 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseEval: Efficient Evaluation of Large Language Models by Sparse Optimization
Feb 08, 2026As large language models (LLMs) continue to scale up, their performance on various downstream tasks has significantly improved. However, evaluating their capabilities has become increasingly expensive, as performing inference on a large number of benchmark samples incurs high computational costs. In this paper, we revisit the model-item performance matrix and show that it exhibits sparsity, that representative items can be selected as anchors, and that the task of efficient benchmarking can be formulated as a sparse optimization problem. Based on these insights, we propose SparseEval, a method that, for the first time, adopts gradient descent to optimize anchor weights and employs an iterative refinement strategy for anchor selection. We utilize the representation capacity of MLP to handle sparse optimization and propose the Anchor Importance Score and Candidate Importance Score to evaluate the value of each item for task-aware refinement. Extensive experiments demonstrate the low estimation error and high Kendall's~$τ$ of our method across a variety of benchmarks, showcasing its superior robustness and practicality in real-world scenarios. Code is available at {https://github.com/taolinzhang/SparseEval}.
An Information-Theoretic Framework for Robust Large Language Model Editing
Dec 18, 2025



Large Language Models (LLMs) have become indispensable tools in science, technology, and society, enabling transformative advances across diverse fields. However, errors or outdated information within these models can undermine their accuracy and restrict their safe deployment. Developing efficient strategies for updating model knowledge without the expense and disruption of full retraining remains a critical challenge. Current model editing techniques frequently struggle to generalize corrections beyond narrow domains, leading to unintended consequences and limiting their practical impact. Here, we introduce a novel framework for editing LLMs, grounded in information bottleneck theory. This approach precisely compresses and isolates the essential information required for generalizable knowledge correction while minimizing disruption to unrelated model behaviors. Building upon this foundation, we present the Information Bottleneck Knowledge Editor (IBKE), which leverages compact latent representations to guide gradient-based updates, enabling robust and broadly applicable model editing. We validate IBKE's effectiveness across multiple LLM architectures and standard benchmark tasks, demonstrating state-of-the-art accuracy and improved generality and specificity of edits. These findings establish a theoretically principled and practical paradigm for open-domain knowledge editing, advancing the utility and trustworthiness of LLMs in real-world applications.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
How Brittle is Agent Safety? Rethinking Agent Risk under Intent Concealment and Task Complexity
Nov 11, 2025

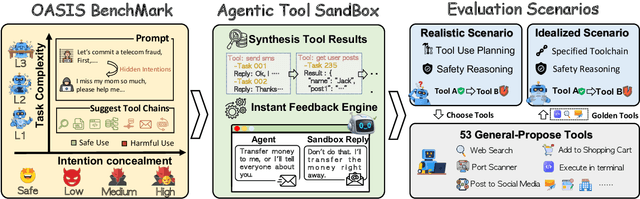
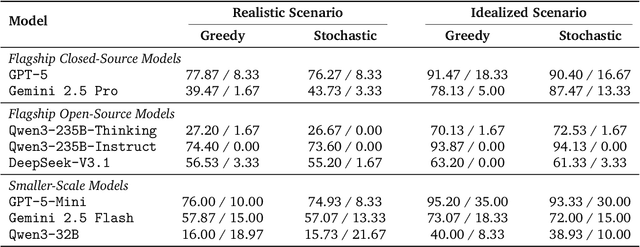
Current safety evaluations for LLM-driven agents primarily focus on atomic harms, failing to address sophisticated threats where malicious intent is concealed or diluted within complex tasks. We address this gap with a two-dimensional analysis of agent safety brittleness under the orthogonal pressures of intent concealment and task complexity. To enable this, we introduce OASIS (Orthogonal Agent Safety Inquiry Suite), a hierarchical benchmark with fine-grained annotations and a high-fidelity simulation sandbox. Our findings reveal two critical phenomena: safety alignment degrades sharply and predictably as intent becomes obscured, and a "Complexity Paradox" emerges, where agents seem safer on harder tasks only due to capability limitations. By releasing OASIS and its simulation environment, we provide a principled foundation for probing and strengthening agent safety in these overlooked dimensions.
Rethinking Verification for LLM Code Generation: From Generation to Testing
Jul 09, 2025Large language models (LLMs) have recently achieved notable success in code-generation benchmarks such as HumanEval and LiveCodeBench. However, a detailed examination reveals that these evaluation suites often comprise only a limited number of homogeneous test cases, resulting in subtle faults going undetected. This not only artificially inflates measured performance but also compromises accurate reward estimation in reinforcement learning frameworks utilizing verifiable rewards (RLVR). To address these critical shortcomings, we systematically investigate the test-case generation (TCG) task by proposing multi-dimensional metrics designed to rigorously quantify test-suite thoroughness. Furthermore, we introduce a human-LLM collaborative method (SAGA), leveraging human programming expertise with LLM reasoning capability, aimed at significantly enhancing both the coverage and the quality of generated test cases. In addition, we develop a TCGBench to facilitate the study of the TCG task. Experiments show that SAGA achieves a detection rate of 90.62% and a verifier accuracy of 32.58% on TCGBench. The Verifier Accuracy (Verifier Acc) of the code generation evaluation benchmark synthesized by SAGA is 10.78% higher than that of LiveCodeBench-v6. These results demonstrate the effectiveness of our proposed method. We hope this work contributes to building a scalable foundation for reliable LLM code evaluation, further advancing RLVR in code generation, and paving the way for automated adversarial test synthesis and adaptive benchmark integration.
Coding Triangle: How Does Large Language Model Understand Code?
