 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmilia: A Large-Scale, Extensive, Multilingual, and Diverse Dataset for Speech Generation
Jan 27, 2025Recent advancements in speech generation have been driven by the large-scale training datasets. However, current models fall short of capturing the spontaneity and variability inherent in real-world human speech, due to their reliance on audiobook datasets limited to formal read-aloud speech styles. To bridge this gap, we introduce Emilia-Pipe, an open-source preprocessing pipeline to extract high-quality training data from valuable yet underexplored in-the-wild data that capture spontaneous human speech in real-world contexts. By leveraging Emilia-Pipe, we construct Emilia, the first multilingual speech generation dataset derived from in-the-wild speech data. This dataset comprises over 101k hours of speech across six languages: English, Chinese, German, French, Japanese, and Korean. Besides, we expand Emilia to Emilia-Large, a dataset exceeding 216k hours, making it the largest open-source speech generation dataset available. Extensive experiments demonstrate that Emilia significantly outperforms traditional audiobook datasets in generating spontaneous and human-like speech, showcasing superior performance in capturing diverse speaker timbre and speaking styles of real-world human speech. Furthermore, this work underscores the importance of scaling dataset size to advance speech generation research and validates the effectiveness of Emilia for both multilingual and crosslingual speech generation.
SF-Speech: Straightened Flow for Zero-Shot Voice Clone on Small-Scale Dataset
Oct 16, 2024



Large-scale speech generation models have achieved impressive performance in the zero-shot voice clone tasks relying on large-scale datasets. However, exploring how to achieve zero-shot voice clone with small-scale datasets is also essential. This paper proposes SF-Speech, a novel state-of-the-art voice clone model based on ordinary differential equations and contextual learning. Unlike the previous works, SF-Speech employs a multi-stage generation strategy to obtain the coarse acoustic feature and utilizes this feature to straighten the curved reverse trajectories caused by training the ordinary differential equation model with flow matching. In addition, we find the difference between the local correlations of different types of acoustic features and demonstrate the potential role of 2D convolution in modeling mel-spectrogram features. After training with less than 1000 hours of speech, SF-Speech significantly outperforms those methods based on global speaker embedding or autoregressive large language models. In particular, SF-Speech also shows a significant advantage over VoiceBox, the best-performing ordinary differential equation model, in speech intelligibility (a relative decrease of 22.4\% on word error rate) and timbre similarity (a relative improvement of 5.6\% on cosine distance) at a similar scale of parameters, and even keep a slight advantage when the parameters of VoiceBox are tripled.
Emilia: An Extensive, Multilingual, and Diverse Speech Dataset for Large-Scale Speech Generation
Jul 07, 2024



Recently, speech generation models have made significant progress by using large-scale training data. However, the research community struggle to produce highly spontaneous and human-like speech due to the lack of large-scale, diverse, and spontaneous speech data. This paper presents \textit{Emilia}, the first multilingual speech generation dataset from in-the-wild speech data, and Emilia-Pipe, the first open-source preprocessing pipeline designed to transform in-the-wild speech data into high-quality training data with annotations for speech generation. Emilia starts with over 101k hours of speech in six languages and features diverse speech with varied speaking styles. To facilitate the scale-up of Emilia, the open-source pipeline Emilia-Pipe can process one hour of raw speech data ready for model training in a few mins, which enables the research community to collaborate on large-scale speech generation research. Experimental results validate the effectiveness of Emilia. Demos are available at: https://emilia-dataset.github.io/Emilia-Demo-Page/.
Expressive paragraph text-to-speech synthesis with multi-step variational autoencoder
Sep 02, 2023



Neural networks have been able to generate high-quality single-sentence speech with substantial expressiveness. However, it remains a challenge concerning paragraph-level speech synthesis due to the need for coherent acoustic features while delivering fluctuating speech styles. Meanwhile, training these models directly on over-length speech leads to a deterioration in the quality of synthesis speech. To address these problems, we propose a high-quality and expressive paragraph speech synthesis system with a multi-step variational autoencoder. Specifically, we employ multi-step latent variables to capture speech information at different grammatical levels before utilizing these features in parallel to generate speech waveform. We also propose a three-step training method to improve the decoupling ability. Our model was trained on a single-speaker French audiobook corpus released at Blizzard Challenge 2023. Experimental results underscore the significant superiority of our system over baseline models.
Sequential Topological Representations for Predictive Models of Deformable Objects
Nov 23, 2020
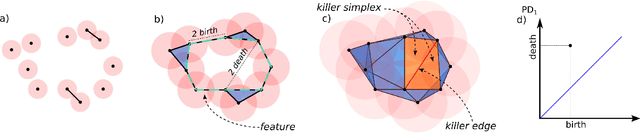

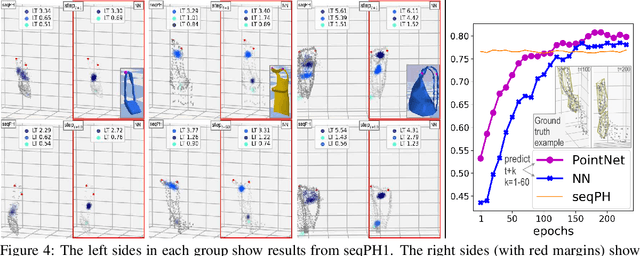
Deformable objects present a formidable challenge for robotic manipulation due to the lack of canonical low-dimensional representations and the difficulty of capturing, predicting, and controlling such objects. We construct compact topological representations to capture the state of highly deformable objects that are topologically nontrivial. We develop an approach that tracks the evolution of this topological state through time. Under several mild assumptions, we prove that the topology of the scene and its evolution can be recovered from point clouds representing the scene. Our further contribution is a method to learn predictive models that take a sequence of past point cloud observations as input and predict a sequence of topological states, conditioned on target/future control actions. Our experiments with highly deformable objects in simulation show that the proposed multistep predictive models yield more precise results than those obtained from computational topology libraries. These models can leverage patterns inferred across various objects and offer fast multistep predictions suitable for real-time applications.