/InternLM/SWE-Fixer.