 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
Omni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception
Oct 14, 2025Fine-grained perception of multimodal information is critical for advancing human-AI interaction. With recent progress in audio-visual technologies, Omni Language Models (OLMs), capable of processing audio and video signals in parallel, have emerged as a promising paradigm for achieving richer understanding and reasoning. However, their capacity to capture and describe fine-grained details remains limited explored. In this work, we present a systematic and comprehensive investigation of omni detailed perception from the perspectives of the data pipeline, models, and benchmark. We first identify an inherent "co-growth" between detail and hallucination in current OLMs. To address this, we propose Omni-Detective, an agentic data generation pipeline integrating tool-calling, to autonomously produce highly detailed yet minimally hallucinatory multimodal data. Based on the data generated with Omni-Detective, we train two captioning models: Audio-Captioner for audio-only detailed perception, and Omni-Captioner for audio-visual detailed perception. Under the cascade evaluation protocol, Audio-Captioner achieves the best performance on MMAU and MMAR among all open-source models, surpassing Gemini 2.5 Flash and delivering performance comparable to Gemini 2.5 Pro. On existing detailed captioning benchmarks, Omni-Captioner sets a new state-of-the-art on VDC and achieves the best trade-off between detail and hallucination on the video-SALMONN 2 testset. Given the absence of a dedicated benchmark for omni detailed perception, we design Omni-Cloze, a novel cloze-style evaluation for detailed audio, visual, and audio-visual captioning that ensures stable, efficient, and reliable assessment. Experimental results and analysis demonstrate the effectiveness of Omni-Detective in generating high-quality detailed captions, as well as the superiority of Omni-Cloze in evaluating such detailed captions.
Understanding DeepResearch via Reports
Oct 09, 2025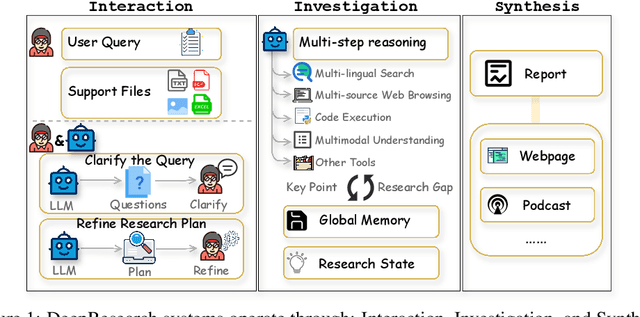

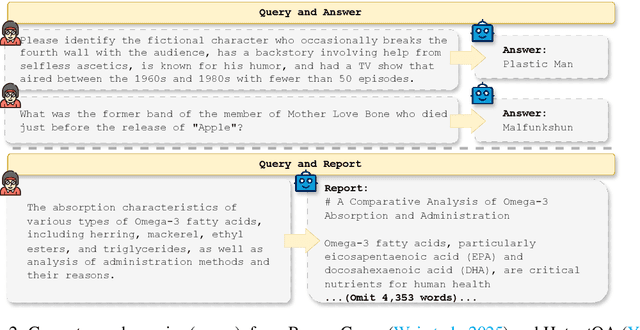

DeepResearch agents represent a transformative AI paradigm, conducting expert-level research through sophisticated reasoning and multi-tool integration. However, evaluating these systems remains critically challenging due to open-ended research scenarios and existing benchmarks that focus on isolated capabilities rather than holistic performance. Unlike traditional LLM tasks, DeepResearch systems must synthesize diverse sources, generate insights, and present coherent findings, which are capabilities that resist simple verification. To address this gap, we introduce DeepResearch-ReportEval, a comprehensive framework designed to assess DeepResearch systems through their most representative outputs: research reports. Our approach systematically measures three dimensions: quality, redundancy, and factuality, using an innovative LLM-as-a-Judge methodology achieving strong expert concordance. We contribute a standardized benchmark of 100 curated queries spanning 12 real-world categories, enabling systematic capability comparison. Our evaluation of four leading commercial systems reveals distinct design philosophies and performance trade-offs, establishing foundational insights as DeepResearch evolves from information assistants toward intelligent research partners. Source code and data are available at: https://github.com/HKUDS/DeepResearch-Eval.
A$^2$Search: Ambiguity-Aware Question Answering with Reinforcement Learning
Oct 09, 2025



