 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmilia: A Large-Scale, Extensive, Multilingual, and Diverse Dataset for Speech Generation
Jan 27, 2025Recent advancements in speech generation have been driven by the large-scale training datasets. However, current models fall short of capturing the spontaneity and variability inherent in real-world human speech, due to their reliance on audiobook datasets limited to formal read-aloud speech styles. To bridge this gap, we introduce Emilia-Pipe, an open-source preprocessing pipeline to extract high-quality training data from valuable yet underexplored in-the-wild data that capture spontaneous human speech in real-world contexts. By leveraging Emilia-Pipe, we construct Emilia, the first multilingual speech generation dataset derived from in-the-wild speech data. This dataset comprises over 101k hours of speech across six languages: English, Chinese, German, French, Japanese, and Korean. Besides, we expand Emilia to Emilia-Large, a dataset exceeding 216k hours, making it the largest open-source speech generation dataset available. Extensive experiments demonstrate that Emilia significantly outperforms traditional audiobook datasets in generating spontaneous and human-like speech, showcasing superior performance in capturing diverse speaker timbre and speaking styles of real-world human speech. Furthermore, this work underscores the importance of scaling dataset size to advance speech generation research and validates the effectiveness of Emilia for both multilingual and crosslingual speech generation.
DiffGraph: Heterogeneous Graph Diffusion Model
Jan 04, 2025



Recent advances in Graph Neural Networks (GNNs) have revolutionized graph-structured data modeling, yet traditional GNNs struggle with complex heterogeneous structures prevalent in real-world scenarios. Despite progress in handling heterogeneous interactions, two fundamental challenges persist: noisy data significantly compromising embedding quality and learning performance, and existing methods' inability to capture intricate semantic transitions among heterogeneous relations, which impacts downstream predictions. To address these fundamental issues, we present the Heterogeneous Graph Diffusion Model (DiffGraph), a pioneering framework that introduces an innovative cross-view denoising strategy. This advanced approach transforms auxiliary heterogeneous data into target semantic spaces, enabling precise distillation of task-relevant information. At its core, DiffGraph features a sophisticated latent heterogeneous graph diffusion mechanism, implementing a novel forward and backward diffusion process for superior noise management. This methodology achieves simultaneous heterogeneous graph denoising and cross-type transition, while significantly simplifying graph generation through its latent-space diffusion capabilities. Through rigorous experimental validation on both public and industrial datasets, we demonstrate that DiffGraph consistently surpasses existing methods in link prediction and node classification tasks, establishing new benchmarks for robustness and efficiency in heterogeneous graph processing. The model implementation is publicly available at: https://github.com/HKUDS/DiffGraph.
SF-Speech: Straightened Flow for Zero-Shot Voice Clone on Small-Scale Dataset
Oct 16, 2024



Large-scale speech generation models have achieved impressive performance in the zero-shot voice clone tasks relying on large-scale datasets. However, exploring how to achieve zero-shot voice clone with small-scale datasets is also essential. This paper proposes SF-Speech, a novel state-of-the-art voice clone model based on ordinary differential equations and contextual learning. Unlike the previous works, SF-Speech employs a multi-stage generation strategy to obtain the coarse acoustic feature and utilizes this feature to straighten the curved reverse trajectories caused by training the ordinary differential equation model with flow matching. In addition, we find the difference between the local correlations of different types of acoustic features and demonstrate the potential role of 2D convolution in modeling mel-spectrogram features. After training with less than 1000 hours of speech, SF-Speech significantly outperforms those methods based on global speaker embedding or autoregressive large language models. In particular, SF-Speech also shows a significant advantage over VoiceBox, the best-performing ordinary differential equation model, in speech intelligibility (a relative decrease of 22.4\% on word error rate) and timbre similarity (a relative improvement of 5.6\% on cosine distance) at a similar scale of parameters, and even keep a slight advantage when the parameters of VoiceBox are tripled.
Emilia: An Extensive, Multilingual, and Diverse Speech Dataset for Large-Scale Speech Generation
Jul 07, 2024



Recently, speech generation models have made significant progress by using large-scale training data. However, the research community struggle to produce highly spontaneous and human-like speech due to the lack of large-scale, diverse, and spontaneous speech data. This paper presents \textit{Emilia}, the first multilingual speech generation dataset from in-the-wild speech data, and Emilia-Pipe, the first open-source preprocessing pipeline designed to transform in-the-wild speech data into high-quality training data with annotations for speech generation. Emilia starts with over 101k hours of speech in six languages and features diverse speech with varied speaking styles. To facilitate the scale-up of Emilia, the open-source pipeline Emilia-Pipe can process one hour of raw speech data ready for model training in a few mins, which enables the research community to collaborate on large-scale speech generation research. Experimental results validate the effectiveness of Emilia. Demos are available at: https://emilia-dataset.github.io/Emilia-Demo-Page/.
The Impact of Silence on Speech Anti-Spoofing
Sep 21, 2023