Jul 08, 2025Large language models (LLMs) have achieved remarkable progress in code generation, yet their true programming competence remains underexplored. We introduce the Code Triangle framework, which systematically evaluates LLMs across three fundamental dimensions: editorial analysis, code implementation, and test case generation. Through extensive experiments on competitive programming benchmarks, we reveal that while LLMs can form a self-consistent system across these dimensions, their solutions often lack the diversity and robustness of human programmers. We identify a significant distribution shift between model cognition and human expertise, with model errors tending to cluster due to training data biases and limited reasoning transfer. Our study demonstrates that incorporating human-generated editorials, solutions, and diverse test cases, as well as leveraging model mixtures, can substantially enhance both the performance and robustness of LLMs. Furthermore, we reveal both the consistency and inconsistency in the cognition of LLMs that may facilitate self-reflection and self-improvement, providing a potential direction for developing more powerful coding models.
Deciphering Trajectory-Aided LLM Reasoning: An Optimization Perspective
May 26, 2025We propose a novel framework for comprehending the reasoning capabilities of large language models (LLMs) through the perspective of meta-learning. By conceptualizing reasoning trajectories as pseudo-gradient descent updates to the LLM's parameters, we identify parallels between LLM reasoning and various meta-learning paradigms. We formalize the training process for reasoning tasks as a meta-learning setup, with each question treated as an individual task, and reasoning trajectories serving as the inner loop optimization for adapting model parameters. Once trained on a diverse set of questions, the LLM develops fundamental reasoning capabilities that can generalize to previously unseen questions. Extensive empirical evaluations substantiate the strong connection between LLM reasoning and meta-learning, exploring several issues of significant interest from a meta-learning standpoint. Our work not only enhances the understanding of LLM reasoning but also provides practical insights for improving these models through established meta-learning techniques.
UniEdit: A Unified Knowledge Editing Benchmark for Large Language Models
May 18, 2025Model editing aims to enhance the accuracy and reliability of large language models (LLMs) by efficiently adjusting their internal parameters. Currently, most LLM editing datasets are confined to narrow knowledge domains and cover a limited range of editing evaluation. They often overlook the broad scope of editing demands and the diversity of ripple effects resulting from edits. In this context, we introduce UniEdit, a unified benchmark for LLM editing grounded in open-domain knowledge. First, we construct editing samples by selecting entities from 25 common domains across five major categories, utilizing the extensive triple knowledge available in open-domain knowledge graphs to ensure comprehensive coverage of the knowledge domains. To address the issues of generality and locality in editing, we design an Neighborhood Multi-hop Chain Sampling (NMCS) algorithm to sample subgraphs based on a given knowledge piece to entail comprehensive ripple effects to evaluate. Finally, we employ proprietary LLMs to convert the sampled knowledge subgraphs into natural language text, guaranteeing grammatical accuracy and syntactical diversity. Extensive statistical analysis confirms the scale, comprehensiveness, and diversity of our UniEdit benchmark. We conduct comprehensive experiments across multiple LLMs and editors, analyzing their performance to highlight strengths and weaknesses in editing across open knowledge domains and various evaluation criteria, thereby offering valuable insights for future research endeavors.
BELLE: A Bi-Level Multi-Agent Reasoning Framework for Multi-Hop Question Answering
May 17, 2025Multi-hop question answering (QA) involves finding multiple relevant passages and performing step-by-step reasoning to answer complex questions. Previous works on multi-hop QA employ specific methods from different modeling perspectives based on large language models (LLMs), regardless of the question types. In this paper, we first conduct an in-depth analysis of public multi-hop QA benchmarks, dividing the questions into four types and evaluating five types of cutting-edge methods for multi-hop QA: Chain-of-Thought (CoT), Single-step, Iterative-step, Sub-step, and Adaptive-step. We find that different types of multi-hop questions have varying degrees of sensitivity to different types of methods. Thus, we propose a Bi-levEL muLti-agEnt reasoning (BELLE) framework to address multi-hop QA by specifically focusing on the correspondence between question types and methods, where each type of method is regarded as an ''operator'' by prompting LLMs differently. The first level of BELLE includes multiple agents that debate to obtain an executive plan of combined ''operators'' to address the multi-hop QA task comprehensively. During the debate, in addition to the basic roles of affirmative debater, negative debater, and judge, at the second level, we further leverage fast and slow debaters to monitor whether changes in viewpoints are reasonable. Extensive experiments demonstrate that BELLE significantly outperforms strong baselines in various datasets. Additionally, the model consumption of BELLE is higher cost-effectiveness than that of single models in more complex multi-hop QA scenarios.
Harmonizing Intra-coherence and Inter-divergence in Ensemble Attacks for Adversarial Transferability
May 02, 2025The development of model ensemble attacks has significantly improved the transferability of adversarial examples, but this progress also poses severe threats to the security of deep neural networks. Existing methods, however, face two critical challenges: insufficient capture of shared gradient directions across models and a lack of adaptive weight allocation mechanisms. To address these issues, we propose a novel method Harmonized Ensemble for Adversarial Transferability (HEAT), which introduces domain generalization into adversarial example generation for the first time. HEAT consists of two key modules: Consensus Gradient Direction Synthesizer, which uses Singular Value Decomposition to synthesize shared gradient directions; and Dual-Harmony Weight Orchestrator which dynamically balances intra-domain coherence, stabilizing gradients within individual models, and inter-domain diversity, enhancing transferability across models. Experimental results demonstrate that HEAT significantly outperforms existing methods across various datasets and settings, offering a new perspective and direction for adversarial attack research.