Recent advances in Large Language Models (LLMs) and Reinforcement Learning (RL) have led to strong performance in open-domain question answering (QA). However, existing models still struggle with questions that admit multiple valid answers. Standard QA benchmarks, which typically assume a single gold answer, overlook this reality and thus produce inappropriate training signals. Existing attempts to handle ambiguity often rely on costly manual annotation, which is difficult to scale to multi-hop datasets such as HotpotQA and MuSiQue. In this paper, we present A$^2$Search, an annotation-free, end-to-end training framework to recognize and handle ambiguity. At its core is an automated pipeline that detects ambiguous questions and gathers alternative answers via trajectory sampling and evidence verification. The model is then optimized with RL using a carefully designed $\mathrm{AnsF1}$ reward, which naturally accommodates multiple answers. Experiments on eight open-domain QA benchmarks demonstrate that A$^2$Search achieves new state-of-the-art performance. With only a single rollout, A$^2$Search-7B yields an average $\mathrm{AnsF1}@1$ score of $48.4\%$ across four multi-hop benchmarks, outperforming all strong baselines, including the substantially larger ReSearch-32B ($46.2\%$). Extensive analyses further show that A$^2$Search resolves ambiguity and generalizes across benchmarks, highlighting that embracing ambiguity is essential for building more reliable QA systems. Our code, data, and model weights can be found at https://github.com/zfj1998/A2Search
IFEvalCode: Controlled Code Generation
Jul 30, 2025Code large language models (Code LLMs) have made significant progress in code generation by translating natural language descriptions into functional code; however, real-world applications often demand stricter adherence to detailed requirements such as coding style, line count, and structural constraints, beyond mere correctness. To address this, the paper introduces forward and backward constraints generation to improve the instruction-following capabilities of Code LLMs in controlled code generation, ensuring outputs align more closely with human-defined guidelines. The authors further present IFEvalCode, a multilingual benchmark comprising 1.6K test samples across seven programming languages (Python, Java, JavaScript, TypeScript, Shell, C++, and C#), with each sample featuring both Chinese and English queries. Unlike existing benchmarks, IFEvalCode decouples evaluation into two metrics: correctness (Corr.) and instruction-following (Instr.), enabling a more nuanced assessment. Experiments on over 40 LLMs reveal that closed-source models outperform open-source ones in controllable code generation and highlight a significant gap between the models' ability to generate correct code versus code that precisely follows instructions.
RMTBench: Benchmarking LLMs Through Multi-Turn User-Centric Role-Playing
Jul 27, 2025Recent advancements in Large Language Models (LLMs) have shown outstanding potential for role-playing applications. Evaluating these capabilities is becoming crucial yet remains challenging. Existing benchmarks mostly adopt a \textbf{character-centric} approach, simplify user-character interactions to isolated Q&A tasks, and fail to reflect real-world applications. To address this limitation, we introduce RMTBench, a comprehensive \textbf{user-centric} bilingual role-playing benchmark featuring 80 diverse characters and over 8,000 dialogue rounds. RMTBench includes custom characters with detailed backgrounds and abstract characters defined by simple traits, enabling evaluation across various user scenarios. Our benchmark constructs dialogues based on explicit user motivations rather than character descriptions, ensuring alignment with practical user applications. Furthermore, we construct an authentic multi-turn dialogue simulation mechanism. With carefully selected evaluation dimensions and LLM-based scoring, this mechanism captures the complex intention of conversations between the user and the character. By shifting focus from character background to user intention fulfillment, RMTBench bridges the gap between academic evaluation and practical deployment requirements, offering a more effective framework for assessing role-playing capabilities in LLMs. All code and datasets will be released soon.
Group Sequence Policy Optimization
Jul 24, 2025


This paper introduces Group Sequence Policy Optimization (GSPO), our stable, efficient, and performant reinforcement learning algorithm for training large language models. Unlike previous algorithms that adopt token-level importance ratios, GSPO defines the importance ratio based on sequence likelihood and performs sequence-level clipping, rewarding, and optimization. We demonstrate that GSPO achieves superior training efficiency and performance compared to the GRPO algorithm, notably stabilizes Mixture-of-Experts (MoE) RL training, and has the potential for simplifying the design of RL infrastructure. These merits of GSPO have contributed to the remarkable improvements in the latest Qwen3 models.
Teaching LLM to Reason: Reinforcement Learning from Algorithmic Problems without Code
Jul 10, 2025
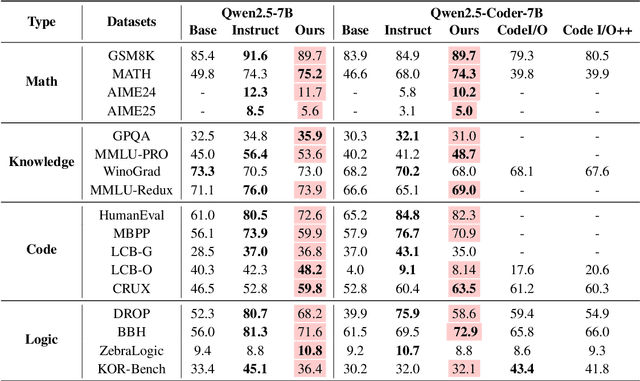