The current speech anti-spoofing countermeasures (CMs) show excellent performance on specific datasets. However, removing the silence of test speech through Voice Activity Detection (VAD) can severely degrade performance. In this paper, the impact of silence on speech anti-spoofing is analyzed. First, the reasons for the impact are explored, including the proportion of silence duration and the content of silence. The proportion of silence duration in spoof speech generated by text-to-speech (TTS) algorithms is lower than that in bonafide speech. And the content of silence generated by different waveform generators varies compared to bonafide speech. Then the impact of silence on model prediction is explored. Even after retraining, the spoof speech generated by neural network based end-to-end TTS algorithms suffers a significant rise in error rates when the silence is removed. To demonstrate the reasons for the impact of silence on CMs, the attention distribution of a CM is visualized through class activation mapping (CAM). Furthermore, the implementation and analysis of the experiments masking silence or non-silence demonstrates the significance of the proportion of silence duration for detecting TTS and the importance of silence content for detecting voice conversion (VC). Based on the experimental results, improving the robustness of CMs against unknown spoofing attacks by masking silence is also proposed. Finally, the attacks on anti-spoofing CMs through concatenating silence, and the mitigation of VAD and silence attack through low-pass filtering are introduced.
Expressive paragraph text-to-speech synthesis with multi-step variational autoencoder
Sep 02, 2023



Neural networks have been able to generate high-quality single-sentence speech with substantial expressiveness. However, it remains a challenge concerning paragraph-level speech synthesis due to the need for coherent acoustic features while delivering fluctuating speech styles. Meanwhile, training these models directly on over-length speech leads to a deterioration in the quality of synthesis speech. To address these problems, we propose a high-quality and expressive paragraph speech synthesis system with a multi-step variational autoencoder. Specifically, we employ multi-step latent variables to capture speech information at different grammatical levels before utilizing these features in parallel to generate speech waveform. We also propose a three-step training method to improve the decoupling ability. Our model was trained on a single-speaker French audiobook corpus released at Blizzard Challenge 2023. Experimental results underscore the significant superiority of our system over baseline models.
The HCCL-DKU system for fake audio generation task of the 2022 ICASSP ADD Challenge
Jan 29, 2022The voice conversion task is to modify the speaker identity of continuous speech while preserving the linguistic content. Generally, the naturalness and similarity are two main metrics for evaluating the conversion quality, which has been improved significantly in recent years. This paper presents the HCCL-DKU entry for the fake audio generation task of the 2022 ICASSP ADD challenge. We propose a novel ppg-based voice conversion model that adopts a fully end-to-end structure. Experimental results show that the proposed method outperforms other conversion models, including Tacotron-based and Fastspeech-based models, on conversion quality and spoofing performance against anti-spoofing systems. In addition, we investigate several post-processing methods for better spoofing power. Finally, we achieve second place with a deception success rate of 0.916 in the ADD challenge.
Towards Explainable Inference about Object Motion using Qualitative Reasoning
Jul 28, 2018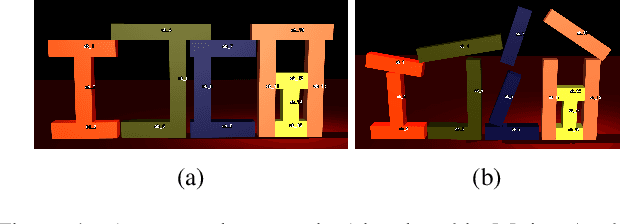
The capability of making explainable inferences regarding physical processes has long been desired. One fundamental physical process is object motion. Inferring what causes the motion of a group of objects can even be a challenging task for experts, e.g., in forensics science. Most of the work in the literature relies on physics simulation to draw such infer- ences. The simulation requires a precise model of the under- lying domain to work well and is essentially a black-box from which one can hardly obtain any useful explanation. By contrast, qualitative reasoning methods have the advan- tage in making transparent inferences with ambiguous infor- mation, which makes it suitable for this task. However, there has been no suitable qualitative theory proposed for object motion in three-dimensional space. In this paper, we take this challenge and develop a qualitative theory for the motion of rigid objects. Based on this theory, we develop a reasoning method to solve a very interesting problem: Assuming there are several objects that were initially at rest and now have started to move. We want to infer what action causes the movement of these objects.