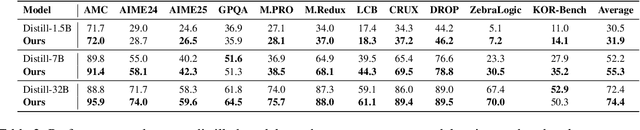
Enhancing reasoning capabilities remains a central focus in the LLM reasearch community. A promising direction involves requiring models to simulate code execution step-by-step to derive outputs for given inputs. However, as code is often designed for large-scale systems, direct application leads to over-reliance on complex data structures and algorithms, even for simple cases, resulting in overfitting to algorithmic patterns rather than core reasoning structures. To address this, we propose TeaR, which aims at teaching LLMs to reason better. TeaR leverages careful data curation and reinforcement learning to guide models in discovering optimal reasoning paths through code-related tasks, thereby improving general reasoning abilities. We conduct extensive experiments using two base models and three long-CoT distillation models, with model sizes ranging from 1.5 billion to 32 billion parameters, and across 17 benchmarks spanning Math, Knowledge, Code, and Logical Reasoning. The results consistently show significant performance improvements. Notably, TeaR achieves a 35.9% improvement on Qwen2.5-7B and 5.9% on R1-Distilled-7B.
CoRT: Code-integrated Reasoning within Thinking
Jun 12, 2025Large Reasoning Models (LRMs) like o1 and DeepSeek-R1 have shown remarkable progress in natural language reasoning with long chain-of-thought (CoT), yet they remain inefficient or inaccurate when handling complex mathematical operations. Addressing these limitations through computational tools (e.g., computation libraries and symbolic solvers) is promising, but it introduces a technical challenge: Code Interpreter (CI) brings external knowledge beyond the model's internal text representations, thus the direct combination is not efficient. This paper introduces CoRT, a post-training framework for teaching LRMs to leverage CI effectively and efficiently. As a first step, we address the data scarcity issue by synthesizing code-integrated reasoning data through Hint-Engineering, which strategically inserts different hints at appropriate positions to optimize LRM-CI interaction. We manually create 30 high-quality samples, upon which we post-train models ranging from 1.5B to 32B parameters, with supervised fine-tuning, rejection fine-tuning and reinforcement learning. Our experimental results demonstrate that Hint-Engineering models achieve 4\% and 8\% absolute improvements on DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Qwen-1.5B respectively, across five challenging mathematical reasoning datasets. Furthermore, Hint-Engineering models use about 30\% fewer tokens for the 32B model and 50\% fewer tokens for the 1.5B model compared with the natural language models. The models and code are available at https://github.com/ChengpengLi1003/CoRT.
SWE-Flow: Synthesizing Software Engineering Data in a Test-Driven Manner
Jun 11, 2025We introduce **SWE-Flow**, a novel data synthesis framework grounded in Test-Driven Development (TDD). Unlike existing software engineering data that rely on human-submitted issues, **SWE-Flow** automatically infers incremental development steps directly from unit tests, which inherently encapsulate high-level requirements. The core of **SWE-Flow** is the construction of a Runtime Dependency Graph (RDG), which precisely captures function interactions, enabling the generation of a structured, step-by-step *development schedule*. At each step, **SWE-Flow** produces a partial codebase, the corresponding unit tests, and the necessary code modifications, resulting in fully verifiable TDD tasks. With this approach, we generated 16,061 training instances and 2,020 test instances from real-world GitHub projects, creating the **SWE-Flow-Eval** benchmark. Our experiments show that fine-tuning open model on this dataset significantly improves performance in TDD-based coding. To facilitate further research, we release all code, datasets, models, and Docker images at [Github](https://github.com/Hambaobao/SWE-Flow).